
Frank Buckler
Das Ende der Kennzahlen-Illusion
Mehr Marge, mehr Absatz, mehr Effizienz –
durch einen digitalen Spürhund
Inhalt
Alltagswissen und andere Mythen
Mit richtigen Methoden Ursachen aufspüren
Digitale Spürhunde im Einsatz: Anwendungsfelder multivariater Ursachenanalysen
Einkauf und Personalmanagement
Strategische Unternehmensführung
Was macht einen guten digitalen Spürhund aus: Die Wahl der richtigen Methode
Wie Kolumbus sein: Entdecken können
Erkennen, was da ist: Komplexität entdecken können
Mit dem auskommen, was man hat: Mit kleinen Stichproben umgehen können
Universal Structure Modeling und die Software NEUSREL
Umsetzen: Die Befreiung aus der Kennzahlen-Illusion
KAPITEL 1
Alltagswissen und andere Mythen
Noch immer klingt mir die Mahnung meiner Mutter in den Ohren: „Junge, trink nicht so viel Kaffee! Das entwässert.“ Aber ich liebe doch Kaffee. So ein Mist!
Als ich zuletzt durch das abendliche TV-Programm zappe, bleibe ich bei Galileo hängen – eine Art Sendung mit der Maus für Erwachsene. Es geht um Kaffee und die als Allgemeinwissen verkleideten Scheinwahrheiten, die mir meine Mutter immer wieder mit auf den Weg gibt. Tatsächlich wirkt ein Stoff im Kaffee etwas entwässernd. Dieser Effekt ist jedoch minimal. Außerdem besteht eine Tasse Kaffee fast schließlich aus aromatisiertem Wasser. Diese Flüssigkeitsmenge überkompensiert bei Weitem den Wasserverlust, der durch die Kaffeepartikel ausgelöst wird.
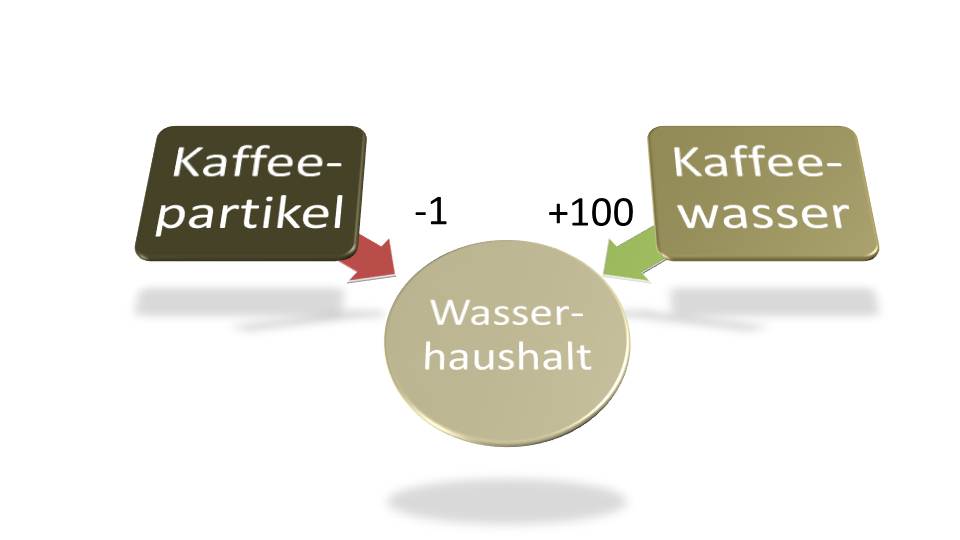
Witzig. Ich hatte es meiner Mutter geglaubt. Warum eigentlich? Ich habe doch schon tausendfach Kaffee getrunken und damit meine ganz persönliche Validierungsstudie durchgeführt. Mir war es nicht aufgefallen.
Nun sah ich endlich, warum meiner Mutter die Kaffeeschelte ein so großes Anliegen war. Als mein Vater noch arbeitete, bestand die Flüssigkeitszufuhr meines Vaters während der Arbeit fast ausschließlich aus Kaffee oder Tee. Die scheinbare Folge waren Wassermangel, häufige Kopfschmerzen, ein ständig trockener Mund und andere Dinge, die damit einhergingen. Als meine Mutter von der entwässernden Wirkung des Kaffees hörte, war der Schuldige dingfest gemacht. Der Kaffeekonsum wurde massiv reduziert, und stattdessen wurde Wasser getrunken. Das Problem schien gelöst, und eine Vermutung verfestigte sich zu Wissen.
Tatsächlich entwässert Kaffee nicht. Nur neigen manche Leute dazu, stundenlang kein Wasser zu sich zu nehmen, wenn Sie Kaffee trinken. Schon komisch, wie relativ einfaches, aber falsches Wissen von uns im Alltag nicht erkannt wird. Zum Glück passiert das nur im Privatleben – im Geschäftsleben sind ja Profis am Werk. Oder?
Damit aber nicht genug. Galileo lief an jenem Abend weiter und nahm einen weiteren Mythos meiner Jugend aufs Korn. Es ging um den Glauben, dass Kälte eine Erkältung auslöst. Alte Erinnerungen wurden wach: „Junge, föhn dir die Haare. Du holst dir sonst den Tod!“
Föhnen war uncool und ein absolutes No-go zu meiner Zeit. Ein weiterer Klassiker war die liebevoll gemeinte Mischung aus Anregung und Befehl: „Zieh den Schal an, Junge. Es ist kalt draußen!“ Auf meine Autonomie pochend, missachtete ich diesen Rat schon aus Prinzip. Denn ich entscheide bitteschön immer selbst, wann ich einen Schal anziehe!
Meistens ging es auch gut. Ich wurde nicht krank. Ein klarer Beweis, dass die Jugend oft schlauer ist als die weisen Erwachsenen. Oder? Meine Mutter sah das naturgemäß anders. Wenn ich trotzdem einmal krank wurde, lag es an meiner Nachlässigkeit beim Trockenrubbeln des Kopfes, beim Tragen meiner Mütze und beim Anlegen meines Schals. Andere Ursachen waren für sie ausgeschlossen.
Gespannt folgte ich der Sendung, die mir früher nur durch langweilige Banalitäten aufgefallen war. Warum machen nasse Haare im Frühlingswind nicht krank? Die Investigativ-Journalisten traten mit einem Experiment den Beweis an. Einige Freiwillige stellten sich eine Stunde lang in ein kaltes Wasserbad. Keiner davon wurde krank. Das ist erstaunlich. Denn wenn eines klar ist, dann dass Unterkühlung doch krank macht. Ist das aber wirklich so? Leider und zum Glück: nein. Einem gesunden Körper macht das absolut nichts aus!
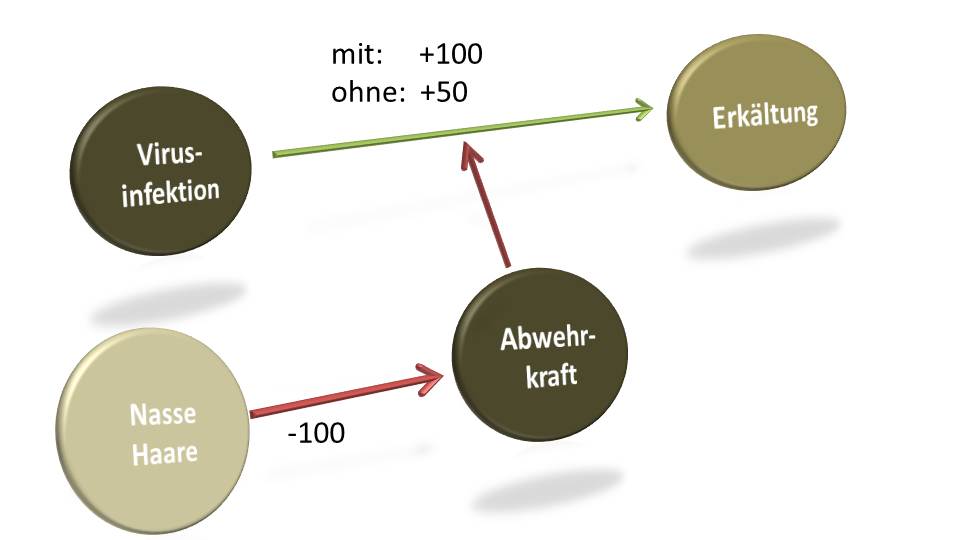
Dennoch enthält dieser Satz auch eine Einschränkung: „gesund“. Unterkühlung schwächt die Abwehrkräfte gegen viralen Befall. Haben wir uns mit Viren infiziert, so kommt unser Abwehrsystem oft damit zurecht und eliminiert die Eindringlinge, bevor sie sich zu stark vermehren. Kommen aber Kälte, Stress oder irgendwelche Gifte hinzu, ist die Wahrscheinlichkeit höher, dass wir uns einen Infekt zuziehen. Das ganze heißt dann zwar Erkältung, hat aber nur sehr bedingt etwas mit Kälte zu tun.
Viele werden nun einwenden: „Na ja, das Vermeiden von Kälte reduziert zumindest einen Risikofaktor. Daher ist die Empfehlung richtig.“ Natürlich schadet die Empfehlung nicht und verhindert in wenigen Fällen die Krankheit. Gegenüber der Anwendung richtigen Wissens jedoch verursacht die Empfehlung Einschränkungen und Umstände, die man im Geschäftskontext Kosten nennen würde. Wir kaufen Schal und Mütze, unter denen wir häufig unangenehm schwitzen, obwohl das Risiko einer Infektion extrem gering ist, wenn wir ansonsten gut auf uns achten. Vitaminreiche Ernährung, ausreichend Schlaf und Flüssigkeitszufuhr, Schutz der Schleimhäute vor Austrocknung und vieles mehr – wenn wir Dinge tun, die der Körper ohnehin gut gebrauchen kann, können wir uns das Wolldiktat sparen.
„Spannend“, denke ich mir: „Schon wieder hatte mich meine Mutter beschwindelt.“ Zugegeben, Sie wusste es nicht besser. Doch warum nicht? Derlei Dinge erleben wir im Schnitt sicher zwei- bis dreimal im Jahr. Man sollte doch in der Lage sein, aus eigenen Erfahrungen valides Wissen abzuleiten? Wahrscheinlich aber klappt das nicht, weil wir alle nur Laien sind. Wären wir Profis in der Wissensgewinnung, würde das nicht passieren. Manager zum Beispiel scheinen Profis darin zu sein, während ihrer Berufslaufbahn Wissen darüber anzuhäufen, wie man erfolgreich ein Unternehmen oder dessen Teilbereiche führt. Zusätzlich bekommen sie ja schon das geballte Know-how anderer Profis im Studium vermittelt. Daher kann dies im Management sicher nicht passieren. Oder doch?
Erleuchtet und nachdenklich zugleich zappte ich weiter.
Einige Tage später wurde ich krank. Obwohl ich immer brav die Haare föhne. Ich machte mich auf zu diesem neuen Allgemeinmediziner, den mir ein Freund wärmstens empfohlen hatte. Der Termin war kurz und schmerzlos – wie am Fließband eben, so wie bei all diesen Feld-Wald-und-Wiesen-Krankheiten. Überrascht hatte mich dann aber doch eine Art „FAQ-Notiz“, die ich zum Abschluss in die Hand gedrückt bekam. Neben dem enormen Effizienzgewinn, der dieser Beratungsmethode innewohnt, überraschte mich der Inhalt. Darin stand unter anderem zu lesen: „Trinken Sie keinen Orangensaft. Trinken Sie keine Milch.“ Wissbegierig, wie ich nun mal bin, fragte ich nach. „Das widerspricht doch jedem logischen Menschenverstand. Orangensaft hat Vitamine und muss gut sein. Milch ist sowieso immer super. Das sagt nicht nur die Werbung. Auch endlose Studien der Milchlobby beweisen das“, gab ich extrem logisch zu bedenken.
Okay, die Milch ist nur ein Randthema. Hierzu meinte der Arzt lapidar, dass Milch verschleimt und bei einer Erkältung heiser macht. Aber was ist mit dem Orangensaft? Der Arzt erklärte mir: „Klar, Vitamine sind schon drin. Aber Vitamin C ist gut für die Stärkung der Abwehrkräfte vor der Infektion, wenn auch das Ausmaß, in dem Vitamin C wirklich hilft, umstritten ist. Während der Infektion hilft es dann kaum noch. Viel schlimmer ist jedoch, dass kalte Getränke auskühlen. Das nimmt dem Körper die Energie, die er zur Virenabwehr benötigt. Warm halten, Heißes trinken und ausruhen sind daher die Geheimwaffen zur Genesung“, schilderte er überaus nachvollziehbar.
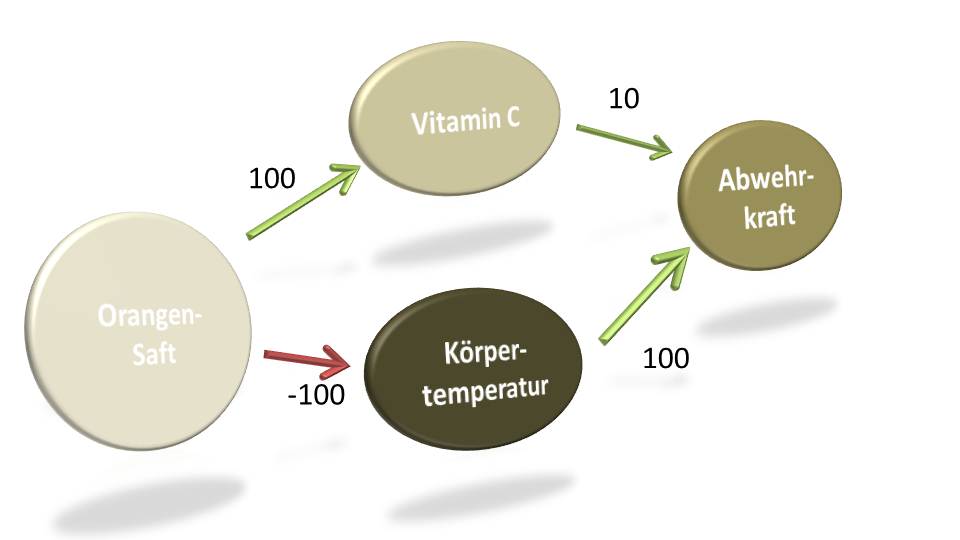
„Puh, schon wieder alles Kokolores, was meine Mutter mir gepredigt hatte.“ Obwohl – nicht ganz. Sie hatte stets darauf geachtet, dass ich Bettruhe bekam. Aber auch das war damals natürlich eine offene Kriegserklärung gegen meine Persönlichkeitsrechte, und ich schaltete auf stur. Immerhin weiß ich heute endlich, dass Mutter zumindest in dieser Sache Recht hatte.
Gedankenversunken ging ich nach Haus. Warum hat mir das noch kein Arzt gesagt? Warum weiß das keiner meiner Freunde? Die Erklärung des Arztes war so einfach wie einleuchtend. Und war ich nicht bestimmt schon hundert Mal in meinem Leben erkältet gewesen? Eigentlich war ich Erkältungsprofi. Trotzdem hatte ich Wissen in meinem Kopf, das nicht nur falsch, sondern sogar schädlich war. Vermutlich war dies deshalb so, weil ich in meinem Privatleben nicht derart strukturiert und professionell Wissen aufbaue, wie ich es in meinem Beruf mache. Im Job lief das alles besser, oder nicht?
Abends erzählte ich meiner Frau Viktoria von meinen neuen Erkenntnissen. Sie nahm meine Erörterungen nicht unkritisch entgegen, pflichtete mir dann aber bei. Ihr Talent, mir Recht zu geben, ist einer der Gründe, warum ich sie so liebe. Nach meinem Vortrag wollte sie sich entspannen und fragte mich: „Hast du noch was von dieser Bitterschokolade übrig? Die macht ja nicht dick.“
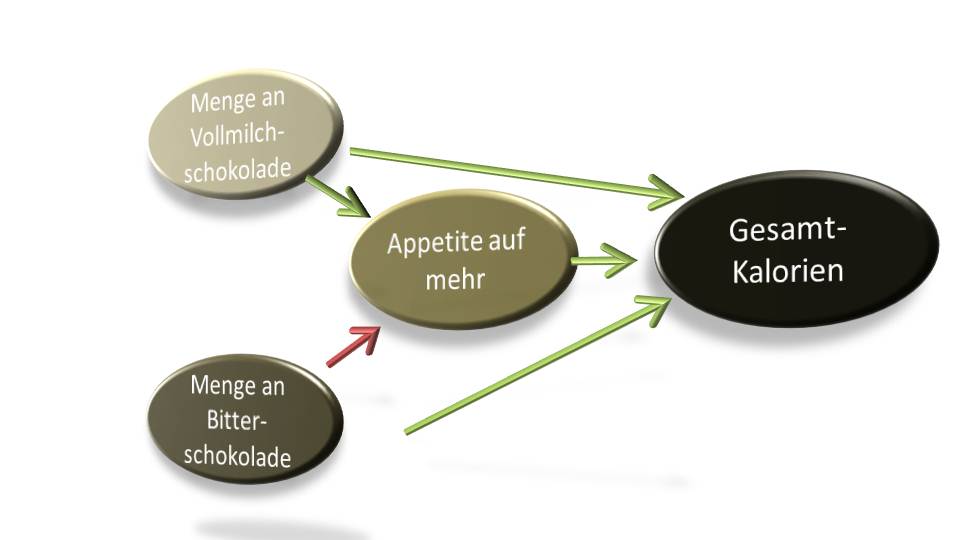
Der kleine Besserwisser in mir erinnerte sie an das Wein-Schokoladen-Seminar, das wir vor kurzem gemeinsam absolviert hatten. Dort machte uns der Kursleiter darauf aufmerksam, dass Bitterschokolade, bedingt durch den höheren Kakaofettanteil, die gleichen Kalorien hat wie ihr Pendant aus Vollmilch. Bitterschokolade hat viel Fett und Vollmilchschokolade hat viel Zucker. Warum also sollte Bitterschokolade nicht so dick machen?
Ich kann nur mutmaßen. Vermutlich neigen Vollmilch-Fans dazu, Unmengen davon zu verzehren, während Bitterschokoladen-Liebhaber tendenziell sparsamer mit dem Genussmittel umgehen. Ob dies an der Schokolade liegt oder ob andere Variablen dafür verantwortlich zeichnen, vermag ich nicht zu beurteilen. Fakt ist, dass jeder „weiß“, dass Vollmilchschokolade dick macht. In Wahrheit aber macht nur viel essen dick, und wenig essen hält schlank.
