BrandGrowth.AI: Eine erprobte, evidenzbasierte Strategie für mehr Wachstum Ihrer Marke
In den letzten Jahren lieferte Neuroscience den wissenschaftlichen Beweis. Das Ergebnis menschlicher Entscheidungen ist im Gehirn bereits ein bis sieben Sekunden, bevor es dem Menschen bewusst wird, nachweisbar. Gut 90% unserer Entscheidungen kann durch unbewusste Emotionen, Einstellungen und Instinkten erklärt werden. Doch noch immer fokussieren die meisten Werbeanzeigen etwaigen Produktnutzen und sonstige USP‘s. Die Folgen sind weitreichend.
Konsumenten treffen wöchentlich tausende Wahlentscheidungen und sind tausenden Werbekontakten ausgesetzt. Es ist weder praktisch möglich noch für Menschen relevant, all diese zu verarbeiten und zu verstehen oder gar „eine Beziehung“ mit einer relevanten Anzahl an Marken davon einzugehen.
Die vor Jahrzehnten entwickelten wissenschaftlichen Modelle von Ehrenberg und Bass gehen von einem anderen Konsumentenbild aus – mit Erfolg. Sie sagen das Konsumentenverhalten und damit die Marktstruktur sehr präzise vorher. Große empirische Studien haben in den letzten Jahrzehnten dies in den hunderten Produktkategorien kulturübergreifend bestätigt.
Ehrenberg und Bass: Ein Meilenstein in der Marketingforschung
In seinem Buch “How Brands Groth” hat Byron Sharp – der aktuelle Director des Ehrenberg-Bass Institutes- anhand überreifender empirischer Studien dargelegt, welche weitreichenden Folgen das neue Konsumentenverständnis für praktische Marketingstrategien besitzt.
Er beweist, dass der Fokus auf dem Gewinnen neuer Kunden effektiver ist, als der des Bindens Bestehender. Cola Cola macht mehr als 50% seines Umsatzes mit Kunden, die nur 2 bis 3 mal im Jahr Coke kaufen. So gut wie jede Marke macht einen relevanten Umsatzanteil mit vielen, wenig gebundenen Kunden – dem „Long-Tail“. Hier liegt ein enormes Wachstumspotential.
Sharp belegt empirisch auch, dass Positionierung auf Basis emotionaler Differenzierung überschätzt ist und zeigt, dass es beim Branding, um viel grundlegendere Dinge geht. Es geht darum
- Prägnant wahrgenommen und verankert zu sein, um im Moment der Entscheidung in die Auswahl zu gelangen,
- Durch Wecken der richtigen Emotionen dafür zu sorgen, dass Werbeinhalte verarbeitet werden und es geht darum
- Konsistent zu bleiben, damit das Markenbild über die Zeit gestärkt statt verwässert wird.
Als drittes weist Sharp nach, dass es darauf ankommt in jeder Hinsicht die Marke „verfügbar“ zu halten, um das volle Potential auszuschöpfen. „Make it Easy to Buy“ heißt das Motto. Das beinhaltet nicht nur die Verbreitung im Handel für FMCG-Produkte, sondern auch deren Sichtbarkeit dort oder dem Vermeiden von diversen z.T. im Nachhinein trivial wirkenden Kaufhindernissen.
BrandGrowth.AI: Success Drivers’ Lösung für mehr Wachstum Ihrer Marke
Wir haben unsere erprobten Analytics-Lösung im Wachstumspaket „BrandGrowth.AI“ zusammengestellt. Es beinhaltet die zentralen Schritte, die wir im Markt existierenden Marken empfehlen, um ihre Position langfristig zu stärken und Wachstum zu generieren.
1. Be Broad – Bearbeiten Sie ein möglichst großes Potential
Schritt 1 – Define your playground
Ist Head&Shoulders ein Shampoo oder ein Männer-Anti-Schuppen-Shampoo? Die Marke wird von Männern und Frauen gekauft, die zudem zu großem Teil keine relevanten Schuppenprobleme haben. Mit selektivem Targeting wäre die Marke nicht die weltweit meistverkaufte Shampoo-Marke. Doch wie findet man das richtige Ausmaß, die geeignete Definition des „Spielfelds“? Genau dafür gibt es Methoden wie die Überschneidungsanalyse, die hier helfen.
Wenn sie glauben ihre Marke besitzt einen echten USP, dann wäre dies ein Anlass darüber nachzudenken, das Kategorie-Verständnis zu erweitern oder zu wechseln. Warum? Rationale Entscheidungsprozesse sind eher bei der Auswahl der Produktkategorie und weniger in der Auswahl von Marken zu finden.
