
Datenqualität bereinigen durch Machine Learning
Neue, wirksamere Wege zum Vermeiden von Bad Response Effekten, Sampling-Bias, und schwankenden KPI’s.
Manche Befragte klicken sich in Windeseile, manche erratisch durch den Fragebogen. Die Stichprobe einer Befragung ist oft weit weg von einer Zufallsauswahl. Übermäßig Quotierung verschärft das Problem statt zu lösen. Interne Auftraggeber fragen sich des Öfteren, warum ein NPS (oder andere KPI‘s) gefallen oder gestiegen ist und finden keine sinnvolle Begründung. Zweifel in die Datenqualität kann das Vertrauen in eine ganze Studie zu nicht machen. Doch es gibt neue Wege dem zu entgegnen.
Das Beispiel Bad Response Effekte
Viele Marktforscher haben ihre eigenen „praktischen“ Regeln entwickeln, dem zu entgegnen. Zu kurze Befragungszeiten oder zu viele Zustimmungen führen zum Ausschluss eines Befragten. Es werden auch gelegentlich Testfragen eingeführt, um zu prüfen ob ein Befragter „aufpasst“.
Das Problem: Was genau ist die richtige Befragungszeit bei der ein Fall ausgesondert werden sollte? Bei welcher Zustimmungsquote unterscheidet sich ein Fan von einem unehrlichen Befragten? Was genau sagt die Testfrage wirklich über das Befragungsverhalten der Person?
Die Antwort auf diese Frage ist unbekannt und ist mit herkömmlichen Mitteln kaum aus den Daten zu beantworten.
Selbstlernende Analysemethoden – auch unter dem Trendwort „Machine Learning“ bekannt, bieten die Möglichkeit unbekannte, komplexe Zusammenhänge zwischen Indikatoren und ihren Auswirkungen aus Daten zu erlernen.
Bad Response Indikatoren sind etwa die Interview-Dauer, die Antwort auf eine Trick/Konsistenzfrage oder die Anzahl gleicher Antworten hintereinander u.v.m. Der Trick versucht nun nicht mehr eine Bedeutung (= Einfluss) dieser Indikatoren auf die Ergebnisse (willkürlich) anzunehmen, sondern den kausalen Einfluss aus den Daten herauszulesen. Dies ist mit Machine-Learning-basierenden Ursache-Wirkungsanalysen (insb. NEUSREL) möglich. Die Analyse ergibt beispielsweise folgende Ergebnisse. In dem Plot sieht man, dass die Kundenzufriedenheit extrem für Interviewlängen untern einer bestimmten Minutenzahl in die Höhe schießen (Skala ist hier auf 100 normiert).
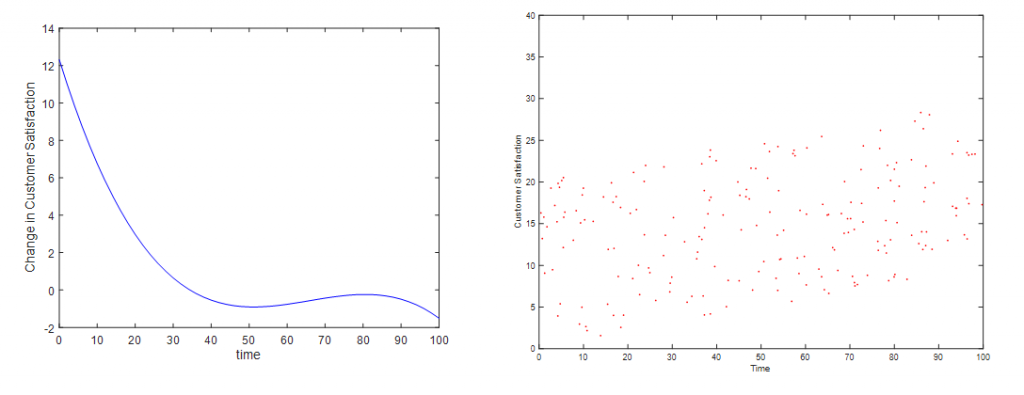
Das ermöglicht es uns sinnvolle Entscheidungsregeln abzuleiten. Daneben sehen Sie einen Scatterplot der gleichen Variablen und sehen einen anderen Zusammenhang. Eventuell sind die Speeder jüngere Menschen, die perse unzufriedener mit dem Anbieter sind. Das Machine Learning liefert also kausal bereinigte Erkenntnisse statt die üblichen Scheinkorrelationen.