Zum Glück finden derlei Verwirrungen nur in so unwichtigen Bereichen wie der Schokoladenwahl statt. Meine Frau allerdings wäre geschockt. Denn zu verwechseln, was dick oder schlank macht, ist nicht unwichtig für eine Frau. Okay, wir sind halt auch keine Profis.
Die wachsende Liste der Alltagsmythen, denen wir zum Opfer fallen, hat mich aufmerksam gemacht. So stieß ich vor kurzem auf einen weiteren Mythos.
Ich selbst bin im grauen Osten Deutschlands groß geworden – in einer Zeit, in der Kinderlachen eine Seltenheit war, da es noch keine D-Mark gab. Bei uns war es üblich, dass wir am Wochenende badeten. Keine Ahnung warum, Wasser gab es genug. Ich wusch mir einmal die Woche die Haare. Den Fotos zufolge sahen diese keineswegs fettig aus.
Heute lerne ich aus der Fernsehwerbung, dass tägliches Haarewaschen gar kein Problem ist. Und im Bekanntenkreis gilt man als Sonderling, wenn man zugibt, dies nur alle zwei Tage zu tun. Ein Normalo war ich noch nie. Daher scheue ich mich nicht, ganz offen zu sein. Zum Glück kam mir vor ein paar Jahren wieder Galileo zu Hilfe. Dort testete man genau dieses Phänomen. Man ließ ein paar Damen ihre Haare einige Wochen ungewaschen tragen. Die Folge war, dass die Haare weniger nachfetteten. Daher war ein häufiges Waschen auch nicht mehr notwendig. Das Nachfetten des Haares ist eine Schutzfunktion, die das Haar pflegt und langlebiger macht. Je häufiger Sie waschen, desto mehr muss der Körper nachfetten, um den Schutz aufrecht zu erhalten.

Wie sind nur unsere Vorfahren vor 10.000 Jahren ohne L’Oreal-Produkte ausgekommen? Zugegeben, die sahen damals sicher nicht so elegant aus wie meine Frau heute. Dennoch habe ich das Gefühl, dass diese Mode nicht besonders gesund ist. Wer dennoch auf der täglichen Haarwäsche bestehen möchte, dem sei das natürlich zugestanden. Denn frisch gewaschene Haare sehen natürlich immer am besten aus. Die gesundheitlichen Folgen allerdings muss jeder für sich selbst abwägen.
Aber darum soll es hier primär nicht gehen. Erstaunlich ist allerdings, dass es sich als Grundgesetz der Haarpflege in unsere Köpfe gebrannt hat, dass tägliches Waschen absolute Pflicht ist. Dass hier Ursache und Wirkung verwechselt werden, ist uns allen scheinbar nicht klar.
Zum Glück geht es nur um so banale Dinge wie das Haarewaschen. Ginge es um wirtschaftliche Sachverhalte, würden wir spätestens durch eine Befragungsstudie herausfinden, wohin der Hase läuft. Das glauben wir gern. Aber das ist ein trauriger Irrtum.
Wenn Profis nach Ursachen forschen
Wenn Profis auf die Suche nach Ursachen gehen, werden meist Zahlen verglichen. Worin unterscheiden sich Erfolgreiche von Nicht-Erfolgreichen im Hinblick auf diverse Erfolgsparameter? Korreliert die eine oder andere persönliche Eigenschaft mit dem Erfolg einer Person? Gleich zu Anfang dieses Buches möchte ich den größten Zahn ziehen: Diese „Profi-Methoden“ sind größtenteils unbrauchbar und darüber hinaus oft brandgefährlich.
Vergleichen wir einmal die Vornamen von starken und weniger guten Schülern in Chicago. Wir finden höchst signifikante Ergebnisse. Erfolgreiche Mädchen heißen oft „Judy“, weniger erfolgreiche wurden häufig „Britney“ getauft[1]. In Deutschland heißen die Schulversager Justin und die Durchstarter Maximilian. Der Hintergrund dürfte dem geneigten Leser klar sein. Das Phänomen ist unter dem Begriff Scheinkorrelation bekannt.
Ein anderes Beispiel für solche Scheinkorrelationen ist das angeblich sinkende Durchschnittseinkommen deutscher Ärzte, das vor einigen Jahren festgestellt wurde.[2] Diese Zahlen werden von Lobbyisten natürlich nur zu gern in ihrem Sinn kausal interpretiert. Der wahre Hintergrund der Zahlen war jedoch ein anderer. Tatsächlich nämlich stieg das Einkommen der angestammten Ärzte. Dass jedoch deutlich mehr junge Ärzte mit geringerem Verdienst approbiert worden waren, zog den Durchschnitt in den Keller.
Auch das ist nur ein Beispiel, das nichts mit der Realität in Unternehmen zu tun hat? Weit gefehlt! Wir werden noch sehen, dass jedes Controller-Reporting und jede Bilanz randvoll mit diesen Scheineffekten sind. Fakten sagen nichts über Ursachen. Daher ist jeder Satz über eine Bilanz oder einen Report, der eine Aussage mit „weil“ ableitet, höchstwahrscheinlich haltlos.
Vergleichbare Beispiele gibt es zahllose. So steigt das Einstiegseinkommen von Universitätsabsolventen statistisch gesehen mit der Studiendauer[3]. Wie bitte? Ich Dussel habe mich mit dem Studium beeilt und jetzt das. Hätte ich doch lieber das Studentenleben ausgiebig genossen. Stopp! Natürlich hat auch diese Statistik einen Haken. Sie würfelt Apfel und Birnen zusammen. Genauer: Es werden Betriebs-wirtschaftler, Physiker oder Chemiker gemeinsam betrachtet.
Physiker studieren nämlich grundsätzlich länger, und noch länger tun es Chemiker. Dafür sind die Einstiegsgehälter für Chemiker auch erheblich höher als für BWL-Absolventen. Betrachtet man die Korrelation von Einstiegsgehalt und Studiendauer nur innerhalb eines Studienfaches, stimmt die Richtung wieder. Die Schnelleren verdienen mehr.
Gesundheitsstatistiken sind ähnlich trügerisch. Ein Blick auf die Sterblichkeitsrate durch Krebs offenbart: 26 Prozent der Menschen sterben heute durch Krebs. Vor 100 Jahren waren es lediglich zehn Prozent. Warum, wird man sich fragen, steigt die Bedrohung durch Krebs, obwohl die Therapeutik so viele Fortschritte macht? Schon vermuten wir die Übeltäter, wo sie nicht sind. Schuld tragen bestimmt die Luftverschmutzung, die Nahrungsergänzungsmittel oder die Atomkraftwerke. All das mag in gewisser Weise seinen Teil zur Krebsrate beitragen, ohne dass wir es sicher wissen. Der wahre Grund ist allerdings viel trivialer. Menschen werden immer älter. Krebs hingegen ist auch einfach eine Alterserscheinung. Die Chance, mit einem Krebsbefund konfrontiert zu werden, ist im vergleichbaren Alter heute vermutlich geringer als früher, und die Chance, ein Karzinom zu überleben, ist so hoch wie nie[4]. Fakten sind nur Fakten und verraten für sich allein betrachtet erst einmal absolut nichts über ihre Hintergründe.
Um beim Thema zu bleiben: Intensive Studien haben gezeigt, dass lange Chemotherapien mit höherer Sterblichkeit der Patienten einhergehen. Aufgrund dieser Zahlen haben sich sogar einige „Wissenschaftler“ dazu hinreißen lassen, eine geringe Dauer der Chemobehandlungen vorzuschreiben. Schaut man allerdings etwas tiefer, wird schnell klar, wie viele Menschenleben eine solche Empfehlung kosten kann.[5] Aus medizinischen Gründen und zum Schutz des Patienten ist bei der Anwendung chemischer Methoden eine Maximaldosis vorgegeben. Deshalb muss man bei besonders schwerwiegenden Fällen einfach eine längere Therapie durchführen. Die höhere Sterblichkeit ergibt sich hier nicht aus der Behandlungsdauer, sondern aus der Größe des Tumors zu Beginn der Chemo. Bei aller Bedeutung verbesserter Tumorbehandlung bedeutet ein zu großer Tumor eben fast immer auch ein Todesurteil. Therapien wirken hier eher lebensverlängernd als lebensrettend. Aus diesem Grund ist es klüger, mehr in die Früherkennung zu investieren.
Zum Thema Umweltgifte gibt es eine weitere spannende Studie aus Schweden. Aus der Untersuchung folgte, dass Familien mit PVC-Fußböden in hoch signifikanter Weise mehr Kinder mit Asthma haben. Bevor PVC-Fußböden vollends verboten wurden, fanden kritische Praktiker heraus, dass viele Eltern PVC-Fußböden verlegen ließen, WEIL ihre Kinder Asthma hatten.[6] So konnte der anfallende Staub besser beseitigt werden.
Fakten sagen eben nichts über das Warum. Vor allem dann nicht, wenn die Zeit ihre Finger im Spiel hat. Die Ursache passiert immer vor der Folge. Daher lohnt es sich stets, die zeitliche Abfolge im Blick zu behalten. Ein schönes Beispiel, wie uns die Korrelation von Zeitreihen ein Schnippchen schlagen kann, hat Steven D. Levitt in seinem Bestseller „Freakonomics“ beschrieben.
Anfang der 90er-Jahre war die Kriminalitätsrate in den USA enorm hoch. Vermutlich ein Grund, warum ein Vertreter von Law and Order wie Rudolph Giuliani zum neuen Bürgermeister von New York gewählt wurde. Schon nach kürzester Zeit schien seine drastische Restrukturierung des Polizeiapparates Wirkung zu zeigen. Die Kriminalität sank drastisch, Giuliani wurde weltweit gefeiert. Kann man sich einen besseren Beweis für die Wirksamkeit von hartem Durchgreifen wünschen?
Die Antwort ist: Ja. Zeitreihen wie die Kriminalitätsrate oder die politische Ausrichtung von Regierungen haben Trends. Sie gehen entweder noch oben oder nach unten. Fasst man die betrachteten Zeitintervalle ausreichend kurz, kann man nach Belieben Zusammenhänge hineininterpretieren. So sank in den letzten Jahren auch die menschliche Geburtenrate parallel zur Storchenpopulation in Deutschland. Was sagt uns das? Bringt der Storch doch die Kinder?
In Freakonomics wird anschaulich geschildert, dass der Hintergrund des Kriminalitätsrückgangs, der im Übrigen in den ganzen USA zu verzeichnen war, vorwiegend auf die Legalisierung des Schwangerschaftsabbruchs im Jahre 1973 zurückzuführen ist. Junge, werdende Mütter der Unterschicht, die oftmals alleinstehend waren, konnten nun entscheiden, das Kind nicht auszutragen. Somit wurden deutlich weniger unterprivilegierte Kinder geboren, die durch ihr Umfeld einer höheren Wahrscheinlichkeit unterlagen, später kriminell zu werden. Dieser Effekt machte sich schließlich bemerkbar, als die Schicht der jungen kriminellen Erwachsenen Anfang der neunziger Jahre wegbrach. Giuliani hatte einfach Glück, zur rechten Zeit im Amt zu sein und hat den Abwärtstrend der Kriminalitätsrate zu seinem Verdienst uminterpretiert. So macht man Karriere!
Aber in der Wirtschaft kann so was zum Glück nicht passieren. Keine gestandene Führungskraft lässt sich von einfachem Gleichlauf von Zeitreihen beeindrucken. Oder doch?
[1]Levitt et al. „Freakonomics“
[2]Krämer in „So lügt man mit Zahlen“, S.171
[3]Krämer in „So lügt man mit Zahlen“, S.171f
[4]Krämer in „So lügt man mit Zahlen“, S.171f
[5]Bosbach et al in „Lügen mit Zahlen“, S. 57f
[6]Bosbach et al in „Lügen mit Zahlen“, S. 55f
KAPITEL 2
Eine Management-Illusion
Die zuvor beschriebenen Alltagsmythen beweisen unsere relative Unfähigkeit, die Ursachen von Zielgrößen zu erkennen, die mehr als eine Ursache haben, die also von mehr als einem Faktor beeinflusst werden. So, wie der Orangensaft über verschlungene Pfade unser Abwehrsystem beeinflusst oder so, wie nasse Haare keineswegs direkt eine Erkältung auslösen. Ebenso wenig macht auch Bitterschokolade weniger dick.
Solche Hypothesen über Ursachen stellen wir auf, wenn zwei Größen zusammen auftreten oder deren Ausprägungen in die gleiche Richtung zeigen. Wenn also eine Maßnahme mit dem Steigen einer anderen Größe einhergeht, so nehmen wir intuitiv Kausalität an. Dies ist exakt die Methode, nach der ein Hund in Pavlows Experiment lernt, dass die Glocke das „Essen bringt“, weshalb der Speichelfluss schon mal auf Volltouren gebracht werden muss. Wie wir jedoch gesehen haben, führt diese Forschungsmethode regelmäßig in die Irre.
Doch was bedeutet das für das Management von Unternehmen? Existieren ähnliche Mythen auch im Managementwissen oder in großen Teilbereichen der Betriebswirtschaftslehre? Wird Wissen dort ebenso laienhaft aufgebaut, wie es in unserer Freizeit geschieht? Das wäre fatal. Esse ich ein bisschen zu viel Zartbitterschokolade, nehme ich ein paar Gramm zu – stecke ich viel Geld in eine falsche Investition, kann das schlimmstenfalls in die Insolvenz führen.
Um diese Frage zu erhellen, möchte ich aus meiner eigenen Erfahrung als Manager und Unternehmensberater berichten. Urteilen Sie selbst, ob Ihnen das eine oder andere bekannt vorkommt.
Als Berater war ich in einem weitreichenden Projekt einer großen deutschen Regionalbank engagiert. Definiertes Ziel der Maßnahme war es, aus Kundendaten Erkenntnisse zu gewinnen, um daraus Strategien zum Churn-Management, also zur Kundenbindung, und zur Steigerung des Cross-Selling abzuleiten. Als „bewährtes“ Vorgehen für das Identifizieren von Cross-Selling-Potenzialen galt bislang, Kunden
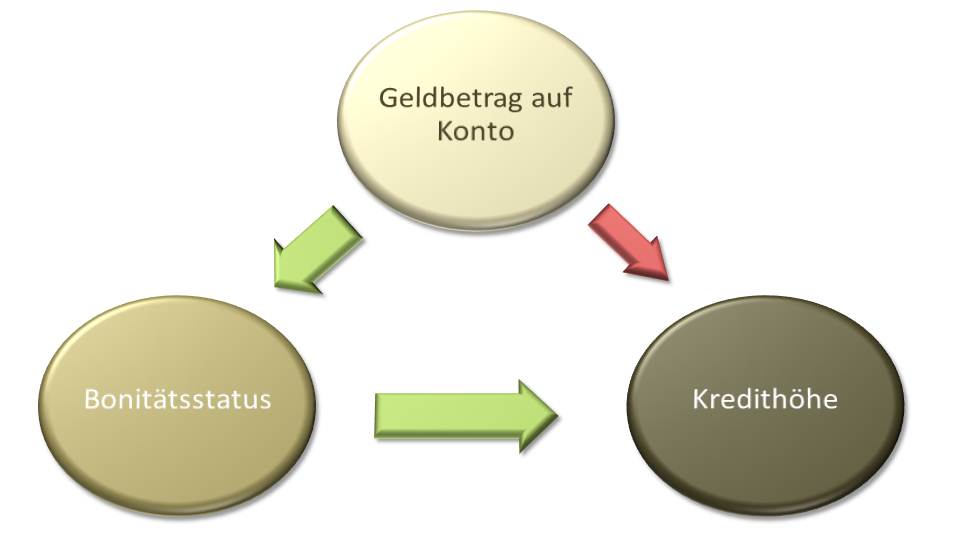
mit gut gefülltem Konto auf Kredite anzusprechen. Man hatte eine starke Korrelation zwischen hohem Kontostand und der Wahrscheinlichkeit, auf Kredit zu kaufen, festgestellt. Deshalb bot man dieser Gruppe verstärkt Privatkredite an.
Eine Treiberanalyse mit multivariaten Analyseverfahren[1] ergab jedoch eine Überraschung. Die Untersuchungen zeigten, dass der Kontostand einen negativen (!) Einfluss auf die Kreditwahrscheinlichkeit hatte. Wir waren verwundert. Können wir der Methode trauen? Eine intensivere Betrachtung der Ergebnisse machte klar, dass insbesondere der Bonitätsstatus eines Kunden positiven Einfluss auf seine Kreditaufnahmen hatte. Da machte es bei uns Klick. Klar, Kredite bekommen Leute mit hoher Bonität. Diese Solvenz bekomme ich, wenn ich vermögend bin. Gleichzeitig brauche ich jedoch tendenziell keinen Kredit, wenn ich genügend liquide Mittel besitze. Wir konnten also zeigen, dass die bisherige Targeting-Methode nicht nur ineffektiv, sondern sogar kontraproduktiv war.
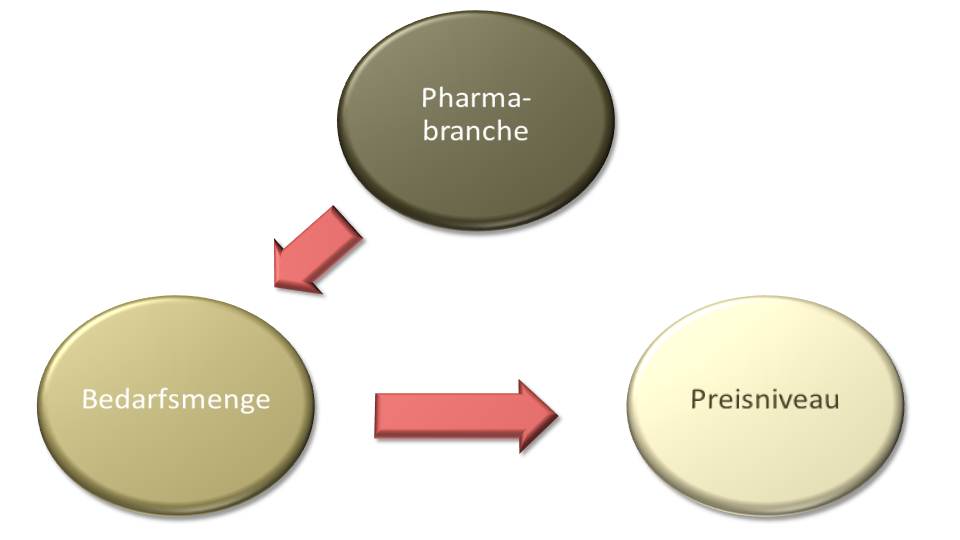
Später, als Sales & Marketing Manager eines Industrieunternehmens, liefen mir weitere dieser Mythen über den Weg. Ich war erst ein paar Wochen an Bord und bekam immer wieder zu hören: „Unsere Kunden im Pharmabereich zahlen für unsere Produkte hohe Preise. Da müssen wir mehr machen und expandieren.“ Ein kritisches Studium der reichlich vorhandenen Transaktionsdaten brachte mich zu einer anderen Hypothese. Ich konnte nachweisen, dass Pharmakunden eher kleine bis mittlere Abnahmemengen aufwiesen. Im Vergleich zu anderen Kunden im Chemiebereich mit gleichen Abnahmen war plötzlich kein Preisunterschied mehr feststellbar. Die Kollegen waren einer klassischen Scheinkorrelation aufgesessen. Das Preisniveau hatte nichts mit der Branche zu tun, sondern war lediglich davon beeinflusst, dass die Abnahmemengen in diesem Bereich klein und die Mengenrabatte spärlich waren. In der Folge konnten unsinnige Investitionen verhindert werden.