Schritt 2 – Finden Sie ihr Set an Category Entry Points
Sie fahren mit Ihrem Auto an einem McDonalds vorbei, haben aber noch nicht gefrühstückt. Wenn die Marke nicht bei Ihnen als Frühstücksoption abgespeichert ist, so fahren sie in der Regel einfach weiter ohne zu bemerken, dass es eine Option gewesen wäre. Haben Sie sich schon einmal gefragt, warum Tomatensaft fast ausschließlich im Flugzeug getrunken wird? Das Flugzeug ist (aus unbekannten Gründen) ein zentraler Category Entry Point (CEP) für Tomatensaft.
Marken wachsen wenn sie mit einer steigeneden Anzahl an CEPs assoziiert werden. Wir identifizieren qualitativ für sie potentielle CEPs, messen deren Bedeutung mit impliziten Messmethoden und stellen fest, inwieweit ihre Marke heute bereits mit dem CEP assoziiert wird?
Schritt 3 – Category.AI – Find your category drivers
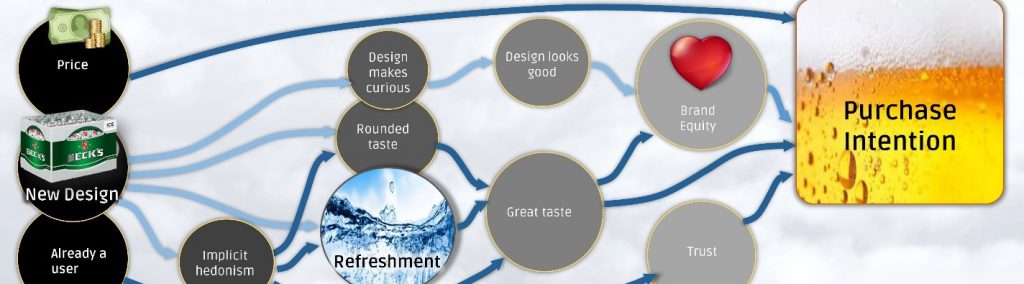
Für die Käufer einer Kategorie gilt es den kleinsten gemeinsamen Nenner zu finden, der es ermöglicht so viele Käufer wie möglich zu überzeugen. Unsere AI-basierte Treiberanalyse deckt die zentralen Hebel jeder Produktkategorie mit Hilfe einfacher Markenbefragungen auf.
Hier finden wir, dass der zentrale Treiber für die Bier-Kategorie, dass Erfrischungserlebnis ist. Wir entdecken, dass in der Kategorie Hautreinigung der Duft, als zentraler Kaufindikator fungiert. Wir weisen nach, dass eine Bank sich in aller erster Linie um ihre Kompetenzreputation im Bereich Finanzierung und Anlage kümmern sollte.
Diese Kerntreiber sind der Leuchtturm für ihr Marketing. Zu weilen wirkt es zu trivial, dass ein Bier erfrischt, ein Shampoo gut riecht und eine Bank gut berät. Es ist daher oft die Regel statt die Ausnahme, dass Marken sich von diesem Leuchtturm zu weit entfernen.
Diese Fallstudie am Beispiel der Marke SONOS illustriert das Vorgehen.
2. Build Brand – Maximieren Sie die “mentale Verfügbarkeit”
Markenbildung hat zum Ziel, die mentale Verfügbarkeit zu stärken, indem es Gedächtnisstrukturen im Zusammenhang mit der Marke stärkt. Dies erreichen Verantwortliche durch einzigartige Markenelemente (Logo, Farben, Figuren, Melodien, Geschichten und Assoziationen), die konstant über Jahre und Jahrzehnte verwendet werden. Diese Verankerung gelingt jedoch erst dann, wenn es gelingt mit Werbeinhalten emotional zu involvieren – oder wenn die Marke in emotional involvierenden Kontexten gezeigt wird (Stichwort Sponsoring).