Werden die Daten für eine Treiberanalyse verwendet, empfiehlt es sich sogar die suspekten Fälle gar nicht auszusondern. Dadurch dass die Bad Responses durch die Indikatorvariablen gut beschrieben sind, rechnet eine Machine-Learning-basierte Treiberanalyse (insb. NEUSREL) die Bad Response-Effekte einfach raus. Das Aussondieren von Fälle würde mit Verfälschungseffekte einhergehen, die nicht nachprüfbar sind.
Das Beispiel Sampling-Bias
Stichprobenverzerrungen treten beispielsweise durch sich nicht-zufällig unterscheidende Teilnahmebereitschaften der Probanden auf. Indem Sie Indikatoren für diese Teilnehmerbereitschaft messen –etwas Alter, Geschlecht, Einkommen oder auch „Mitteilungsdrang“- können Machine-Learning-basierte Ursache-Wirkungsanalysen den Zusammenhang zwischen Indikator und Antwortverhalten bestimmen. Wenn Sie nun beispielsweise zu wenige Senioren im Sample haben, kennen Sie nun genau die Verzerrung dadurch auf jede Frage und können Sie korrigieren.
Für die Verwendung der Daten in Treiberanalysen genügt es gute Indikatoren für den Sampling-Bias Teil des Treibermodells zu machen, denn dieses rechnet alle Bias-Effekte automatisch heraus. Dies erlauben jedoch nur Machine-Learning-basierte Treiberanalyse (insb. NEUSREL). Somit wird eine zu starke Quotierung vermieden, die selbst neue Quotierungs-Bias erzeugen.
Das Beispiel Schwankende KPI‘s
Wenn Werte von KPI’s wie NPS, TRIM, etc. sich unerklärbar von Welle zu Welle ändern, kann das zwei Ursachen haben:
- Eine oder mehrere zentrale Ursache des Treibers hat/haben sich geändert. Dem kann man nur dann auf den Grund gehen, wenn man mit Treiberanalysen verstehen lernt, was wirklich das KPI treibt.
- Die beschriebenen Verzerrungen wie etwas Bad Response oder Sampling Bias haben sich zwischen den Wellen geändert. Etwas mehr Senioren, etwas mehr Männer, etwas weniger Probanden mit „Mitteilungsdrang“ – es gibt viele Ursachen dafür. Diese können einzig und allein dadurch kontrolliert werden, dass wir wie oben beschrieben Indikatoren für Verzerrungen mit messen.
Um den wahren unverzerrten KPI Wert über alle Befragten zu ermitteln, benötigt man ein Treibermodel, dass möglichst präzise den KPI anhand der Treiber, der Kontextvariablen und der Indikatoren für Verzerrungen vorhersagen können. Verfahren wie NEUSREL sind universell einsetzbar egal wie die Variablen verteilt sind oder Nichtlinearitäten in sich tragen. In der Regel erzielen sie zudem 20-80% höhere Erklärungsgüte als herkömmliche lineare Modelle.
Das Treibermodell wird dann zur Simulation genutzt. Ändert man die Werte der Indikatorvariablen so, dass der Standardmittelwert entsteht, dann liefert das Treibermodel Schätzwerte für jeden Befragten, die dann aggregiert den korrigierte KPI ergibt.
Fazit
Machine-Learning-basierte Ursache-Wirkungsanalysen bieten neue Möglichkeiten Datenqualität zu verbessern. Sie führen zu einer konsistenten objektiven Behandlung von Bad Response und Sampling-Bias. Sie führen zu plausibleren, weniger erratischen Änderungen von KPI’s zwischen Wellen und einen nachprüfbaren Qualitätscheck der Feldorganisation. Als schönen „Nebeneffekt“ erhält man durch das Modeling ein Verständnis für Erkenntnisse die sie ohne dem nicht hätte: Einblicke in die kausalen Zusammenhänge ZWISCHEN den Daten – Aussagen darüber, welche Bedeutung Marketingaktionen oder Kundeneinstellungen besitzen. Die selbstlernende NEUSREL-Treiberanalyse macht‘s möglich.
p.s. Weiterführendes zu NEUSREL und die Universelle Strukturmodelierung finden Sie hier.