Was passieren kann, wenn auf Ursachenanalysen verzichtet wird, konnte ich einige Jahre später am Marktverhalten unseres Wettbewerbers feststellen. Dieser hatte sein gesamtes Vertriebsteam ausgewechselt und nur noch begrenztes Know-how darüber, wie die Märkte funktionieren. Vermutlich machten die Kollegen auch Datenanalysen und hatten festgestellt, dass der Markt für Pappfässer hervorragende Margen aufwies. Die fatale Schlussfolgerung der Kollegen klang verlockend: „Wir müssen in diesem Markt mehr machen – da kann man Geld verdienen.“ Gesagt, getan. Es wurden niedrigere Preise gemacht, um Neukunden gewinnen zu können. Denn wer über keinen herausragenden Wettbewerbsvorteil verfügt, hat nur den Preis als Stellschraube, um Marktanteile zu erobern. Erwartungsgemäß zogen die Verkäufe deutlich an. Die Reaktion der Wettbewerber ließ jedoch nicht lange auf sich warten. Nach dieser Preisbereinigung gingen die Marktanteile auf das frühere Niveau zurück, aber das Preisniveau am Markt war zerstört. Der Markt für Pappfässer war nicht deshalb profitabel gewesen, weil Kunden bereit waren, mehr dafür zu zahlen, sondern weil die Wettbewerber aufgrund von Markthistorie und Anbieterkonzentration darauf verzichten konnten, allzu preisaggressiv aufzutreten.
Dieses und alle anderen Beispiele zeigen drastisch, dass Fakten allein keine nutzbringende Information darüber enthalten, wie sie zustande kommen. Was allein zählt, ist das Wissen über Ursache-Wirkungs-Zusammenhänge. Voraussetzung für dieses Wissen ist das Verständnis des Beziehungsnetzwerks im untersuchten Bereich. Nur so werden richtige und gute Entscheidungen möglich.
Später wurde ich am gleichen Ort mit dem Performance-Management des Vertriebs betraut. Im Kern bestand die Aufgabe darin, im Dialog mit dem Vertrieb diverse Kennzahlen zu prüfen und in einer gemeinsamen Aktion Verbesserungspotenziale aufzudecken und zu tracken. Wie in großen Unternehmen üblich, kamen regelmäßig auch von oberen Hierarchieebenen Anfragen wie: „Was ist im Bereich Garagenfass los? Die Gewinnmarge ist in diesem Monat eingebrochen. Ich brauche bis morgen eine Aufstellung, wo wir sofort Preise erhöhen können.“ Für die Ursachenklärung dieser Sachverhalte war es oft notwendig, die Transaktionsdaten bis auf den einzelnen Artikel und die einzelne Bestellung herunterzubrechen. Warum? Weil eine Kennzahl, wie die aggregierte Gewinnmarge einer Produktgruppe, so etwas ist, wie das scheinbar hohe Einstiegsgehalt von Langzeitstudenten. Man geht fast immer Scheinkorrelationen auf den Leim.
Beispiel: Der Deckungsbeitrag war irgendwann eingebrochen, weil ein Großkunde, der sehr niedrige Preise genoss, seine kompletten Bestellungen vom letzten Monat auf den folgenden Monat verschoben hatte. So wurde der Vormonat optisch besser, der aktuelle Monat schlechter und die Differenz sah ganz besonders übel aus. Derlei Beispiele gibt es viele. Sie zeigen, wie gefährlich es ist, auf Basis von Kennzahlen (neudeutsch KPIs) Entscheidungen zu treffen. Das Kapitel „Umsetzen“ wird zeigen, wie man Kennzahlen aufbauen sollte, um eine große Menge von Scheinkorrelationen zu vermeiden.
Kennzahlen sind nur Fakten und haben für sich genommen keinen Informationswert. Das Warum ist von zentraler Bedeutung. Die ganze Ideologie des Fact-based-Management wird vor diesem Hintergrund in Frage gestellt. Nicht Fakten sollten im Vordergrund stehen, sondern das Wissen über Ursache-Wirkungs-Zusammenhänge. Was wir demnach dringend benötigen, ist ein Knowledge-based-Management.
Doch was bedeutet das für Controlling, Reporting und Performance-Management, die mit all diesen schicken Dashboards sorgfältig in unseren Unternehmen aufgesetzt wurden? Welche Konsequenzen hat es für unsere Organisation und die Mitarbeiter? Mitarbeiter wissen meist intuitiv, dass die Kennzahlen „was für die da oben“ sind, aber wenig mit der Realität zu tun haben. Aber Steuern mit Kennzahlen schafft auch Realität. Wenn der Chef sagt, der Deckungsbetrag muss hoch, dann wird gehandelt – koste es, was es wolle. Wenn der ROI steigen soll, schließt man einfach alle Geschäfte, die unterdurchschnittlich sind, auch wenn sie die Kapitalkosten decken und gutes Geld verdient wird. Zum Trimmen von Kennzahlen gibt es so viele Wege wie Ursachen. Nur diese Wege sind oft nicht im Sinne des Unternehmens.
Das alternative „Beyond Budgeting“ etwa setzt, statt Kennzahlen zu verabsolutieren, Werte in Relation zu externen Vergleichswerten. Der Gedanke ist gut, hat jedoch erhebliche Grenzen. Gerne möchte man externe Faktoren aus Kennzahlen herausrechnen. So betrachtet man etwa statt dem Gewinn den relativen Gewinn im Vergleich zum Wettbewerb. Ein Problem dabei ist die Frage, wo man die Vergleichszahlen überhaupt herbekommt. Ist man in der glücklichen Informationslage, dass alle Daten vorliegen, schlittert man ins nächste Problem, wenn man bereits zwei externe Faktoren herausrechnen möchte. Wir werden im nächsten Kapitel sehen, wie man besser vorgehen sollte.
Wir stellen fest, dass das Ableiten von Maßnahmen auf Basis üblicher Kennzahlen ein erhebliches Fehlverhalten verursacht. Dass es noch schlimmer geht, zeigt eine kleine Anekdote aus meiner Praxis. Die meisten Führungskräfte, die regelmäßig mit ihren Mitarbeitern die wichtigsten KPIs durchgehen, werden Ähnliches schon erlebt haben: Als ich mir den aktuellen durchschnittlichen Rohertrag (Preis minus Materialkosten) ansah, fiel mir auf, dass dieser gesunken war. Natürlich fragte ich den den verantwortlichen Außendienstmann: „Was war da los diesen Monat?“ Seine Antwort: „Oh ja, die neuen Preise für Großkunde Fa. Müller gelten erst ab nächsten Monat. Und die hochprofitablen ABC-Produkte wurden diesen Monat wegen fehlendem Bedarf nicht bestellt.“ Eine ziemlich schlüssige Begründung. Ich bin zufrieden. Plötzlich fällt mir auf, dass ich den falschen Zeitraum eingestellt hatte und mir die Zahlen vom letzten Jahr angesehen hatte. Verglichen damit sinken sie Zahlen gar nicht, sondern sie steigen! „Äh sorry, mein Fehler. Warum steigt denn der Rohertrag?“ Daraufhin der Mitarbeiter: „Ja richtig, ich hab ja den neuen Kunden Fa. Meier an Land geholt und die restlichen Preiserhöhungen konnte ich gut durchdrücken.“
Was sagt uns das? Beobachten Sie einfach mal, wie Manager auf Fakten reagieren. Werden beliebige Zahlen oder andere Fakten präsentiert, so wird sofort eine Legende darüber gesponnen, wie diese Zahlen zustande gekommen sind. Es ist wie ein Reflex. Ich kann selbst nicht anders. Nur dass fast alle tatsächlich daran glauben, dass ihre aus den Fingern gesaugten Mutmaßungen mit hoher Wahrscheinlichkeit richtig sind. Es ist frappierend. Wir finden immer eine Begründung für eine Zahl oder einen Fakt – leider immer erst hinterher. Vorher weiß es keiner. Die Finanzkrise 2008 hat kaum
jemand kommen sehen – vor allem nicht die Medien. Im Nachhinein findet die Presse schnell die Schuldigen. Wenn es so offensichtlich war, warum hat denn keiner dieser Schreiberlinge vorher davor gewarnt? Das ist alles nur haltloses Storytelling im Nachhinein. Es enthält keinerlei nützliches Wissen. Daher ist es auch gefährlich, sich zu sehr mit diesem „Rauschen“ (wie Nachrichtentechniker sagen) zu beschäftigen. Es führt geradewegs zum Kaffeesatzlesen und zu zwar verfestigtem aber falschem Wissen.[2]
Die Welt des Managements ist übervoll von diesen haltlosen Legenden. 80 Prozent der Bücher in der Managementliteratur funktionieren wie folgt: Zig Fallbeispiele aus erfolgreichen Unternehmen werden werden daraufhin interpretiert, warum sie erfolgreich waren. Dieses Vorgehen ist ein gelungener Mix aus clever selektierten Beispielen und der geschickten Unterschlagung gegenläufiger Fälle – garniert mit einem höchst phantasievollen Storytelling über die Scheinursachen. Meinen persönlichen Aha-Effekt hatte ich, noch bevor ich beschlossen hatte, allen Fehlinformationen durch Managementbücher abzuschwören. Zuerst las ich Wachsen ohne Wachstumsmärkte von Adrian Slywotzky und Andrew Wise, in dem wunderbar beschrieben ist, wie wertvoll es sein kann, sich durch Vorwärtsintegration in die Prozesse des Kunden einzugraben. Als eines ihrer Paradebeispiele fungierte die Firma Cardinal Health – ein riesiger Pharmagroßhändler mit 80 Milliarden Umsatz, der sich durch diverse Produkte und Services tiefer in die Prozesse von Krankenhäusern und Apotheken eingrub. Stolz wandte ich mein neu „erlesenes“ Wissen in einem internen Strategieworkshop an, indem ich mich auf Cardinal Health bezog. Ein Kollege konterte: „Moment! Soweit ich weiß, geht es Cardinal Health derzeit gar nicht gut. Die haben zu viele Geschäftsfelder jenseits ihrer Kernkompetenzen adressiert. Das alles kannst du prima in Chris Zooks Beyond the Core nachlesen. Bei Zook ist Cardinal Health als drastisches Negativbeispiel genannt.“
Beispiele sind schöne Illustrationen, um Konzepte verständlich zu machen. Als Indiz oder gar Beweis für Theorien über Ursachen taugen sie allerdings keinesfalls. Warum das so ist? Weil die meisten Tatsachen mehr als ein oder zwei Einflussgrößen haben. Weil das so ist, scheitern wir immer dabei, durch Vergleiche von lediglich zwei
Größen korrekte Schlüsse über Ursache-Wirkungs-Zusammenhänge zu ziehen.
Andere Beispiele für Pseudowissen im Management gibt es zur Genüge. Das PIMS-Projekt hat viele davon aufdecken können. PIMS ist eine Datenbank, in der seit den 1970ern über 70 relevante Ursachen für das Return-On-Investment (ROI) einer Unternehmenseinheit gesammelt werden. Es ist vermutlich die einzige Datenbank, mit der ein ursächlicher Einfluss von Marktstrategien auf die Unternehmens-profitabilität wissenschaftlich valide untersucht werden kann.
Das typische Vorgehen in den Strategiestäben der Unternehmen ist ungefähr wie folgt: „Lasst uns anschauen, welche Märkte am meisten wachsen (Megatrends), welche Märkte groß sind und wo man gutes Geld verdienen kann (Marge).“ PIMS hat gezeigt, dass dieses hochplausible Vorgehen nicht nur irrelevant, sondern teilweise sogar gefährlich ist. Denn, weil es so intuitiv einsichtig scheint, handelt fast jeder Marktteilnehmer so. In Wahrheit ist es immer eine schlechte Idee, neu in einen zu großen Markt einzusteigen, da man selbst nicht schnell genug kritische Masse erreichen kann. Märkte, die klein genug sind, um darin Marktführer zu werden, sind erheblich attraktiver.
Weiterhin ist es absolut irrelevant, sich am heutigen ROI zu orientieren. Was einzig und allein zählt, ist der potenzielle ROI. Profitable Geschäfte sind nun mal auch teuer zu erwerben. In anderen Fällen zerstört man durch die hohe Investition in eigene Kapazitäten womöglich den Grund für die Profitabilität in einem Geschäftsfeld (wie in unserem Pappfässer-Beispiel). Nicht zuletzt ist auch die aktuelle Marge, der EBIT, so gut wie irrelevant (zumindest sofern er positiv ist). Denn was zählt, ist das Verhältnis im ROI, also das vom gebundenen Kapital zum Gewinn. PC-Direkthändler, wie etwa DELL, verdienen ihr Geld nicht mit hoher Marge, sondern damit, dass kein Kapital im Geschäft gebunden ist, weil die Kunden alles vorschießen. Der Kunde zahlt zuerst, und erst dann werden Einzelteile eingekauft, PCs zusammengesteckt und ausgeliefert. Aldi hat vermutlich auch deshalb einen sehr hohen ROI, weil, verursacht durch die geringe Produktvielfalt, Artikel nur wenige Tage im Regal liegen bleiben.
Ein anderer Mythos, mit dem PIMS aufgeräumt hat, ist die von Michael E. Porter
aufgebrachte Verallgemeinerung, dass die Kundenmacht möglichst klein sein sollte. PIMS hat das relativiert und einen U-förmigen Zusammenhang nachgewiesen. Wenn die Kundenanzahl eines Unternehmens einstellig wird, beginnt der Zusammenhang sich umzukehren. Denn in vielen Fällen hat die Abhängigkeit dann einen Hintergrund – sie ist symmetrisch. Beide Partner brauchen sich. Der Lieferant liefert besondere Leistungen, der Kunde gibt durch einen guten Preis einen Teil der Wertschöpfung ab.
Diese Beispiele illustrieren folgende Punkte:
- Die deskriptive Analyse von Fakten führt oft zu falschen Erkenntnissen.
- Menschen neigen dazu, Ursachen auf Basis von Fakten buchstäblich zu erfinden und durch Storytelling plausibel zu machen.
- Mythen entstehen als natürliche Folge von falschen Analysen und der Weitergabe dieses willkürlich entwickelten Pseudowissens. Es kann nachgewiesen werden, dass ein Großteil des verbreiteten Management-wissens schlichtweg falsch ist. Was nicht gänzlich falsch ist, ist teilweise so vage, dass es nicht widerlegbar (im Sinne der Wissenschaftstheorie inhaltsleer) und daher unbrauchbar ist.
In den 80er Jahren erwuchs aus der sehr nützlichen Systemorientierten (Kybernetischen) Managementlehre unter anderem die Forderung nach komplexerem und besser vernetztem Denken. Der Hintergrund war die Feststellung, dass Zielgrößen im Management viele Ursachen und Treiber haben und gegenseitig vernetzt sind, weil indirekte Wirkeffekte und Rückkopplungen existieren. Fest steht, dass ein adäquateres, elaborierteres Denken sicher nicht schaden kann. Dieses Buch soll zusätzlich zeigen, dass elaborierteres Denken nicht ausreicht, um Komplexität zu managen. Es kommt primär darauf an, richtiges und gesichertes Wissen zu bilden. Hierfür benötigen wir Menschen geeignete Werkzeuge.
Dieterich Dörner hat in diesem Zusammenhang untersucht, wie Menschen komplexe Systeme managen können. Er baute einfache mathematische Modelle über die ökonomischen Zusammenhänge in einem Land auf und bat Probanden, dieses Land im Rahmen eines Planspiels zu managen und den Wohlstand zu mehren. Dabei kannten die Probanden die tatsächlichen Ursache-Wirkungs-Beziehungen nicht. Im Ergebnis stellte Dörner fest, dass wir Menschen erhebliche Probleme haben, komplexe Systeme zu managen. Selbst gute Probanden erlernten dieses Management erst nach vielen Spieljahren, indem sie zunehmend systemischer dachten und Zeitverzögerungen einkalkulierten.
Was lernen wir daraus? Zwar ist vernetztes Denken nützlich, jedoch haben Manager keine fünfzig Jahre Zeit, alle Ursache-Wirkungs-Beziehungen zu verstehen und zu verinnerlichen. Daher ist es in vielen Fällen überhaupt nicht möglich, durch simple Managementerfahrung erfolgreiches Wissen aufzubauen. Darüber hinaus ist die Realität weit komplexer als diese einfachen Planspiele.
Kurzum, es gibt erhebliche Grenzen, valides Wissen über komplexe Systeme abzuleiten – insofern man keine geeigneten Werkzeuge zur Verfügung hat. Um dies plastisch zu machen, möchte ich hier die Komplexitätsmatrix einführen.
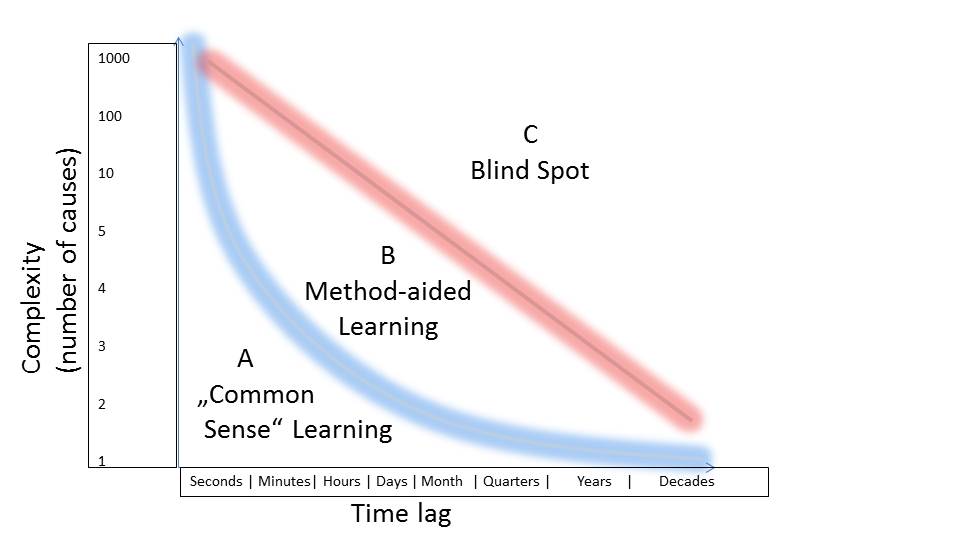
Dimension 1 ist die „Anzahl der beeinflussenden Größen“: Je mehr Dinge auf die zu steuernde Größe zur gleichen Zeit Einfluss nehmen, desto schwieriger ist es, auf Basis von Erfahrungswerten Wissen abzuleiten.