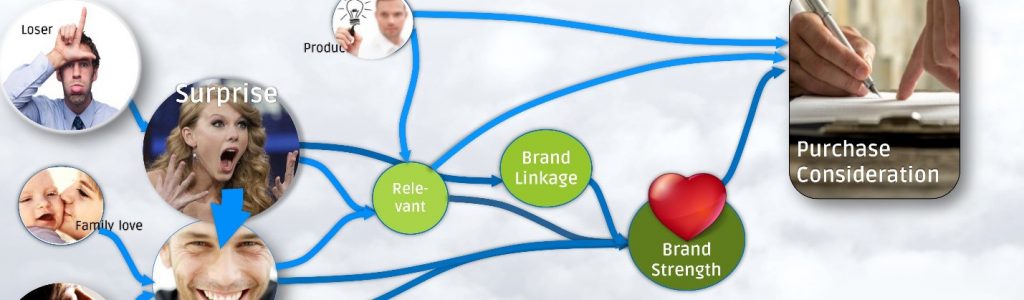
Schritt 4 – Creative.AI – Identify the DNA of successful advertising:
Unsere Lösung Creative.AI ist daraus ausgerichtet herauszufinden, welche emotionalen Archetypen und Kreativtechniken in der Lage sind emotional positiv zu involvieren und damit eine tiefere Verankerung der Markenelemente zu bewirken. Mehr über Creative.AI finden Sie hier
Viele großangelegte Studien belegen, dass mindestens 70% des Effektes von Werbung davon abhängt, wie gut diese gemacht ist. Der evidenzbasierten Optimierung kreativer Inhalte kommt daher eine entscheidende Bedeutung zu.
Erst wenn dieser Schritt vollzogen wurde, ergibt es Sinn die Verteilung von Marketingbudgets genauer zu optimieren:
Schritt 5 – Media.AI – Mediaplanung mit maximaler Reichweite
Nach aktuellem Stand der Forschung liefert der erste Werbekontakt den höchsten ROI, sodass wiederholte Kontakte nur dann sinnvoll sind, wenn sich keine alternative Zielgruppen finden, die ähnlich gut reagieren. Wie Sharp nachwies zeigt Werbung gerade bei Gelegenheitskäufern (long tail) die größte Hebelwirkung, nicht unbedingt in der „Kernzielgruppe“.
Demnach zielt gute Mediaplanung weniger auf trennscharfes Targeting, sondern darauf, kostenminimal Reichweite unter den potentiellen Käufern der Kategorie zu erzielen. Media.AI erhebt (stichprobenartig) die individuellen Medianutzungsprofile der Kategorie-Käufer und findet mit Optimierungsalgorithmen der Künstlichen Intelligenz, die reichweitenmaximale Kombinationen von Medienkanälen, -typen und Schaltzeiten bei bestehendem Budget.
Schritt 6 – Mix.AI – Mix Modeling im digitalen Zeitalter
Marketing Mix Modeling ist eine etablierte Methode. Sie bedarf jedoch einem Update. Im digitalen Zeitalter bedingen sich Kanäle immer mehr. Ein TV-Spot generiert Adword Klicks – ein indirekter Effekt dem Rechnung getragen werden muss. AI-basierte Treiberanalysen bilden nicht nur diese indirekten Beziehungen ab, sondern finden ebenfalls verborgene Verbund- d.h. Interaktionseffekte zwischen Kanälen. Mehr zu unserem MMM-Ansatz.
Schritt 7 – SLC-Brand Tracker: Die 3 zentralen KPIs immer im Blick
Brand Tracker messen heute vor allem das Brand Image, um zu überprüfen, ob die Marke noch definitionsgemäß wahrgenommen wird. Viel entscheidender ist es jedoch zu tracken, wie prägnant, „likable“ und kontinuierlich die Markenführung ist:
- Prägnanz (Brand Salience): Sie misst wie viele Ankerpunkte, die Marke besetzt um erinnert und im Bedarfszeitpunkt abgerufen zu werden. Um die Prägnanz einer Marke optimal zu messen, muss ein eigenes Messinstrument entwickelt werden, dass alle Marken-„Cues“ abtestet.
- Sympathie: Ist die Marke positiv besetzt und wird sie mit dem Grundnutzen der Kategorie assoziiert?
- Kontinuität: Setzt die Markenkommunikation an existierenden Gedächtnismustern an oder verwässert sie indem sie Neue aufbaut?