Dimension 2 ist die „Zeit“ die zwischen Ursache und Wirkung vergeht. Je länger man warten muss, bis ein Ergebnis sich einstellt, desto eher wird man durch Folgen anderer Ursachen abgelenkt und desto länger braucht es, bis Wissen aufgebaut ist.
Einfache Probleme mit schneller Rückmeldung können wir durch normales menschliches Lernen gut bewältigen. Beim Autofahren beispielsweise bekommen wir direkte schnelle Rückmeldung und die Treibergrößen sind mit Gas, Bremse und Lenkrad schnell beschrieben.
Nehmen wir ein Problem, bei dem man schnell Rückmeldung bekommt, bei dem aber mehr Größen vorhanden sind: „Wie wirkt ein Plakat?“ Hier zeigt man es potenziellen Kunden und nimmt deren Rückmeldung auf.[3] Jetzt kann ich Teile des Plakats ändern und überprüfen, was das verursacht. Sicher gibt es viele Ursachen, die ein Plakat wirkungsvoll machen. Das geht von der Bildgestaltung und den verbundenen diversen Assoziationen über die Anordnung hin zur inhaltlichen Ausrichtung, Typographie und zur Verwendung von emotionalisierenden Kern-Visuals. Daher ist das Thema sicher hochkomplex. Wenn ich jedoch einige Faktoren fixiere und so die Komplexität reduziere, kann ich durch ein gutes Experimentaldesign herausbekommen, welche Treiber welchen Einfluss haben.
Probleme mit langer Feedbackzeit sind problematischer. Wie lange braucht es, bis ein Produktlaunch seinen Erfolg zeigt? Je nach Industriezweig kann das viele Monate in Anspruch nehmen. Der Erfolg hingegen hat viele, sehr viele Väter. Wenn man die Treiber mit Experimenten erforschen möchte, kann man nicht nur viele Jahrzehnte verbringen, sondern auch Unmengen an Geld verschleudern. Hier wird man vermutlich andere Methoden verwenden müssen, um die Erfolgstreiber besser zu verstehen. Als Daumenregel gilt: Je mehr Ursachen eine Zielgröße hat und je länger es dauert, bis sich Erfolge einstellen, desto eher müssen wir externe Werkzeuge verwenden, um das Problem aktiv managen zu können. Zusätzlich gibt es natürlich auch Grenzen unserer Erkenntnisfähigkeit. Hochkomplexe Systeme mit langer Rückmeldezeit werden wir eventuell nie verstehen. Zumindest wird das so lange gelten, wir keinen Weg finden, das komplexe Problem in einfachere Teilprobleme zu unterteilen.
Lassen Sie uns Unternehmensfunktionen einmal entlang der Dimensionen bewerten:
- Mittlere Variablenanzahl und kleines Timelag: Produktion, IT, Verwaltung
- Viele Variablen und größeres Timelag: Einkauf, Verkauf, Marketing, HR/Personalführung, Unternehmensführung
Unternehmensbereiche, deren Aufgabe es ist, die Interaktion mit sozialen Systemen zu managen, seien es die eigene Belegschaft, die Kundenmärkte oder die Lieferantenmärkte, sehen sich einer hohen Komplexität und eher großen Timelags ausgesetzt. In diesen Bereichen haben Zielgrößen viele Ursachen. Beispielsweise können „Steigende Gewinne eines Unternehmens“ tausende Ursachen haben: höhere Preise, profitablerer Produkt-Mix, steigende Verkaufsmengen, sinkende Stück- oder Fixkosten. All diese Bereiche sind eigentlich Aggregate und keine wirklichen Ursachen. Ursachen wäre etwa der Rückzug eines preisaggressiven Wettbewerbers, die Einführung eines überlegenen Neuprodukts oder eine Vertriebsmannschaft, die mehr Kundenbesuche macht. Ursachen sind daher immer Aktivitäten, weniger aggregierte Ergebnisse von Teilgrößen.
Im Gegensatz dazu sind technische Systeme (wie Produktion, IT oder Verwaltungsaufgaben) prinzipiell simpler, weil man sie in Teilsysteme zerlegen kann und diese zumeist sehr schnell Rückmeldung geben. Man bemerkt schnell, ob Maßnahmen die gewünschten Folgen zeigen. Daher kann man schneller und präziser lernen und damit korrektes und funktionierendes Wissen aufbauen.
Die Unternehmensfunktionen Management, Einkauf und Verkauf arbeiten heute tendenziell mit falschem und schlecht gesichertem Wissen. Schuld daran tragen aber nicht die Personen, die dort tätig sind. Diese Bereiche sind komplexer und daher schwieriger zu managen. Das Fatale ist jedoch, dass der Grund für unsere Unfähigkeit, richtiges Wissen zu erlernen, auch gleichzeitig der Grund dafür ist, dass wir dies nicht bemerken. Unser phantasievolles Storytelling findet immer eine plausible (aber haltlose) Theorie darüber, wie sich bestimmte Fakten erklären. Nur scheint dies niemandem aufzufallen. Es entsteht eine Illusion von Kompetenz und eine Illusion, alles im Griff zu haben. Es entsteht die Management-Illusion.
[1]Mehr dazu im nächsten Kapitel
[2]Eins ist mir wichtig: Ich möchte hier niemanden anklagen. Es ist, wie es ist, weil unser Ausbildungssystem so ist, wie es ist. Trotzdem sollten wir natürlich an den offensichtlichen Verbesserungsfeldern arbeiten.
[3]Auf die Beschreibung diverser Marktforschungstechniken zur validen Messung gehe ich hier nicht ein.
KAPITEL 3
Mit richtigen Methoden Ursachen aufspüren
Bislang haben wir eine Bestandsaufnahme gemacht. Die Fähigkeit von Menschen, aus Erfahrungen Wissen abzuleiten, beschränkt sich im Grunde auf die Prinzipien der Konditionierung. Parallel auftretende Sachverhalte werden assoziiert und kausal in Zusammenhang gebracht. Dieses Lernen durch Konditionierung funktioniert in einfachen Umgebungen auch recht zuverlässig. Sie ist zwar ebenso für das Entstehen von Aberglauben und anderen Mythen verantwortlich, aber für die simplen Dinge des Überlebens ist die Methode sehr wirkungsvoll. Wenn es blitzt, ist der Donner nicht weit und wir suchen Schutz. Sieht der Jäger den frischen Hufabdruck eines Wildschweins, spannt er den Hahn seines Gewehrs. Jedoch führt diese Konditionierung auch zu unsinnigem Scheinwissen. Viele Fußballfans schauen sich das Spiel der Lieblingsmannschaft nicht an, weil sie glauben, dass dies Unglück bringt. „Beim letzten Mal, als ich das Spiel verpasst habe, haben wir gewonnen.“ Genauso rasieren sich viele Spieler nicht, weil sie nach zwei Siegen mit unrasiertem Kinn an eine Siegesserie glauben, die von ihrem Bartwuchs abhängig ist.
In komplexeren Bereichen wie sozialen und wirtschaftlichen Systemen allerdings führen uns unsere Lernmethoden regelmäßig in die Irre. Diese Erkenntnis ist noch nicht Allgemeinwissen geworden. Denn das Erleben der Manager gibt nur bedingt Hinweise darauf. Man (er)findet ja im Nachhinein immer Gründe, warum Dinge so passiert sind. Doch das Erleben ist trügerisch, weil es denselben einfachen Lernregeln folgt. Warum soll man auch die Art und Weise, zu lernen und zu managen, ändern, wenn man doch bislang einigermaßen erfolgreich war?
Die Antwort auf diese Frage finden wir im Relativitätsprinzip der Wirtschaft. Es kommt nicht darauf an, absolut richtig zu liegen, absolut schnell, billig oder schlau zu sein. Es kommt lediglich darauf an, besser zu sein als andere. Schlechte Ursachenanalysen sind nur ein Problem, wenn andere besser sind. Der Einäugige ist unter den Blinden König.
Diese Überlegungen zeigen, welche immensen Potenziale wir anzapfen können, wenn es uns gelingt, die wahren Erfolgstreiber auch und gerade in komplexen Sachverhalten zu ermitteln.
- „Wie könnte ich meinen Gewinn steigern, wenn mein Unternehmen als einziges ermitteln könnte, welche spezifischen Hintergründe hinter dem jüngsten Umsatzrückgang der Branche stehen?“
- „Wie schlagkräftig und Budget sparend könnte ich meine Kunden gegen das Werben der hungrigen Konkurrenz immunisieren, wenn ich allein die wirklich „erogenen Zonen“ der Kundschaft identifizieren kann?“
- „Wie viel profitabler und wachstumsstärker würde mein Unternehmen, wenn nur ich wüsste, welche 50% meiner Werbeausgaben bislang vergeudet werden?“
- „Welche Anziehungskraft würde mein Unternehmen für Talente und High Potentials entfalten, wenn ich im Kern wüsste, welche versteckten Hebel neben dem Gehalt für diese faktisch relevant sind?“
- „Welche Gewinnexplosion könnte mein produzierendes Unternehmen auslösen, wenn durch bessere Vorhersage von Rohstoffpreisentwicklungen deutlich billiger mit weniger Kapitalbindung eingekauft würde?“
Die zentrale Bedeutung brauchbaren und zuverlässigen Wissens scheint evident. Ziel muss es also sein, Methoden zu finden und einzusetzen, mit denen es möglich ist, dieses so nötige Wissen zu erlangen.
Der Methodenkanon
Der Rohstoff des Lernens sind Erfahrungswerte. Lernen bedeutet Wissen gewinnen. Erfahrungswerte sind lediglich Fakten, Zahlen, Erlebnisse. Immanuel Kant hat den Satz geprägt: „Erfahrung ist die einzige Quelle der Erkenntnis.“ Wenn wir nicht auf Erfahrungen aufbauen, dann bauen wir auf vorhandenem Wissen oder Annahmen auf. Diese sind ebenso zuvor durch Erfahrungswerte gebildet worden. Jedoch ist das vorhandene Wissen, sofern es konventionell erworben wurde, wie gezeigt, oft chronisch verzerrt oder einfach falsch. Daher sind Methoden, die unser Wissen zuverlässiger machen, immer Methoden, die intelligenter mit Fakten, Zahlen und Erlebnisberichten umgehen.
Wenn ich von „echtem“ Wissen spreche, meine ich eben nicht nur Zahlen und Fakten. Natürlich können wir auch die im Kopf haben. Dennoch sind sie für mich Informationen oder Rohdaten, auf sich allein gestellt, noch kein Wissen. Unter Wissen verstehe ich die Kenntnis von Ursache-Wirkungs-Relationen. Ich verstehe darunter, dass man weiß, welche Maßnahme zu welchem Ergebnis beitragen wird. Dieses kausale Wissen lässt sich nur erwerben, indem man aus Beispielen lernt, dass bestimmte Maßnahmen bestimmten Folgen auslösen. Man muss also Input und Output beobachten, um durch Analyse Wissen ableiten zu können.
Welche Methoden sind praktikabel? Wie steht es beispielsweise mit geschicktem Aufbereiten von Erfahrungswerten? Hier können wir einen sogenannten Gruppenvergleich bemühen. An einem Beispiel lässt sich zeigen, wie er funktioniert und warum er nicht funktioniert:
Wie unterscheiden sich erfolgreiche Unternehmen von schlechter aufgestellten hinsichtlich der Ausprägung ihrer Erfolgstreiber? Der Gruppenvergleich stellt fest, dass erfolgreichere im Schnitt größer sind. Außerdem arbeiten sie eher mit einem ein ERP-System oder treiben mittels eines R&D-Budgets Forschung und Entwicklung voran. Bringt das eine gesicherte Erkenntnis über Erfolgsursachen? Vielleicht sind es einfach Folgen. Vielleicht sind es Resultate anderer Treiber wie etwa der Unternehmenskultur. Wenn es keine Treiber sind, dann wird die aktive Steuerung der Größen nicht den gewünschten Effekt bringen.
Das Gleiche gilt für sogenannte Korrelationsanalysen. Diese berechnen den Gleichlauf zwischen zwei Variablen und liefern ähnliche Ergebnisse wie die Gruppenvergleiche.
In der folgenden Grafik sind Ergebnisse aus der Kosmetikindustrie beispielhaft dargestellt. Sie stellt die Erfolgstreiber von Pflegeprodukten dar. Ein schneller Blick offenbart, dass Korrelationen (links) in diesem Fall kaum irgendetwas über die Realität erzählen, wenn wir diese mit den Ergebnissen einer geeigneten mehrdimensionalen Ursachenanalyse vergleichen, für die ich aus praktischen Gründen plädiere.

Wenn wir beide Seiten aufmerksam studieren, stellen wir gravierende Unterschiede bei jedem Erfolgstreiber fest. Wer sein Budget nach der Korrelationsmethode verteilt, verliert unter Umständen viel Geld.
Vergessen wir also Korrelationen. Vergessen wir Gruppen und sogenannte Top2-Vergleiche. Vergessen wir simples Benchmarking. Es sagt einfach nicht viel über Ursachen. Wir haben auch im vorherigen Kapitel viele andere drastische Beispiele gesehen. Egal wie intelligent wir Fakten aufteilen oder aggregieren – es ist auf diesem Weg nicht möglich, die partiellen Einflussfaktoren zu korrekt zu separieren.
Kontrollierte Experimente
Eine wirklich funktionierende Methode, korrektes Wissen über Ursache-Wirkungs-Zusammenhänge zu erhalten, ist das Experiment. Ausprobieren ist die bewährte Technik, die die Evolution verwendet. Hochkomplexe Lebewesen sind so entstanden – und dies in einer Komplexität und Leistungsfähigkeit, die wir Menschen mit heutiger Technik noch immer nicht nachbauen können. Genauso wie die biologische Evolution funktioniert auch die Evolution von Wissen, Wertesystemen, Glaubensrichtungen und Legenden. Solche, die weitergeben werden und sich somit reproduzieren, überleben. Der große Haken an der biologischen Evolution ist, dass sie sehr lange Zeiträume zur Verfügung hat. Ihr zweiter Haken ist, dass manche Fehlversuche drastisch bestraft werden. Die soziale Evolution führt langfristig zu guten Ergebnissen für die Gesellschaft. Braucht man aber als Individuum oder als
einzelnes Unternehmen Erfolgswissen, muss man vorsichtiger vorgehen, um der Evolution nicht zum Opfer zu fallen. Alles Ausprobieren hat seine Grenzen. Ist ein anderer schneller, verlieren wir. Powern wir viel Geld und Hoffnung in ein zu gewagtes Marktexperiment, verlieren wir auch.
Das Experiment an sich ist jedoch grundsätzlich die beste Methode, um etwas über Ursache-Wirkungs-Zusammenhänge zu lernen. Wann immer es im Hinblick auf Kosten und Risiken vernünftig ist, sollte man Experimente anderen Methoden vorziehen. Denn wenn zwei Größen konsistent korrelieren und eine davon durch unsere Maßnahme hervorgerufen wurde, dann ist ein kausaler Zusammenhang sehr wahrscheinlich. Praktisch gesprochen: Wenn ein Hammer auf meinen Finger fällt, könnte es mit viel Phantasie ja auch sein, dass eine geheime Schmerzsehnsucht den Hammer magnetisch anzieht. Dann wäre die Sehnsucht die Ursache und nicht die Gravitation. Wenn ich den Hammer jedoch in einem bestimmten Moment bewusst und willentlich auf meinen Finger schlage, kann ich ziemlich sicher sein, dass der darauf folgende Schmerz sehr wahrscheinlich durch den Hammer verursacht wurde – und nicht umgekehrt. Experimente kontrollieren die Wirkungsrichtung der möglichen Ursachen.
Das Experiment ist auch eine starkes Verfahren, um die Effekte, die mehrere Treibergrößen haben, voneinander zu trennen. Denn genauso, wie man eine Ursache aktiv verändern kann, um die Wirkung zu beobachten, so kann man zeitgleich eine zweite Ursache konstant halten. Wenn in Ihrem PC einer von zwei Speicherriegeln defekt scheint, bauen Sie einen aus. Läuft das Gerät dann wieder, ist der ausgebaute Arbeitsspeicher Ihr Übeltäter. Bricht der Start erneut ab, tauschen Sie die Riegel. Wenn Ihr Rechner jetzt wieder funktioniert, halten die den Übeltäter in den Händen. Durch dieses einfache Experiment können Sie den Einsatz eines teuren Technikers sparen.
Die Werbung macht es vor
In der Tat gibt es einige Bereiche in der Wirtschaft, in denen häufig mit Experimenten gearbeitet wird. Werbetests sind ein typisches Beispiel. Plakate oder Anzeigenwerbung werden in Teststudios getestet und variiert, bevor sie gelauncht werden.
Auch die Messung von Kundenpräferenzen wird regelmäßig in so genannten Conjoint-Measurement-Experimenten durchgeführt. Hierbei variiert man systematisch die Eigenschaften eines Produktes in der Produktbeschreibung und befragt den Kunden, inwieweit er dieses Produkt gegenüber Vergleichsprodukten bevorzugt. Sowohl Plakattests als auch Conjoint-Experimente sind quasi eine Art Trockenschwimmen, weil sie keine Tests in der Realität darstellen. Das Vorgehen büßt zwar ein Stück Validität ein, ist aber erheblich günstiger als ein Live-Test.
Echte Live-Tests sind üblich beim Optimieren von großen Direct-Mailing-Kampagnen. Objekt der Optimierung ist hier zum einen die Gestaltung des Anschreibens und zum anderen die Selektion der anzuschreibenden Kontakte. Denn in Direkt-Mailing-Kampagnen werden Briefe nicht an alle Kontakte in der Datenbank geschickt, sondern nur an Adressen mit hoher Responsewahrscheinlichkeit. Indem man nun zusätzlich einige Mailings an zufällig (oder strukturiert) ausgewählte Kontakte sendet, bekommt man durch deren Rücklaufquote eine Kontrollgröße, die es erlaubt, die Schätzung der Antwortwahrscheinlichkeit zu optimieren. Jeder Brief an einen zufällig (oder strukturiert) ausgewählten Kontakt ist ein Experiment.
Aber auch in anderen Bereichen sollte man Experimente in Erwägung ziehen, wie etwa bei der Standortwahl, der Art und Weise, wie man im Vertrieb auftritt, oder bei der Entwicklung neuer Angebote.
Worauf sollte man bei der Durchführung von Experimenten achten?
- Schritt 1: Alle zentralen Erfolgsgrößen aus bisherigem Wissen zusammentragen
Bei einem Experiment geht es darum, die Effekte verschiedener Ursachen zu bewerten und zu separieren – also voneinander zu trennen. Eine Ursachenanalyse ist immer nur dann valide, wenn alle Ursachen kontrolliert, also gemessen, gesteuert oder konstant gehalten werden. Daher ist es immer notwendig, sich vor einem Experiment Gedanken darüber zu machen, welche Ursachen es möglicherweise geben könnte.
Ich werde oft gefragt: „Was ist, wenn ich eine wichtige Ursache vergesse?“ Die Antwort ist einfach: Es gibt keine Alternative zu diesen Methoden der Analyse von
Ursachen-Wirkungs-Zusammenhängen. Wenn wichtige Faktoren fehlen, laufen wir zwar Gefahr, einige Scheinerkenntnisse zu erhalten, aber positiv ausgedrückt haben wir die besten Erkenntnisse, die man in diesem Moment erlangen kann. Der Prozess der Ursachenanalyse wird immer unvollständig und in Teilen fehlerhaft bleiben. Es ist philosophisch gesehen unmöglich, die Realität in Perfektion zu verstehen. Darum geht es auch nicht. Es geht immer nur darum, weniger Fehler zu machen. Nach dem alten Muster weiterzumachen bedeutet, mehr Fehler zu machen und mehr Geld „zu versenken“.
- Schritt 2: Experimental-Design erstellen:
Sind alle möglichen Ursachen bekannt, gilt es, die Treiber systematisch zu variieren, um den Effekt, den jeder einzelne von ihnen verursacht, herauszufinden. Zusätzlich existieren immer externe Ursachen, die man nicht selbst variieren kann. Diese muss man zumindest messen, um hinterher zu kontrollieren, ob einer der Effekte vielleicht durch einen parallel laufenden, externen Faktor verursacht wurde.
Haben die jeweiligen Ursachen nur zwei grundsätzliche Ausprägungen wie „niedrig und hoch“ oder „ja und nein“, so kann man bei zum Beispiel zehn Ursachen die Anzahl ihrer Kombinationen für die Messung ihrer alleinigen Wirkung auf elf begrenzen. Die Zahl steigt leider, wenn es mehr Ausprägungen werden. Und sie steigt weiter deutlich: Will man gleichzeitig die Interaktionen zwischen Ursachen erfassen, so ergeben sich mehr Kombinationen. Als Interaktion bezeichnet man die Tatsache, dass eine Ursache die Art und Weise, wie eine andere Ursache wirkt, beeinflussen kann.
Ein typisches Beispiel: Die Erfolgsfaktoren für das Wachstum einer Pflanze sind Wasser und Sonne. Wasser allein hat keinen positiven Einfluss, solange kein Licht vorhanden ist. Ist zu viel Sonne da, verbrennt die Pflanze, selbst wenn reichlich Wasser zur Verfügung steht. Die beiden Erfolgstreiber beeinflussen sich gegenseitig in ihrer Wirkung.
Will man die Interaktionen von zwei Treibern mit zwei Ausprägungen messen, ergeben sich vier (22) weitere Kombinationen. Hat man jedoch zehn Treiber und zehn Ausprägunngen hat man 10 Milliarden Kombinationen (1010).
Wie man sieht, wird es noch schlimmer, wenn die Treiber mehr als nur zwei Zustände (ja/nein) annehmen können. Dann steigt die Komplexität derart stark, dass man Interaktionen nur noch sehr selektiv begutachten kann. Auch für die Analyse der separaten Einflüsse je Treiber, muss man höhere Mathematik anwenden. Man erstellt dann so genannte orthogonale Designs[1].
- Schritt 3: Durchführen, Wiederholen und Auswerten:
Steht das experimentelle Design, geht es in die Durchführung. Hierbei kommt es es unter anderem darauf an, dies „sauber“ zu tun. Als Negativbeispiel kann das berühmte „zählende Pferd“ gelten. Sein Besitzer war fest davon überzeugt, dass sein Tier zählen konnte. Dies bestätigten viele Augenzeugen. Als Wissenschaftler dem „Wunder“ nachgingen, brach für den Besitzer eine Welt zusammen. Sein Ursprungsexperiment sah wie folgt aus: Er sagte dem Pferd eine Zahl, und das Pferd begann daraufhin, solange mit den Hufen zu schlagen, bis die Zahl erreicht war. Das funktionierte auch tatsächlich wie von Zauberhand. Leider hörte das Pferd nicht deswegen auf zu klopfen, weil die genannte Zahl erreicht war, sondern weil der Besitzer beim Erreichen aufschaute. Das Pferd hatte gelernt: Wenn es aufhört zu klopfen, sobald sein Besitzer den Blick von seinen Hufen nimmt, gibt es als Belohnung „lecker Möhrchen“.
Externe Faktoren und Korrelate während des Experiments können also leicht verfälschen. Dies gilt es immer zu beachten. Weiterhin müssen in der Regel für jede Kombination der Ursachen mehrere Versuche durchgeführt werden. Die Anzahl hängt ein wenig von der Streuung der Ergebnisse ab. Wenn ich mir mit dem Hammer aus Testgründen auf den Finger haue, um den Effekt zu untersuchen, dann wird das Ergebnis sehr konsistent sein. Im Allgemeinen gelten aber die klassischen Regeln der Statistik. Als Daumenregel aus der Praxis gilt (Statistiker würden mich für diese Aussage steinigen), dass ein Mittelwert aus 35 Erfahrungswerten eine brauchbare Stabilität ergibt.
Brauchbar bedeutet, dass die Ergebnisse zwar stark schwanken können, jedoch die abgeleitete Entscheidung die gleiche und daher stabil ist. Letztlich hängt die nötige
Stichprobe davon ab, ob eher Tendenzaussagen oder genauere Ergebnisse gefordert werden. Wenn ich wissen will, ob ein Hammerschlag weh tut, muss ich nicht genau die Schmerzintensität messen. In diesem Fall werden wenige Schläge reichen, um zu brauchbaren Ergebnisse zu kommen. Möchte ich hingegen wissen, ab welcher Grenze der Schmerz nicht mehr auszuhalten ist, muss ich meinen Daumen erheblich öfter malträtieren.
Digitale Spürhunde: Die multivariaten Ursachenanalyse-Verfahren
Auch Daten von Experimenten bedürfen einer nicht trivialen Auswertung, wenn mehrere Ursachen zeitgleich variieren. Genau dann hilft die deskriptive Statistik mit einfachen Kennzahlenvergleichen nicht mehr weiter.
Leider stößt das Experiment schnell an die Grenzen praktischer Machbarkeit. Oft finden wir in der Praxis 10, 20 oder gar 50 potenziell relevante Einflussfaktoren, die sich zudem meist nicht auf binäre (hoch/niedrig) Niveaus begrenzen lassen. Je strategischer die Fragestellung ist, desto teurer wird außerdem das Experiment. Wie teste ich im Experiment eine Unternehmenspositionierung? Wie eine Segmentierung? In vielen Fällen werden die Kosten für ein Experiment prohibitiv hoch. Sie werden teurer als die Kosten einer Fehlentscheidung.[2]
In solchen Fällen brauchen wir jenseits des Experiments andere Methoden – Methoden, die anhand von Daten praktikable Hypothesen über die Wirkung bestimmter Ursachen zulassen.
An einem einfachen praktischen Beispiel lässt sich zeigen, wie wir wahre Ursache-Wirkungs-Beziehungen aus Daten ableiten können. Dazu produzieren wir zunächst unsere Daten im Computer anhand von Excel-Formeln selbst. Denn nur so können wir sicher gehen, dass wir die tatsächliche Wahrheit – die tatsächlichen Wirkbeziehungen auch wirklich kennen.
Es geht um folgendes kleines Beziehungsnetzwerk: Werbung steigert die Absatzzahlen und der Absatz steigert die Markensympathie. Zeitgleich reduziert diese spezielle Werbung allerdings auch die Markensympathie ein wenig, da sie vom Kunden als leicht nervig wahrgenommen wird. Um dies abzubilden, schaffe ich drei Datenreihen: Ausgaben für Werbung, Absatzzahlen und Markensympathie. Diese Zahlenreihen bilde ich zufällig – also mit einem speziellen Würfel, der mir beliebige Nachkomma-Zahlen zwischen 0 und 1 ausspuckt.
Schritt eins ist die Initialisierung: Die Datenreihe für Werbung wird im ersten Schritt aus 1000 Zufallszahlen zwischen 0 und 1 erzeugt. Analog wird die Datenreihe „Absatzzahlen“ gebildet. Die Datenreihe „Markensympathie“ wird ebenso erzeugt, nur dass die Zahlen zwischen 0 und 0,5 schwanken.
Im zweiten Schritt simulieren wir die Wirkbeziehungen.
- Die resultierende Datenreihe „Absatzzahlen“ wird aus den initialisierten Werten „Absatzzahlen“ addiert mit den Werten für Werbung gebildet.
„Absatzzahlen“ = „Absatzzahlen“ – Initialisierung + „Werbung“
Die inhaltliche Bedeutung ist, dass die Absatzzahlen positiv von der Werbung beeinflusst werden. Hinzu kommen zufällige andere Einflüsse (die Initialisierungswerte).
- Die Markensympathie wird aus den dafür initialisierten Zufallswerten „Markensympathie“ plus „Absatzzahlen“ und minus der Hälfte der Zahlenreihe für „Werbung“ ermittelt.
„Markensympathie“ = „Markensympathie“ – Initialisierung + Absatzzahlen“ – „Werbung“/2
Inhaltlich bedeutet dies, dass die Markensympathie durch die Absatzzahlen positiv beeinflusst wird. Wer kauft, wird retrograd eine positivere Einstellung entwickeln. Jedoch wirkt die Werbung leicht negativ auf die Marken- sympathie. Scheinbar löst sie zwar Kaufakte aus – ist aber nicht besonders sympathisch.
Auf diese Weise erzeugt man 1000 Datensätze mit jeweils Werten für Werbung, Absatzzahlen und Markensympathie. Jetzt schauen wir uns mit Analyseverfahren diese Datensätze an und versuchen herauszufinden, wie „Werbung“ und „Absatzzahlen“ die Größe „Markensympathie“ beeinflussen.
Insbesondere interessiert uns, wie „Werbung“ auf „Markensympathie“ wirkt. Denn wie oben definiert, ist der direkte Einfluss von „Werbung“ auf die „Markensympathie“ negativ und nur der indirekte Einfluss positiv – dies, weil „Werbung“ ja den „Absatz“ positiv beeinflusst und der „Absatz“ anschließend die „Markensympathie“ verstärkt.
Jetzt berechnen wir den Korrelationskoeffizienten zwischen „Werbung“ und „Markensympathie“ und erhalten den Wert 0,42. In der Konsequenz hieße das: Je höher „Werbung“ desto höher „Markensympathie“. Schauen wir uns die Daten im zweidimensionalen Plot an.
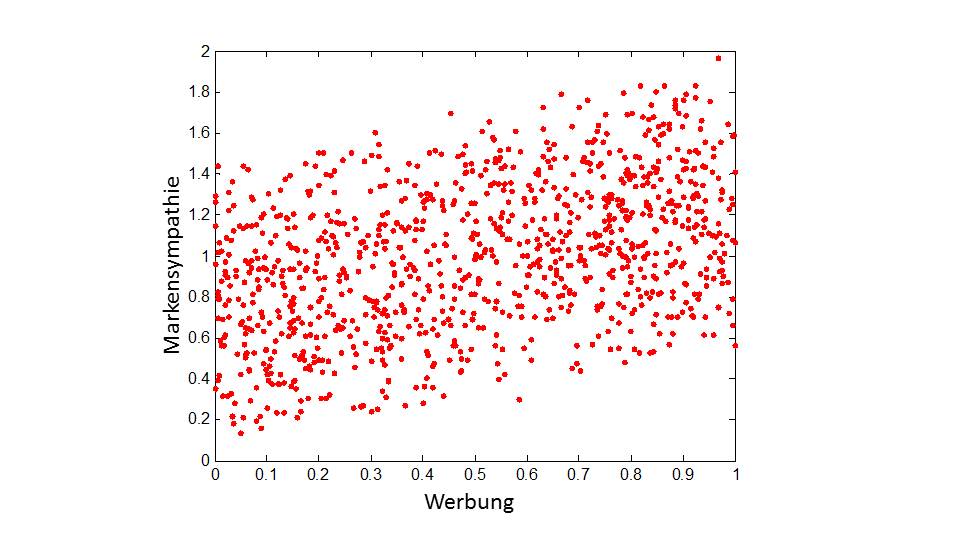
Man sieht deutlich: Je höher der Wert für „Werbung“ desto höher ist der Wert der „Markensympathie“. Doch Halt! In Wahrheit beeinflusst doch Werbung die Markensympathie negativ. Ganz offensichtlich ist diese Zweivariablen-Analyse – egal ob Korrelationskoeffizient, graphische Analyse oder andere Auswertungen – nicht geeignet, die Wahrheit aufzudecken. Keine noch so elaborierte Zauberformel wird aus den dargestellten Zahlenpaaren die Wahrheit aufdecken können. Warum? Weil wichtige ursächliche Informationen fehlen.
Irgendwie scheint diese Analyse direkte und indirekte Effekte zu vermengen. Diese indirekten Effekte können wir nur herausrechnen, wenn wir die Variablen einbeziehen, die dabei beteiligt sind. Also müssen wir die Daten nicht in einer zweidimensionalen, sondern in diesem Fall in einer dreidimensionalen Analyse anschauen. In der dreidimensionalen Betrachtung entsteht ein Analyseraum, in dem eine blaue Punktwolke dargestellt werden kann. Im zweidimensionalen Fall erkennen wir den Zusammenhang, indem wir mit dem Auge eine Linie durch die Punktwolken legen. Diese Linien zeigen im Beispiel oben nach oben – je mehr, je besser.
Haben wir jedoch eine dreidimensionale Punktwolke, müssen wir eine Ebene durch die Punktwolke legen.
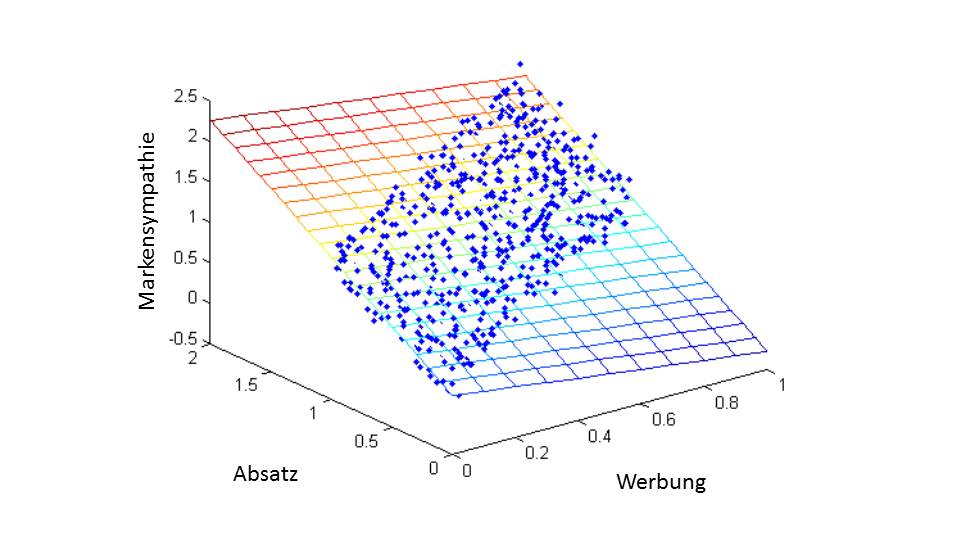
Die blauen Punkte visualisieren den gleichen Datensatz – nur dass zeitgleich die Variable „Absatzzahlen“ mit dargestellt wird. An der Neigung der Ebene kann man nun den Effekt der Variablen „Werbung“ und „Absatzzahlen“ auf „Markensympathie“ ablesen. „Absatzzahlen“ wirken klar positiv auf die „Marken-sympathie“.
Jedoch wirkt „Werbung“ negativ. Das können Sie am besten dort ablesen, wo „Absatzzahlen“ den Wert Null hat. Je größer die Zahlen für „Werbung“ sind, desto mehr nähert sich die Ebene der „Werbung“-Achse. Das heißt, dass der direkte Zusammenhang wie folgt ist: Je größer die Ausgaben für Werbung sind, desto kleiner ist die Markensympathie.
Das Legen einer mehrdimensionalen Ebene in eine mehrdimensionale Punktwolke nennt man multivariate, lineare Regressionsanalyse. Und sie ist prinzipiell für beliebig viele Treibervariablen anwendbar. Wenn Sie die dreidimensionale Grafik gedanklich so drehen, dass Sie von der Seite der „Werbung“ Seite darauf schauen, erhalten Sie wieder eine zweidimensionale Darstellung. Dies sieht dann so aus:
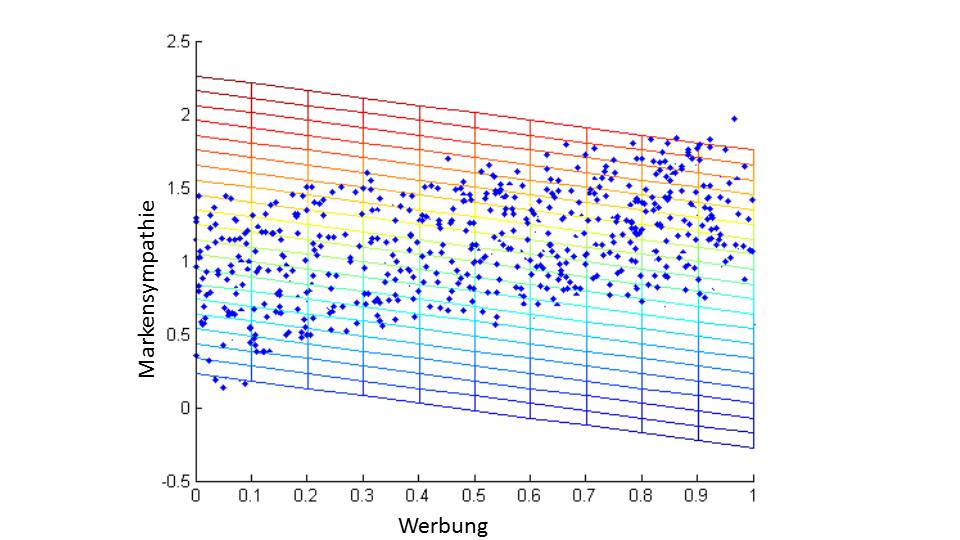
Die Punkte sind wieder genau die gleichen wie die roten Punkte in der ersten Abbildung. Die Gitter sind aus dem dreidimensionalen Graph entlehnt. Die abfallenden Linien sind Linien mit konstanten Absatzzahlen. Die Steigung entspricht genau dem Einfluss von „Werbung“ auf „Markensympathie“.