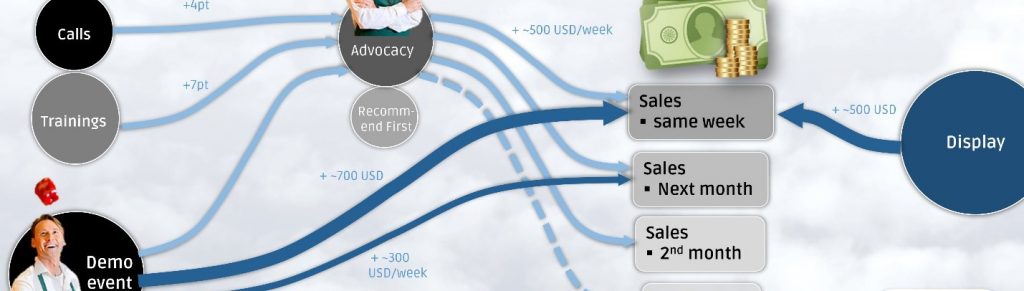
3. Reach out – Maximieren Sie die “physische Verfügbarkeit”
Wir verstehen unter “physischer Verfügbarkeit”, dass die Marke im Bedarfszeitpunkt im Wahrnehmungsfeld des Konsumenten ist und dabei gewisse Knock-Out-Kriterien erfüllt (z.B. gesuchte Packungsgröße, Preiskategorie, etc.). Der Verbreitungsgrad im Handel ist hier nur eine offensichtliche Komponente von vielen.
Schritt 8 – RNB.AI: Identifizieren Sie die Gründe NICHT zu kaufen
Marken deren scheinbare Erfolgsursachen die „Convinience“ ist, haben meist bestimmte Knock-Out-Kriterien eliminiert. Leuchtende Beispiele sind Paypal, Google Search oder das iPhone. Interessanterweise ist es für Marketingexperten im Vorhinein keineswegs offensichtlich was genau diese Kriterien sind. Es bedarf genauerer Nachforschung. Wir empfehlen hierfür einen zweistufigen Ansatz
- Qualitative Forschung: Tiefeninterviews, Fokusgruppen oder Communities
- Quantitative Exploration: Unser AI-basierte Treiberanalyse liest aus einer dafür durchgeführten quantitativen Befragung, welche Kriterien tatsächliche „Show-stopper“ sind.
Der Ansatz ist sowohl für eine aktuelle Produktkategorie am Markt als auch für Neuproduktkonzepte gedacht und erprobt.
Schritt 9 – Sales.AI: Maximieren sie die Schlagkraft am POS
Die Schlagkraft am POS lässt sich durch vielfältige Maßnahmen steigern: Displays, In-store Möbel, Demo-Events, Verkäufertrainings, Preis-Promotions, u.v.m.. Doch deren Wirksamkeit ist nicht unmittelbar in den Daten abzulesen. So haben einige Maßnahmen langfristige (Training) und andere kurzfristige (Preis-Promotions) Effekte. Sales.AI baut einen geeigneten Datensatz auf und bewertet den ROI dieser Verkaufsförderungsmaßnahmen.
Schritt 10 – Price.AI: Finden Sie Preispunkte die mehrheitsfähig sind und langfristig die Erträge maximieren
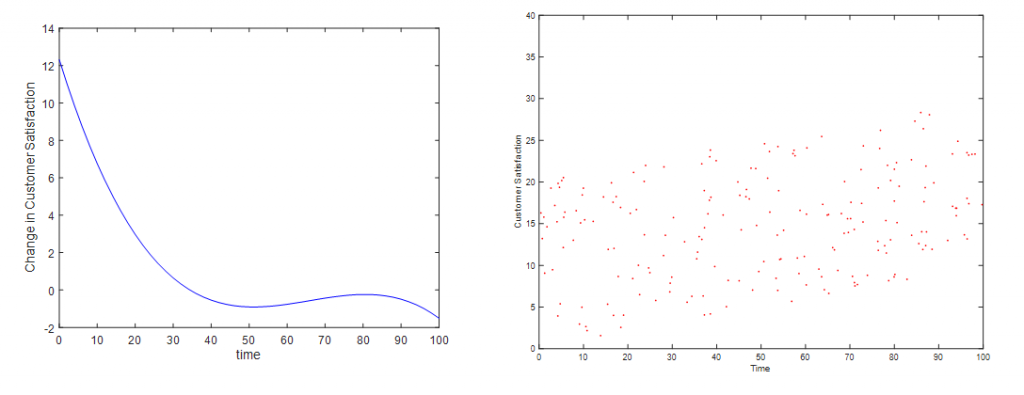
Ein zu tief angesetzter Preispunkt gefährdet das langfristige „Überleben“ eines Produkts – ein zu hoch angesetzter Preis reduziert die faktische Verfügbarkeit und verhindert, dass das volle Ertragspotential ausgeschöpft wird. Der Preis ist nicht nur der am einfachsten zu ändernde Marketingparameter, er ist bekanntermaßen auch der mit der größten Ertragswirkung.