Wenn Sie bisher gewisse Probleme mit der dreidimensionalen Ebene hatten, dann seien Sie unbesorgt: Sie sind nicht allein. Meine Frau ist da auch nicht so gut darin (sie hat andere Talente). Auf Vorträgen veranschauliche ich das Ganze mit Cola-Flaschen und einem durchsichtigen Deckel von IKEA, wie das die nächste Abbildung zeigt.
Große Flaschen repräsentieren Zielkunden die eher kaufen, kleine Flaschen Zielkunden, die eher negativ denken. Der Platz, an dem die Flasche steht, sagt etwas darüber aus, wie der Zielkunde über die Marke denkt. Die lange Kante steht für den Preis, die kurze für die Markensympathie. Die kleine Flasche entspricht der Meinung Ottos, eines Kunden, der den Preis für schlecht hält und der die Marke ablehnt. Die Kundin Ilse hingegen ist mit dem Preis voll einverstanden, findet aber die Marke nur durchschnittlich. Die Regressionsanalyse legt einfach den Ikea-Deckel so auf die Flaschen, dass sie so gut wie möglich repräsentiert sind. An der Steigung der Deckelkanten kann man sehen, dass der Preis deutlich weniger wichtig ist als die Marke. So einfach ist multivariate Statistik. Nur, dass wir in der Praxis fünfzigdimensionale Deckel haben. Und weil es die nicht bei Ikea gibt, kosten die Analysen etwas mehr als ein Billy-Regal:

Die Regressionsanalyse ist eine Methode der multivariaten Ursachenanalyse. Multivariate Ursachenanalysemethoden betrachten mehrere Ursachen gleichzeitig und ermitteln in einer ganzheitlichen Betrachtung, welche Treiber welche Veränderung der Zielgröße tatsächlich verursacht haben.
Der Hauptnutzen dieser Analyse ist die Vermeidung von Scheinkorrelationen, da alle Ursachen gleichzeitig betrachtet werden. Die fatalen Folgen von falschem Wissen durch Scheinerkenntnisse haben wir bereits ausgiebig betrachtet.
Die Regressionsanalyse veranschaulicht sehr schön den Lösungsansatz unseres Problems. Jedoch muss man noch einige weitere Anforderungen erfüllen, um in der Realität gute Ergebnisse zu erzielen. Daher brauchen wir eine verfeinerte Methode, deren Anforderungen wir in Kapitel 5 diskutieren.
Die multivariate Ursachenanalyse erfordert das Vorhandensein von Daten. Experimente durchzuführen, ist kosten- und zeitintensiv. Welche Methode sollte ich in welchen Situationen anwenden und in welchen nicht?
Der Prozess unserer Methodenwahl ist in folgender Abbildung skizziert. Am Anfang steht die Statusanalyse. Was sind meine Zielgrößen, was mögliche Treiber? Welche Kosten sind zu erwarten, wenn Experimente durchgeführt werden oder Beobachtungs- oder Befragungsdaten beschafft werden? Anhand dieser Informationen kann ich entscheiden, wie sinnvoll vorgegangen werden sollte.
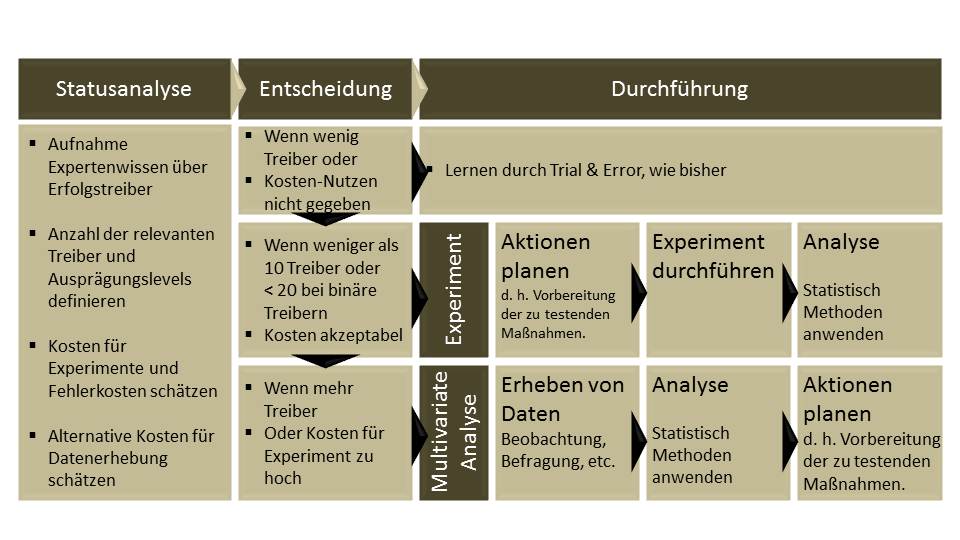
Die Tabelle zeigt, dass das übliche Trial & Error ein fester Bestandteil auch des zukünftigen Managens bleiben wird. Sie zeigt aber ebenso, dass wir um die multivariate Ursachenanalyse nicht herumkommen, wenn wir es mit vielen Ursachen zu tun haben und in der Lage sind, Erfahrungswerte in Daten zu quantifizieren. Nur mit der multivariaten Ursachenanalyse ist es möglich, Scheinerkenntnisse zu vermeiden.
Dieses Kapitel demonstriert, wie schwierig sich die Ursachenanalyse schon bei wenigen Einflussgrößen gestaltet. In unserem Beispiel haben wir nur den Absatz, die Markensympathie und die Werbung betrachtet. Wir haben gesehen, dass es selbst bei derart wenigen Parametern bereits eine so große Menge möglicher Ergebnisse gibt, dass die „ideale Dosis“ Werbung ohne mathematische Unterstützung nicht ermittelt werden kann.
Es genügt schon ein flüchtiger Blick auf die reale Marktsituation eines Unternehmens, um festzustellen, dass es hier noch viel komplexer zugeht. Das Geschäft reagiert auf saisonale Einwirkungen, auf aktuelle wirtschaftliche Entwicklungen und auf viele andere Elemente mehr. Wenn diese echten Einflussgrößen mit anderen Elementen zusammenfallen, die nur scheinbar eine Ursache darstellen, jagen wir bereitwillig und oft relativ kritiklos Gespenstern nach.
Mit anderen Worten: In der Wirtschaft benötigen wir multivariate Ursachenanalysen, um uns von den Illusionen zu lösen, dass die Dinge so oder so funktionieren. Meistens funktionieren sie ganz anders, und wenn wir eine Investition tätigen, die auf einer solchen Illusion basiert, werfen wir gutes Geld zum Fenster heraus.
Was hier aber noch Theorie ist, wollen wir im nächsten Kapitel greifbar machen, indem wir konkrete Anwendungsbeispiele betrachten. Sie werden zeigen, dass die neuen Methoden nicht nur äußerst nützlich sondern, zunehmend erforderlich sind.
[1]Für weiterführende Informationen empfehle ich das Buch „Testing 1-2-3“ von Johannes Ledolter und Arthur Swersey.
[2]Siehe dazu eine ausführliche Diskussion in Buckler/Gibson „Do Causal Models Really Measure Causation?“, in: Marketing Research Magazin, Spring 2010
KAPITEL 4
Digitale Spürhunde im Einsatz: Anwendungsfelder multivariater Ursachenanalysen
Das Experiment ist die beste Methode, wenn die Anzahl der Ursachen begrenzt ist und die vergleichsweise hohen Kosten des Experiments den Nutzen rechtfertigen. Die Anwendungsbereiche liegen in der operativen Optimierung konkreter Marketing- und Vertriebsmaßnahmen. Dort finden sich vereinzelt Aufgabenstellungen mit mittlerer Komplexität und begrenzten Kosten, die durch Fehlversuche anfallen.
Die Anwendungsfelder multivariater Ursachenanalysen ohne Rückgriff auf Experimente sind vielschichtiger und befinden sich überall da, wo Manager echtes und verwendungsfähiges Wissen über Ursachen benötigen. Wenn das Experiment nicht praktikabel erscheint, muss unbedingt auf multivariate Ursachenanalysen zurückgegriffen werden. Die Voraussetzung dafür ist die Verfügbarkeit von Beobachtungsdaten. Ein Analyseverfahren benötigt immer eine „quantifizierte Erfahrungshistorie“. Dieses Wortungeheuer ist der wissenschaftliche Begriff für das, was wir einfacher als „Daten“ bezeichnen. Oft liegen diese Daten jedoch nicht vor, sodass der erste Schritt zu einem wirkungsvolleren Management im systematischen Sammeln und Speichern von ursächlichen Größen besteht. Die Kosten dafür sind im Vergleich zum Nutzen bei wichtigen Aufgabenstellungen fast immer überschaubar.
Weil die Anwendungsfälle, in denen keine Experimente möglich sind, in der deutlichen Mehrzahl sind, möchte ich mich im Folgenden auf solche fokussieren. Dies ist umso notwendiger, da deren Anwendungsfelder und Potenziale oft nicht offensichtlich sind. Die folgenden Fallbeispiele sollen veranschaulichen, wie und warum multivariate Ursachenanalysen in der Praxis angewendet werden.
Kundenmanagement
Markterfolg ist ein Ergebnis, das viele, sehr viele Ursachen und Bedingungen hat. Es gibt Millionen von Variationen in den Maßnahmen, die man ergreifen kann.
Die Klaviatur der Kanäle unterscheidet sich stark je nach Branche. Während im Konsumgüterbereich hier insbesondere Werbekanäle gemeint sind, sind es im Industriegüterbereich hingegen eher Vertriebsunterstützungsmaßnahmen. Neben der Frage, wie viel Geld in welche Kanäle fließen sollte, ist mit dem Marketing auch immer die wichtige Frage verbunden, was konkret der Inhalt der Werbung oder der Vertriebsunterstützungsmaßnahme sein sollten. Für die inhaltliche Optimierung haben sich Experimente als beste Methode bewährt, insofern eine praktikable Positionierung und Segmentierung vorliegt – mehr dazu später. Die Verteilung des Budgets auf Instrumente und Kanäle ist jedoch in den meisten Fällen zu komplex, sodass multivariate Verfahren sinnvoll eingesetzt werden.
Fallbeispiel: Marketingbudgetverteilung im Pharmavertrieb
Ein Pharmaunternehmen, das verschreibungspflichtige Medikamente vertreibt, wollte die Verteilung seines Marketingbudgets optimieren. Marketinginstrumente sind hier die Anzahl der Besuche eines Vertriebsmitarbeiters bei verschreibenden Ärzten, die Anzahl der ausgegebenen Produktproben, die der Brand-Reminder (Kugelschreiber und andere Give-aways), Investitionen in Informationsveranstaltungen (lokale Workshops und Kongresse), für Werbeanzeigen in Fachzeitschriften und Produktproben in Krankenhäusern (dort werden Patienten auf Medikamente eingestellt, die daraufhin dauerhaft Verwender werden). Nicht zuletzt, spielt natürlich auch die Preisgestaltung eine große Rolle.
Die Situation im Unternehmen stellte sich wie folgt dar. Das Top-Management befragte das Marketing und die Vertriebsorganisation, ob diese die Wirksamkeit ihrer Ausgaben nachweisen können. Ein neues Schlagwort geisterte durch die Branche: Marketing-ROI. Leider musste man trotz vieler hoffnungsfrohen Versuche feststellen, dass dieser Return-on-invest letztlich nicht gemessen werden kann.
Doch wie wird die Budgetverteilung auf die Instrumente heute festgelegt? Meist folgt man, um es positiv auszudrücken, dem gesundem Menschenverstand. Erfahrungs-werten folgend wägt man ab und legt fest, welche Instrumente wie viel Budget erhalten. Oft hält man sich aber auch einfach daran, wie es andere machen und wie es bislang so üblich war. So unzuverlässig das anmutet, so schlecht ist es auch, und die
meisten Marketing-Manager haben Bauchschmerzen damit. Unbestritten bleibt in der Branche natürlich, dass es sinnvoll ist, Ärzte regelmäßig zu besuchen. Ob und wie viele Produktproben positiv wirken, ob und wie viele Kugelschreiber zu verteilen sind oder welche Werbung in Fachzeitschriften wann und wie zu schalten ist, ist nicht bekannt. Wenn aber, wie hier leicht zu sehen, die Wirkung der Anstrengungen unbekannt ist, kann man ziemlich sicher davon ausgehen, dass mit der klassischen Verteilung des Budgets viel Geld vergeudet wird.
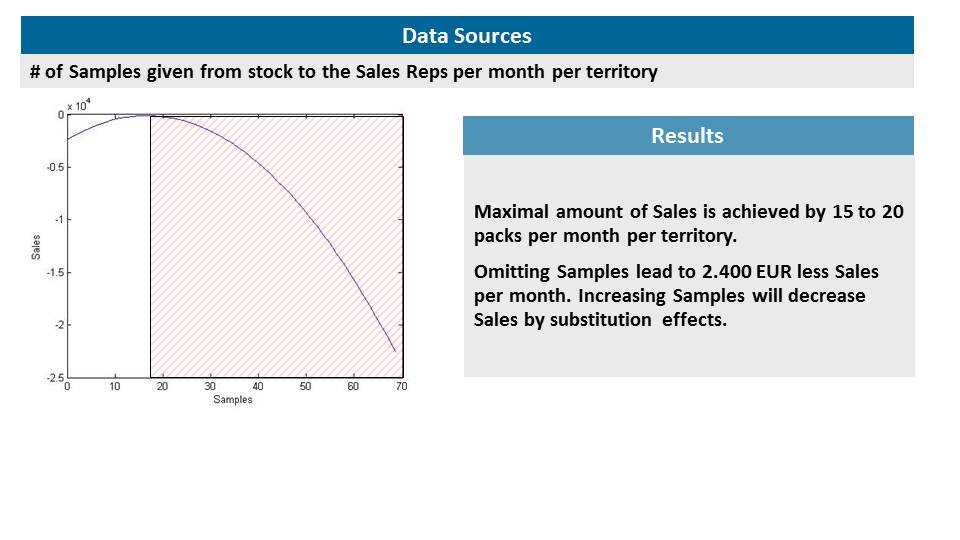
Aus diesen nachvollziehbaren Gründen startete das Unternehmen ein Pilotprojekt, in dem es den Zusammenhängen durch multivariate Ursachenanalysen auf den Grund gehen wollte. Nach einem eingehenden Auswahlverfahren wurde ich mit der Aufgaben betraut. Das Projektteam fand, wenig überraschend, heraus, dass die Wirkung vieler Instrumente schlichtweg nicht nachweisbar war. Werbung beispielsweise war wirkungslos. Brand-Reminder wie Kugelschreiber hingegen waren eine gute Ergänzung. Zudem konnte mein Team widerlegen, dass ein „Je mehr, desto besser“ bei Produktproben eine Erfolgsregel ist. Tatsächlich gibt es einen Punkt, ab dem zu viele Produktproben negative Effekte auf den Abverkauf haben. Der Grund dafür ist simpel. Wenn zu viele Proben im Umlauf sind geben Ärzte diese Proben statt einer Verschreibung an Patienten weiter. Produktproben stimulieren zwar den Abverkauf, sie substituieren diesen jedoch zeitgleich. Natürlich ist dieses Ergebnis für Branchenexperten mehr als plausibel. Jedoch waren diese Fachleute nicht in der Lage, den optimalen Punkt des Probeneinsatzes im Vorhinein zu benennen. Im Ergebnis unserer Untersuchungen konnten wir vorhersagen, dass eine Verdoppelung der Budgeteffektivität oder eine Halbierung der Marketingbudgets möglich war.
Fallbeispiel: Werbebudgetverteilung für einen Glückspielanbieter
Die Situation bei einem Glückspielanbieter war angespannt. Seit Jahren sanken die Umsätze und der Geschäftsführer fragte sich zu Recht, ob die Werbemillionen richtig investiert waren. Im Losgeschäft sind die Werbekanäle zum einen klassische Medien wie Print, Plakat und Rundfunk, aber auch Einkaufsradio in Supermärkten sowie Werbung in den Verkaufsstellen und auf Webseiten. Die Mediaplaner legten die Werbeverteilung nach allgemeinen Glaubensätzen fest. Ein bekannter Glaubenssatz lautet beispielsweise, dass Radiowerbung die am schnellsten wirkende Werbung ist. Deshalb wird sie für Kurzfristthemen, wie etwa Jackpots, massiv eingesetzt, um den Umsatz zu steigern. Welcher Werbedruck jedoch genau benötigt wird, verraten diese Glaubenssätze nicht. Kein Wunder also, dass die im Unternehmen vorliegenden Zahlen extrem unpräzise waren.
Unser Team unterschied den Medieneinsatz nach den Inhalten der Werbung. Wurde ein Jackpot beworben, war es eine Imagewerbung oder war es eine Sonderaktion? Weitere wichtige Einflussgrößen waren die Höhe des Jackpots, die aktuelle Presseberichterstattung, die konkreten Wochentage und der Zeitpunkt im Monat.
Hier ist es immer wichtig, alle Einflussgrößen in ein Modell aufzunehmen, ungeachtet der Tatsache, ob diese steuerbar sind oder nicht. Denn nur durch ein möglichst vollständiges Modell können Scheinerkenntnisse vermieden werden. Wenn beispielsweise Radiowerbung vor allem wochentags geschaltet wird, jedoch in der Woche die Umsätze üblicherweise geringer sind als am Wochenende, würde dem Radio fälschlicherweise eine negative Wirkung zugeschrieben werden. Daher kommt der sorgsamen Sammlung möglicher Erfolgsvariablen eine zentrale Rolle zu.
Das Ergebnis der Analyse zeigte überraschende Ergebnisse. Nichtklassische Medien waren um ein Vielfaches effektiver als klassische. Viele Medien interagierten stark, sodass ein kombinierter Einsatz empfohlen wurde. Überraschend war auch, dass kurzfristige Medien wie Radio nicht kurzfristig wirkten, sondern möglichst lange geschaltet werden mussten. Dies steht allerdings nur vordergründig im Widerspruch zum Glaubenssatz. Die Analyse zeigt, dass Radio lediglich die kognitive Awareness schafft. Um ein Los zu verkaufen, muss der Kunde erst einmal die Verkaufsstelle
aufsuchen. Fast niemand tut dies nur wegen des Loskaufs. Der Erwerb eines Loses ist meistens ein Impulskauf, der von der vorher aufgebauten Awareness lediglich begünstigt wird. Daher definieren die Bewegungsgewohnheiten der Zielkunden die Geschwindigkeit, mit der die Werbeeffekte greifen, und nicht das kurzfristig wirkende Radio.
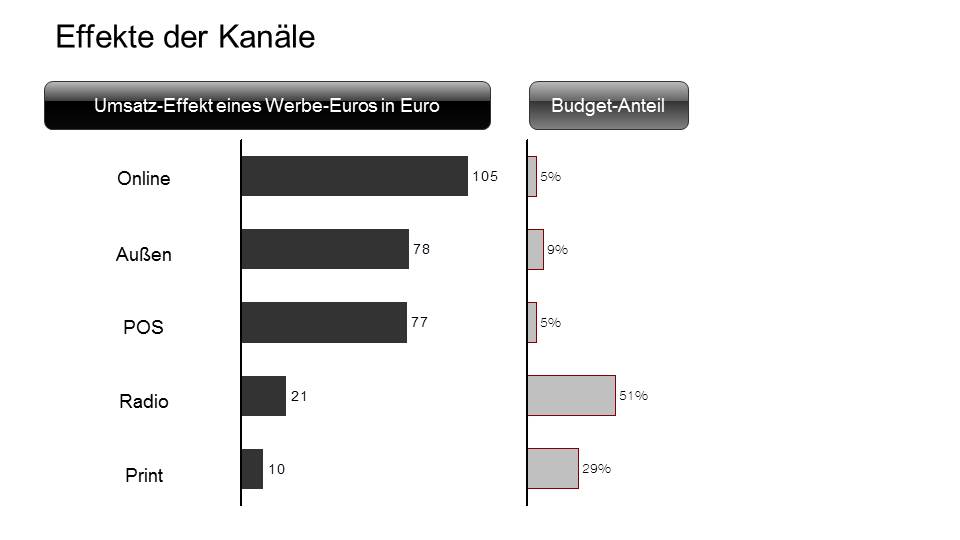
Im Ergebnis konnten wir zeigen, dass Werbung für diese Glücksspielprodukte sehr lohnend ist, dass eine Budgetumverteilung erhebliche Effektivitätssteigerungen bringt und dass darüber hinaus eine Ausdehnung des Budgets sehr empfehlenswert erscheint.
Fallbeispiel: Werbebudgetverteilung für Automobilanbieter
Als Beispiel aus dem Konsumgüterbereich ist eine Branchenstudie im Automobilbereich überaus interessant, die wir in Kooperation mit Thomson Media Control, YouGov und der Fachhochschule Münster durchgeführt haben. Ziel der Studie war es, zu untersuchen, ob der Effekt von Werbung im Automobilverkauf insgesamt nachweisbar ist und welche Potenziale für Optimierungen bestehen. Eigentlich möchte man meinen, dass der Effekt von Werbung nachgewiesen und bekannt ist. Dies ist jedoch keineswegs generell der Fall. Das räumte auch der
ehemalige Marketingvorstand der Audi AG, Michael Trautmann, vor einigen Jahren auf einer Fachtagung ein: „Ein ungelöstes Problem ist heute immer noch, dass wir in Wirklichkeit nicht wissen, ob die Gesamtheit unserer Kampagnen tatsächlich nennenswerte Effekte zeigt.“ Zwar lässt sich in Labors nachweisen, dass eine Werbeanzeige zu einem gewissen Prozentsatz erinnert wird und eine Einstellungsänderung verursachen kann. Wie sehr es jedoch tatsächlich dazu kommt, dass eine Anzeige gesehen und studiert wird oder wie der Effekt sich verstärkt, wenn ein Zielkunde gerade eine TV-Werbung gesehen hat, ist nicht bekannt.
In unserer Branchenstudie konnten wir durch die Daten von Thomson Media Control auf einen kompletten Fundus der Brutto-Werbeausgaben aller relevanten Automobilhersteller in den klassischen Werbekanälen TV, Print, Plakat und Radio zurückgreifen. Als Ergebnisgrößen dienten uns die Daten des BrandIndex der YouGov Gruppe. Dies ist ein tagesaktuelles Online-Panel, das durch die regelmäßige Befragung von 1000 Personen Rückschlüsse über die aktuelle Markenstärke zulässt. Beide Datensätze zusammen erlauben es, den Effekt der Werbung auf die Markenstärke zu analysieren.
Tatsächlich konnten wir durch unsere Ursachenanalyse-Methoden zwanzig Prozent der Verbesserungen im Bereich Markenstärke durch Werbeausgaben erklären. Dies ist im Vergleich zu den herkömmlichen Methoden, die genau ein Prozent erklären, extrem viel. Andererseits zeigten unsere Untersuchungen natürlich auch, dass ein erheblicher Teil (achtzig Prozent) durch andere Ursachen ausgelöst wurde. Hierzu zählten die Art der Werbung (etwa Imagewerbung vs. Produktwerbung), die Werbegestaltung, nichtklassische Medienausgaben oder externe Effekte.
Es sprach für uns, dass die vergleichsweise hohe Erklärungsgüte nur durch den Einsatz unserer hochentwickelten Analysemethoden möglich war. Der Grund dafür liegt darin, dass die Wirkungen der Kanäle sich in hohem Maße gegenseitig beeinflussen und sogenannte Interaktionseffekte auftreten. Weiterhin zeigen viele Kanäle Sättigungseffekte, durch die der Wirkungsverlauf nicht linear ist. Herkömmliche Analyseverfahren nehmen jedoch die Unabhängigkeit von Einflussgrößen an, indem keine Interaktionseffekte erlaubt sind. Außerdem nimmt man der Einfachheit halber einen linearen Zusammenhang an. Deshalb glaubt man am Ende fälschlicherweise, dass mehr immer auch besser ist. Da mehr aber auch immer mehr Geld bedeutet, ist bei einem Prozent Vorhersage leicht absehbar, dass hier Budgets verpulvert werden.
Zu guter Letzt haben wir in der Branchenstudie untersucht und simuliert, welche Effizienzpotenziale bestehen. Dazu haben wir betrachtet, welchen Effekt die Ausgaben an den 50 Prozent effektivsten Werbe-Tagen hatten. Wir stellten fest, dass jede Marke ein Potenzial zur Steigerung der Effektivität von ca. 100-200 Prozent besitzt. Diese Erkenntnis bestätigt das alte Zitat von Henry Ford, der schon wusste, dass mindestens die Hälfte aller Werbegelder verschwendet ist. Multivariate Methoden geben uns die Möglichkeit, zu erfahren, welche Hälfte das ist. Die Optimierung eines Werbebudgets ist eine Problemstellung, die in Bezug auf Unternehmen und Branche immer sehr konkret und individuell angegangen werden sollte, um wirksame Ergebnisse zu erhalten. Angesichts der enormen Investitionen in Marketingaktivitäten ist es in diesem Bereich mehr als lohnend, mit Hilfe von multivariaten Ursachenanalysen Optimierungen vorzunehmen.
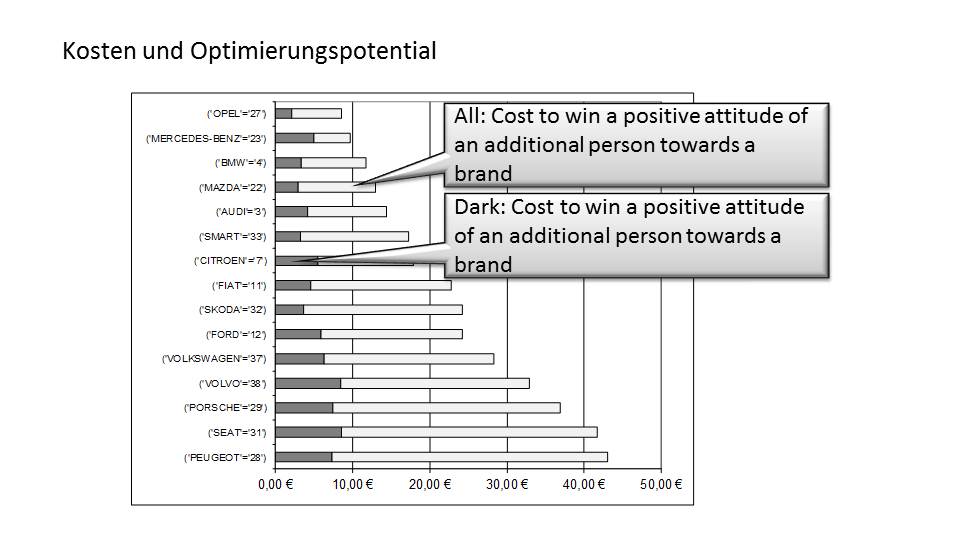
Fallbeispiel: Adoption von Neuprodukten im Mobilfunk
Ein Mobilfunkanbieter hatte Mobile-Payment- und Mobile-Wallet-Servicekonzepte entwickelt und wollte die Erfolgsfaktoren für einen erfolgreichen Produktlaunch untersuchen. Früher hatte man Probanden hierfür im Rahmen einer Befragung Produktkonzepte vorgelegt und diese um eine Bewertung des Produkts gebeten.
Im aktuellen Projekt ging man wieder so vor: Man beschrieb dem Befragten sehr konkrete Ideen mobiler Bezahlservices und fragte dessen Interesse an einer Nutzung ab. Im Weiteren bat man den Probanden, das Angebot bezüglich definierter Nutzenkomponenten zu bewerten. Nach der Adoptionsforschung sind dies Kriterien aus den Bereichen:
- empfundener Produktvorteil: etwa schneller als heute bezahlen können und andere
- Kompatibilität mit konkreten Lebensumfeld und Verhaltensweise: dass es zum Lifestyle passt, neue Bezahlmethoden zu verwenden
- Einfachheit: Die Handhabung ist intuitiv verständlich
- Kosten und Aufwand: Die Kosten der Anwendung sind vergleichsweise gering
- empfundenes Risiko: unter anderem Befürchtungen, dass das neue System gehackt und missbraucht werden könnte
Im Projektteam des Unternehmens befand sich ein Manager, der das Projekt als Basis seiner MBA-Theses verwendete und daher bestrebt war, methodisch fortgeschritten vorzugehen und Fehler der Vergangenheit aufzudecken. Im Laufe seiner Forschung wurde ihm bewusst, dass die Anwendung multivariater Methoden notwendig war. Aufgrund von Ungereimtheiten im Umgang mit herkömmlichen multivariaten Methoden wandte er sich an mich.
Gemeinsam setzten wir eine innovative multivariate Methode ein und kamen zu erstaunlichen Erkenntnissen. Interessant war in dieser Studie wieder, dass deskriptive Analysen systematisch in die Irre führten. Würde man sich nur an der Wichtigkeit orientieren, welche die Befragten selbst angaben, würden das Risiko (sprich: die Sicherheit) und die Einfachheit als zentrale Erfolgsfaktoren im Fokus stehen. Die multivariate Analyse ergab jedoch, dass die Kompatibilität der zentrale Faktor ist, ohne dass den Befragten selbst dies bewusst gewesen wäre. Diese Analysen können statistisch nachweisen, dass ein Produktinteresse zu fast 50 Prozent darauf zurückzuführen ist, dass das Produkt kongruent mit dem Lebensumfeld der Zielkunden ist. Daraus folgend galt es, die erfolgversprechendsten Touchpoints, Nutzergruppen und Anwendungssituationen zu erarbeiten.
Weiterhin zeigte sich in der deskriptiven Analyse, dass Kunden, die das Produkt wählen würden, sehr viel deutlicher den relativen Produktvorteil wahrnahmen. Ein sehr plausibles Ergebnis, oder? Leider zeigt die multivariate Analyse, dass der relative Produktvorteil durch eine eher emotionale Wahrnehmung der Einzigartigkeit des Angebots getrieben ist. Die interessierten Kunden wählten das Produkt also besonders deshalb, weil es etwas Neues und Besonderes ist. Und weil sie es gut fanden, attestierten sie dem Angebot einen Produktvorteil – nicht andersherum. Aus diesem Grund macht es Sinn, das Produkt emotional und nicht primär rational zu vermarkten. Die Einsicht in die wahren Ursache-Wirkungs-Zusammenhänge führt wieder einmal zu vollständig anderen Handlungsempfehlungen.
Fallbeispiel: Kundenbindung eines Telekommunikationsanbieters
Der grundsätzliche Ansatz einer Kundenbindungsanalyse ist es, herauszufinden, welche Produkt- und Servicefaktoren zur Kundenbindung führen. Umgangssprachlich wird dies oft so übersetzt: „Was ist dem Kunden wichtig?“ Diese Frage stellt sich jedoch als mehrdeutig und nicht trivial heraus. Es ist ein Unterschied zu fragen: „Was ist dem Kunden wichtig?“ oder: „Welche Verbesserung wird am effektivsten zu mehr Kundenbindung führen?“ Fragt man Kunden, ob ein Airbag im Auto wichtig ist, werden dies die meisten dies sehr bejahen. Ein größerer Airbag oder die Erhöhung der Airbaganzahl bringt heute jedoch nur marginale Kundenbindungseffekte. Dieses Beispiel zeigt, dass es Sinn hat, sich genau zu überlegen, was man eigentlich wissen will. Je nach Frage ist ein anderer Forschungsansatz notwendig.
Heute sind Befragungen zur Kundenzufriedenheit in vielen Unternehmen etabliert. Alle wollen wissen, wie zufrieden und wie loyal die Kunden sind. Die viel entscheidendere Frage, die sich dann zwangsläufig anschließt, aber lautet: Wie erhöht man die Kundenbindung? Natürlich versprechen professionelle Marktforscher eine Antwort auf diese Frage. Jedoch beschränken sie sich dabei fast immer auf die Anwendung deskriptiver oder bivariater (nur auf zwei Faktoren basierender) Analysen. Man analysiert beispielsweise, wie stark die Einschätzung der Leistung des Unternehmens in einem Produktkriterium mit der Kundenbindung korreliert.
Alternativ zeigen andere, wie sich loyale Kunden in der Einschätzung der Leistung des Unternehmens in einem Produktkriterium von nichtloyalen Kunden unterscheiden.
Beides sind deskriptive bzw. bivariate Analysen und führen zu stark verfälschten Ergebnissen. Überlegen Sie einmal, wie viele der Analysen in Ihrem Unternehmen auf dieser Art von Analysen beruhen. In den meisten Unternehmen sind es 95 bis 100 Prozent. Obwohl diese Analysen ein hohes Risiko besitzen, falsch zu sein, werden sie trotzdem angewendet. Dies ist so, weil diese einfachen Analysen intuitiv verständlich sind und deshalb einfach erklärt und kommuniziert werden können. Meiner Meinung nach ist es für einen Marktforschungsdienstleister ethisch nicht vertretbar, derart verzerrte Analysemethoden zu empfehlen, nur weil diese sich verkaufen lassen. Falsche Ergebnisse werden nicht dadurch richtig, dass man sie gut verstehen kann. Die Marktforschungsbranche verpflichtet sich seit Jahrzehnten auf ethische Standards (ESOMAR Standards).
In diesen bezieht man sich jedoch nur auf die Datenerhebung. Meines Erachtens gehört es zu einer ethisch korrekten Beratung, den Kunden vollumfänglich über die erheblichen Risiken von bivariaten Analysen aufzuklären. Dies bleibt heute in den meisten Fällen aus.
Genauso verhielt es sich im Fall eines großen Telekommunikationskonzerns. Hier wendete man seit Jahren ein Kundenbindungsbefragungsinstrument an, das ausschließlich auf deskriptiven Auswertungen beruhte. Als Basis diente die unterjährige Befragung einer großen Zahl von Kunden und Nichtkunden in jedem Land. Neben einem Konstrukt, das die Kundenbindung misst, werden Bindungstreiber auf zwei Ebenen gemessen. Die Treiber der ersten Ebene messen allgemeine Größen wie die Zufriedenheit mit der Netzqualität, mit den Tarifen, dem Service im Call Center oder etwa dem Service im Shop.
Auf der zweiten Ebene geht man etwas mehr ins Detail. So wird der Gesamtpreis in den Tarif je Telefonat, je SMS oder der Internetnutzung unterteilt. Durch das zweistufige Modell reduziert man auf der ersten Ebene die Komplexität der Analyse und erhöht so die Güte der Ergebnisse. Zeitgleich ermöglicht man detaillierte Erkenntnisse über die Treiber der zweiten Ebene und erhält so sehr konkrete Handlungsanweisungen.
Die Marktforschungsabteilung war mit der Erklärungskraft ihres Modells nicht zufrieden und wollte prüfen, ob neue multivariate Ursachenanalysen sinnvolle und zeitlich stabile Ergebnisse mit hoher Erklärungskraft liefern können.
Der Informationsgewinn durch multivariate Analysen lässt sich zeigen, indem man untersucht, wie sehr das Modell erklären kann, warum nichtloyale zu loyalen Kunden werden. Die Erklärungsgüte von bivariaten und multivariaten Modellen kann man mit sogenannten Scoringmodellen bestimmen. In diesen Modellen liegt der Informationsgehalt von multivariaten Analysen gegenüber bivariaten Analysen um über 200 Prozent höher!