Price.AI setzt auf einer impliziten Messung der Preisbereitschaft auf und modelliert Ursachen, Bedingungen und Stellhebel der Zahlungsbereitschaft. Dies ermöglicht ein valides Finden und Managen langfristig optimaler Preispunkte.
The BrandGrowth.AI Audit – Find out what works for you
BrandGrowth.AI ist eine Zusammenstellung von Tools die an den bedeutendsten Stellschrauben für Markenwachstum ansetzen. Sie liefert Fokus, höchste Validität und Durchblick im Dschungel methodischer Möglichkeiten.
Wir bieten Neukunden einen kostenfreien Audit-Workshop indem wir mit Ihnen individuell beleuchten, was für Sie konkret zu tun ist um Ihre Marke auf die nächste Ebene zu heben. Mit etwas Glück ergeht es Ihnen danach wie T-Mobile USA, die 4 Jahre nach der Durchführung von Category.AI ihren Marktanteil verdoppelten und heute Rekordgewinne einfahren.

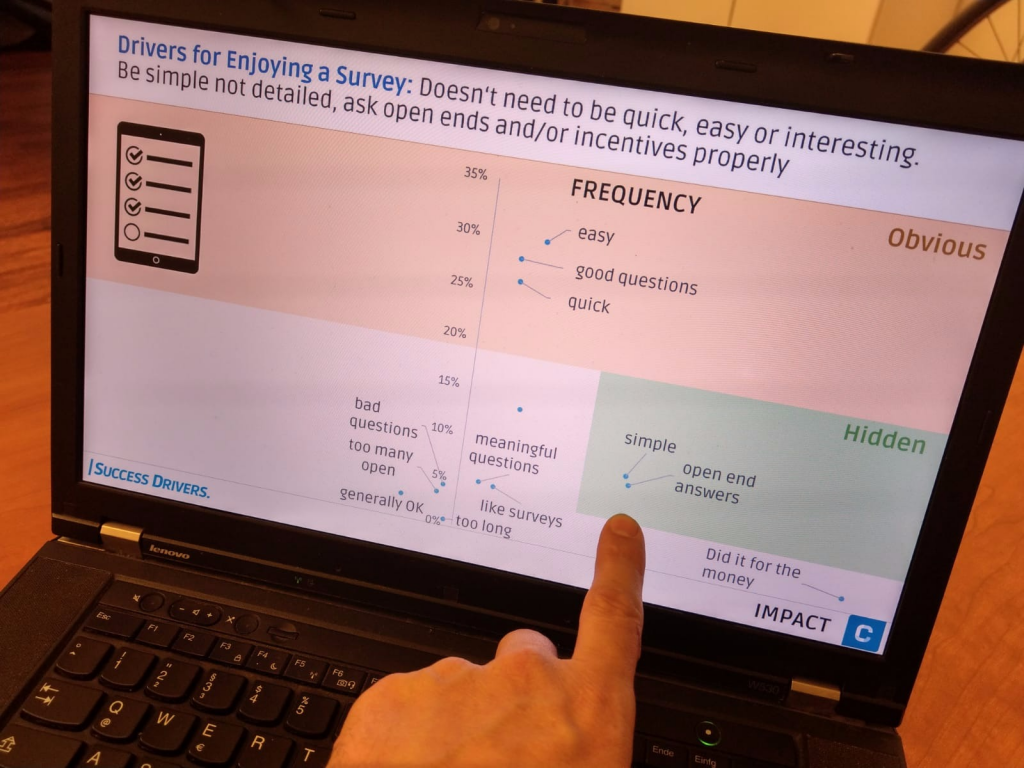
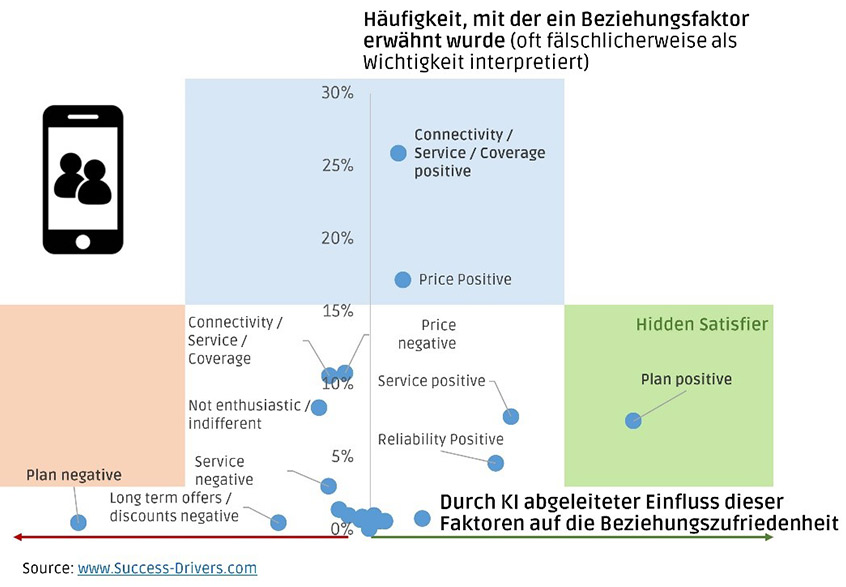
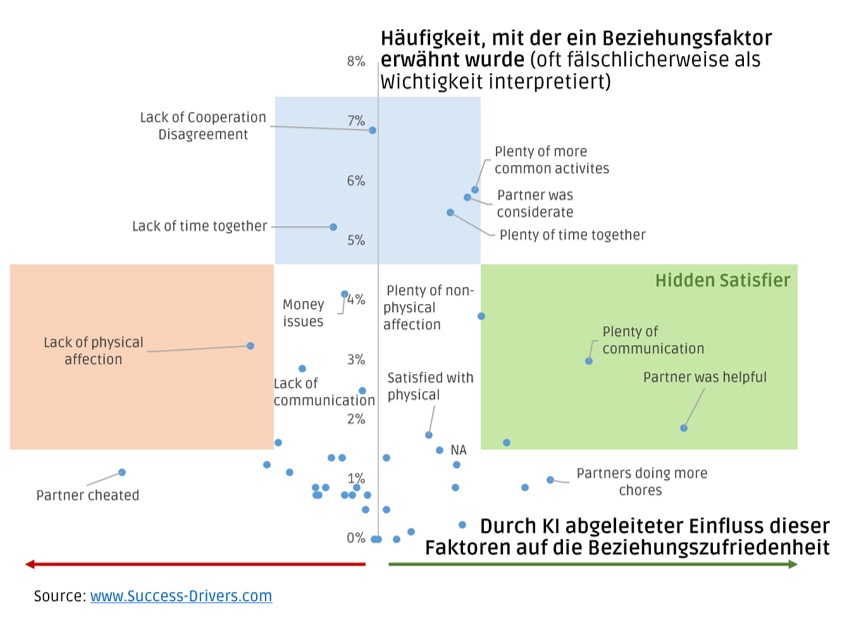

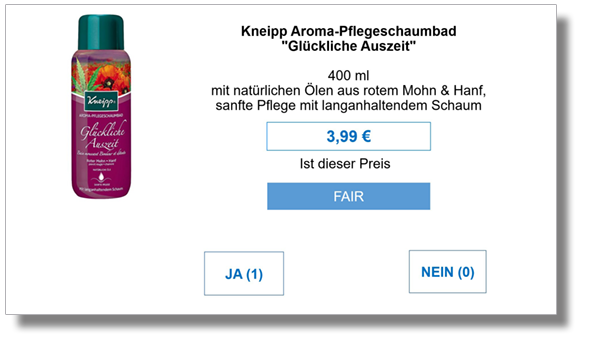
 Price.AI setzt in einer Online-Befragung von potentiellen Kunden eine sogenannte „Implizit-Befragung“ ein, um unbewusste Zahlungsbereitschaften zu messen. Dies ist der wissenschaftlich etablierte Weg, um unbewusste Assoziationen offen zu legen. Wir wenden dies auf die zu testende Preisrange (Default: 7 Preispunkte) an. Auf Basis einer 5-minütigen Online-Befragung errechnet unser Algorithmus eine validierte Preis-Absatz-Funktion und die gewinnmaximale Preisspanne.
Price.AI setzt in einer Online-Befragung von potentiellen Kunden eine sogenannte „Implizit-Befragung“ ein, um unbewusste Zahlungsbereitschaften zu messen. Dies ist der wissenschaftlich etablierte Weg, um unbewusste Assoziationen offen zu legen. Wir wenden dies auf die zu testende Preisrange (Default: 7 Preispunkte) an. Auf Basis einer 5-minütigen Online-Befragung errechnet unser Algorithmus eine validierte Preis-Absatz-Funktion und die gewinnmaximale Preisspanne.