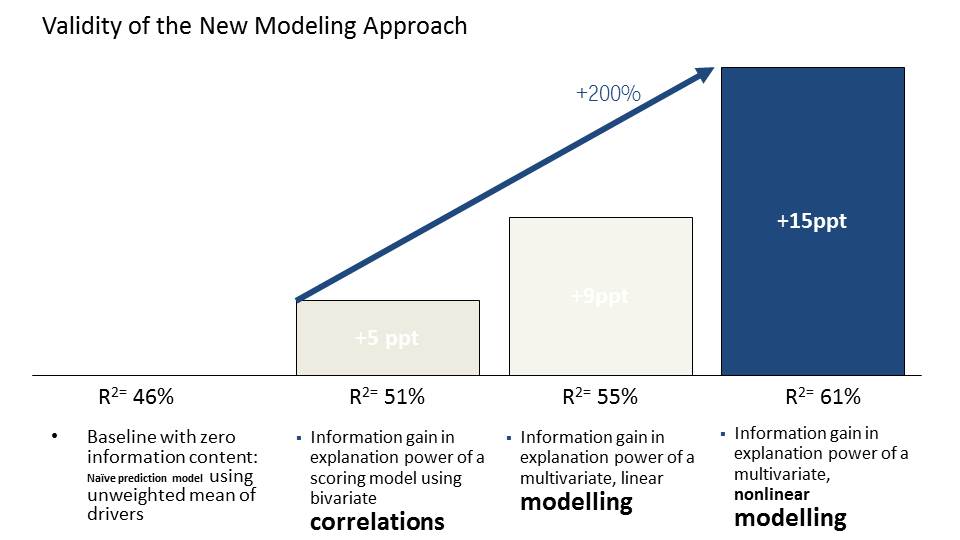
Das bedeutet, dass statistisch gezeigt werden kann, dass multivariate Analysen in einem deutlich höheren Ausmaß richtige Ergebnisse produzieren. Wenn man bedenkt, dass mit falschen Ergebnissen Folgekosten verbunden sind, sollte dies Motivation genug sein, auf neuartige Analysemethoden umzusteigen.
Der Informationsgewinn spiegelt sich in besseren Ergebnissen wieder. Darüber hinaus führen die Ergebnisse auch dazu, dass erheblich weniger Faktoren wirklich wichtig sind. Gute und richtige Analysen decken den Pareto-Charakter realer Systeme auf. 20 Prozent der Erfolgstreiber sind oft für 80 Prozent der Kundenloyalität verantwortlich. Schaut man sich die üblichen Korrelationen an, wird man dies nicht
finden. Die meisten Faktoren korrelieren ganz gut, weil sie sich gegenseitig beeinflussen und so einen gewissen Gleichlauf (eine sogenannte Multikollinearität) ausbilden. Die wahren Ursachen jedoch können nur durch multivariate Verfahren offen gelegt werden. Die folgende Abbildung zeigt, dass in unserem Beispiel die Top-2-Treiber der multivariaten Analyse die Kundenbindung zu über 50 Prozent besser erklärten als das bisherige Korrelationsmodell.
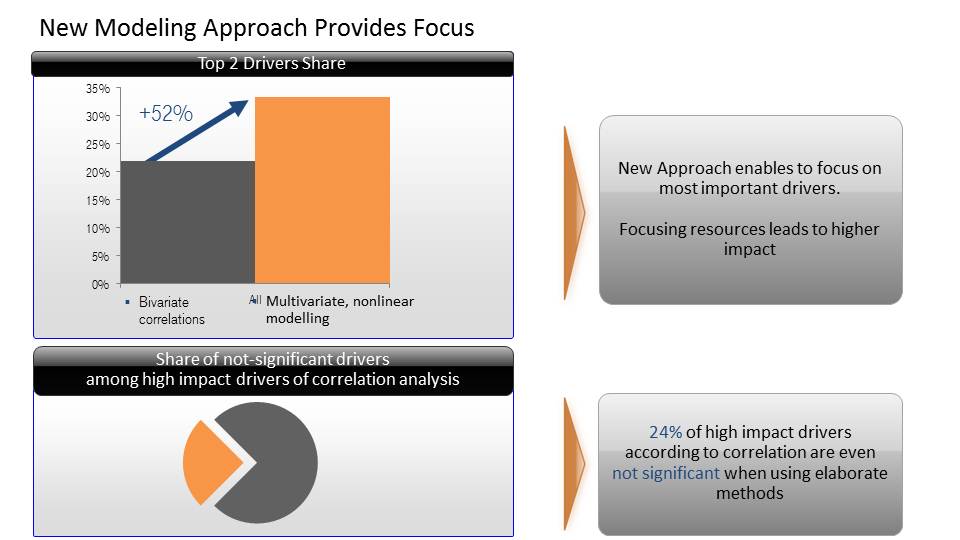
Warum ist das so wichtig? Ganz einfach, weil Ressourcen begrenzt sind. Darum hat es großen Sinn, Verbesserungsmaßnahmen auf wenige Projekte zu fokussieren. Wenn wir Analysemethoden haben, die uns besser sagen, welche wenigen Faktoren 80 Prozent des Effekts verursachen, dann wird der Effekt unserer limitierten Ressourcen deutlich höher ausfallen. Fokussierung heißt bessere Ergebnisse. 50 Prozent mehr Fokus kann 50 Prozent und mehr Effekte bedeuten.
Natürlich sind die Ergebnisse solcher Kundenloyalitätsstudien nicht der Weisheit letzter Schluss. Grundsätzlich ist es gar nicht möglich, absolute Sicherheit über Ursache-Wirkungs-Zusammenhänge zu erlangen (vgl. Karl R.Popper). Der eigentliche Punkt ist, dass gute Empirie der einzige Weg zu brauchbarem und zuverlässigem Wissen ist. Das wusste schon Kant, und das stimmt auch heute. Es geht nicht darum,
die absolute Wahrheit zu finden – denn das ist unmöglich. Die zentrale Aufgabe lautet, nützlicheres Wissen zu erlangen als wir es derzeit besitzen. So gibt es eine Reihe von Forschungsansätzen, mit denen man die Validität und Nützlichkeit der Ergebnisse weiter erhöhen kann. Ein Ansatz ist der Wechsel zu Zeitreihenanalysen. Heute werden Kunden meist zu einem Zeitpunkt befragt. Da Ursachen immer vor der Wirkung auftreten, kann Kausalität besser nachgewiesen werden, wenn man die Treiber und Effekte zu mehreren Zeitpunkten misst und entsprechend auswertet. Tritt eine Größe konsistent zeitlich vor einer anderen auf, so kann Kausalität gefolgert werden, solange das Modell vollständig ist (vgl. Clive Granger).
Besonders präzise werden die Erkenntnisse dann, wenn es gelingt, ein Panel, in diesem Fall eine feste Gruppe von Personen, regelmäßig zu befragen. Dadurch kann man an jeder Person beobachten, welche Situationsprofile heute zu steigender oder morgen zu sinkender Loyalität führen. Noch weiter steigern lässt sich die Nützlichkeit solcher Loyalitätsanalysen, indem man über die Erhebung von Einschätzungen und Teilzufriedenheiten von Kunden hinausgeht. Denn dies sind streng genommen alles auch nur Ergebnisgrößen. Letztlich sind immer Maßnahmen Ursachen für Effekte. Daher gibt es Ansätze, in denen man zusätzlich Maßnahmen zählt und quantifiziert und diese Daten mit den Effekten der Befragungen in einer multivariaten Analyse verbindet.
Fallbeispiel: Preisbereitschaft im B2B-Vertrieb hebeln
Im Industriegüterbereich sind viele Produktmärkte commoditisiert: Die Produkte der Wettbewerber unterscheiden sich kaum. Unabhängig davon ist der Preis auch und gerade hier der wichtigste Gewinnhebel, da jeder Euro mehr eins zu eins in den Gewinn geht. Ein Unternehmen, das Industrieverpackungen herstellte, hatte dies erkannt. Die Frage war nur, wie finde ich den richtigen Preis, wenn meine Produkte sich kaum vom Wettbewerb unterscheiden? Interessanterweise konnte man beobachten, dass einige Kunden deutlich mehr für das gleiche Produkt bei gleichen Abnahmemengen bezahlten als andere. Woher kamen diese individuellen Unterschiede in der Zahlungsbereitschaft? Bisher gestaltete man den Preis unter Berücksichtigung des Einzelfalls. Das ist sicher kein schlechter Ansatz, wenn man die richtigen Hypothesen hat. Beispielsweise glaubte man, dass zentrale
Einkaufsabteilungen grundsätzlich weniger zu zahlen bereit sind oder dass bei teureren Produkten auch die Verpackung teurer sein durfte oder gar musste. Beide Beispiele für Wirk-Hypothesen stellten sich als falsch heraus.
Ist ein Unternehmen in der Lage, die zentralen Treiber der Zahlungsbereitschaft zu verstehen, kann es die individuelle Preisgestaltung deutlich profitabler gestalten. Für diesen Zweck habe ich im Auftrag des Verpackungsunternehmen ein sogenanntes „Willingness-To-Pay“-Analysemodell entwickelt. Das Vorgehen ist schnell umrissen: Im ersten Schritt wurde anhand von Experteninterviews eine umfangreiche Longlist von über 20 möglichen Treibern erarbeitet wie etwa „Wettbewerbsvorteil“, „Kundenloyalität“, „Verhandlungskompetenz“ oder „Bedarfsvolumen“. Danach wurden alle großen und mittleren Kunden anhand dieser Kriterien bewertet und zugleich der Deckungsbeitrag des Kunden als Zielgröße und Indikator für die Höhe des Preises aus der Unternehmensdatenbank bezogen. Mit Hilfe eines geeigneten multivariaten Analyseverfahrens konnte mit Hilfe dieser Daten der Zusammenhang zwischen möglichen Ursachen und dem Preisniveau ermittelt werden. Die Nutzung des Modells erfolgt auf zwei Wegen.
Zum Ersten ergibt die Analyse interessante generelle Hinweise über die Hintergründe der Preisbereitschaft. Dabei stellte sich auch heraus, dass von der Longlist überhaupt nur für sechs Ursachen eine Wirkung nachgewiesen werden konnte. Zudem wird der Löwenanteil der Varianz durch einen einzigen Faktor erklärt. Die Ergebnisse zeigen also wieder ein deutliches Pareto-Prinzip. Die für die meisten Experten als wichtig erachteten Treiber stellten sich als vermutlich nicht relevant heraus.
Die zweite Verwendung der Analyse liegt in einem konkreten Diagnosetool. Auf Basis der gemachten Kundenbewertung kann das Tool die potenzielle Preisbereitschaft prognostizieren, wobei das Preisniveau durch den Rohertrag (Preis abzüglich Materialkosten) in Prozent gemessen wird. Die Differenz von prognostiziertem und tatsächlichem Rohertrag zeigt an, ob Potenzial für Preiserhöhung besteht oder ob die Preisschraube vielleicht schon überzogen wurde.
Das Schöne an einem solch hochentwickelten Tool ist, dass es sehr gut von der Vertriebsmannschaft aufgenommen und genutzt wird. Denn zum einen basieren die Prognosen auf den eigenen Einschätzungen. So war es auch in diesem Verpackungs-unternehmen. Weiterhin gab der Vertrieb das Feedback, dass das Tool die viel ersehnte „moralische“ Unterstützung beim Angehen von zusätzlichen Preiserhöhungen bereitstellte.
Kundenmanagement zusammengefasst
Schauen wir zusammenfassend auf die beispielhaft genannten Modelle, so finden wir Neuprodukt-Adoptionsmodelle und Kundenbindungsanalysen, die in den Bereich des Produkt- und Service-Managements gehören. Die Marketingbudget-Optimierung verbesserte die Effizienz der Verteilung von Ressourcen auf diverse Kommunikationskanäle und gehört in den Bereich Promotion. Das Willingness-To-Pay-Tool gehört in den Bereich „Price“.
Auch im Bereich „Place“, also der Distributionspolitik, finden sich neben dem Vertriebsmanagement weitere Anwendungsfälle. Die Wahl eines Standortes beispielsweise ist eine sehr wichtige Entscheidung, da mit ihr hohe Investments verbunden und Lock-In-Effekte die Folge sind. Die Entscheidungskriterien sind sehr vielfältig und unterscheiden sich stark je nach Anwendungsfall. In einigen Branchen, besonders dem Einzelhandel, ist die Standortwahl an der Tagesordnung und ein entscheidender Erfolgsfaktor.
In diesem Fall lohnt es sich, eine eigene Datenbank mit Erfolgsfaktoren und Erfolgsgrößen aufzubauen und anhand dieser Datenbank, die eigene Fähigkeit zur Standortwahl zu verbessern. Diese Datenbank kann durch Daten aus öffentlichen oder professionellen Quellen (Beispiel: www.contor.org) ergänzt oder gespeist werden. Es ist ersichtlich, dass in allen Bereichen des Marketings diverse Problemstellungen mit multiplen Ursachen existieren, die durch gute Methoden besser gemanagt werden können.
Positionierung und Segmentierung sind ebenfalls komplexe Marketingthemen, die brauchbares und zuverlässiges Wissen voraussetzen und eng mit dem Thema Kundenmanagement verknüpft sind. Diese Themen werden typischerweise als strategischer Überbau betrachtet. Daher werde ich auf Fallbeispiele zu diesen Themen in einem separaten Abschnitt eingehen.
Einkauf und Personalmanagement
Neben dem Management von Kundenbeziehungen in Marketing und Verkauf finden sich komplexe Zusammenhänge ebenfalls in anderen Managementbereichen – beispielsweise im Management der Mitarbeiter.
Im Bereich des Personalmanagements lautet eine große Herausforderung, wie die wertvollen Mitarbeiter besser an das Unternehmen gebunden werden können. Analog zur Kundenbindung ist das Gewinnen starker Mitarbeiter ein sehr teurer, zeitaufwändiger und risikobehafteter Prozess, wodurch allen Maßnahmen zur Mitarbeitertreue große Bedeutung zukommt. Aus diesem Grund sind in vielen Unternehmen Mitarbeiterbefragungen üblich.
Man möchte den Status-Quo erfassen und erfahren, wie zufrieden und motiviert die Belegschaft ist. Ein solches Ergebnis ist aber immer nur ein Stimmungsbarometer und verrät bestenfalls, dass man etwas unternehmen muss, nicht aber was. Viel wichtiger für die Personalarbeit ist es, zu erfahren, welche Faktoren verbessert werden sollten, um den größtmöglichen Bindungseffekt bei begrenztem Mitteleinsatz zu verursachen.
Fallbeispiel: Mitarbeiterzufriedenheit bei Krankenhausärzten
Deutsche Krankenhäuser stehen vor der Herausforderung, profitabel sein zu müssen ohne den Preishebel selbst in der Hand zu haben. Sowohl die Bezahlung der Leistungen als auch die Gehälter der Mitarbeiter sind weitgehend festgelegt. Auch und gerade wegen des geringeren Einstiegsgehalts sind beispielsweise Assistenzärzte sehr begehrt. Doch wie gewinnen Kliniken diese Ärzte und wie schaffen sie es, dass diese jungen Ärzte gehalten werden können?
Zusammen mit der Fachhochschule Münster habe ich eine Branchenstudie durch Befragung von Assistenzärzten durchgeführt. In der folgenden Abbildung sind die Ergebnisse dargestellt. Die „direkt angegebene Wichtigkeit“ ist das, was die Befragten als wichtig angeben. „Abgeleitete Hebelwirkung“ ist das, was multivariate Ursachenanalysen als tatsächliche Hebelkraft einer Verbesserung dieses Faktors herausfinden. Man sieht sehr deutlich, dass der bei weitem wichtigste Faktor zur Steigerung der Mitarbeiterzufriedenheit das Management des Stress-Levels ist. Ganz offensichtlich ist dies den Mitarbeitern selbst aber gar nicht bewusst, denn Sie schreiben dem Faktor Stress nur eine geringe Bedeutung zu. Ähnlich verhält es sich mit dem Image des Krankenhauses, das sich immerhin als fünftwichtigster Faktor herausstellte.
Was motiviert die Mitarbeiter wirklich zum Bleiben und zum Performen?
Dies zu beantworten ist keine triviale Aufgabe. Die naheliegendste Idee ist es, die Mitarbeiter einfach zu befragen.
Und sicher kann dies aus verschiedenen Gründen nicht schaden. Allerdings zeigen wissenschaftliche Erkenntnisse, dass die Ergebnisse zum großen Teil nicht die Wahrheit sagen. Zum einen gibt es Interessengegensätze. Der Mitarbeiter hat ein Interesse daran, das Thema Geld aufzuwerfen, auch wenn weniger Geld ihn nicht zur Kündigung bewegen würde. Zum anderen ist es dem Mitarbeiter selbst nicht vollständig bewusst, was er will oder was ihn in einer hypothetischen Situation motivieren würde. Die Erkenntnisse der Neurowissenschaften zeigen, dass Handlungen und Entscheidungen immer vom emotionalen Teil des Gehirns gesteuert werden. Neueste Forschungen haben ergeben, dass ein bis sieben Sekunden, bevor Menschen glauben, eine Entscheidung getroffen zu haben, bereits im emotionalen Zentrum des Gehirns nachgewiesen werden kann, dass es zu dieser Entscheidung kommen wird. Denken und Wissen tragen bestenfalls dazu bei, Emotionen zu lenken. Doch in den meisten Fällen wissen Menschen nicht, warum sie so oder so handeln. Wenn man sie fragt, versuchen sie sich selbst einen Reim zu machen und glauben auch selbst daran.
Hintergrund ist, dass wir alle davon ausgehen, dass alles Handeln von Ich – also von einem denkenden Teil des Menschen – gesteuert wird.[1] Kurzum: Fragen Sie nicht Ihre Mitarbeiter, was sie wollen! Fragen Sie lediglich auf anonyme Weise, was diese heute wahrnehmen und wie zufrieden und loyal sie sind. Aus den Angaben hunderter Mitarbeiter können multivariate Ursachenanalysen herausfiltern, welche Faktoren bei zufriedenen Mitarbeitern zu mehr Zufriedenheit geführt haben.
Beispiele im Einkauf
Ein weiterer Unternehmensbereich, der Beziehungen mit komplexen sozialen Systemen steuern muss, ist der Einkauf. Er managt die Beziehungen zu Lieferanten und anderen Wertschöpfungspartnern. Auch hier können spiegelbildliche Aufgabenstellungen wie im Verkauf gefunden werden – jedoch stellt sich die Notwendigkeit je nach Marktgegebenheit anders dar. Oft genug spielen Unternehmen auf Käufermärkten, was die Notwendigkeit für professionelles Marketing erhöht. Ist auch der Lieferantenmarkt ein Käufermarkt, liegen die Prioritäten anders, da wir weder Lieferanten anwerben müssen noch Bindungsaktionen notwendig werden. Zentrale Herausforderung ist dann das Thema Preisfindung.
Für Industrieunternehmen, deren Löwenanteil der Ausgaben aus Materialkosten besteht, ist es hochinteressant, die Marktpreisentwicklung des Rohmaterials besser vorhersehen zu können als die anderen Nachfrager. Wenn Preise steigen werden, kann das Unternehmen frühzeitig Lagerbestände erhöhen. Wenn Preise sinken werden, können Lagerbestände minimiert und durch Rückgriff auf Spotmarktmengen tiefere Preise erzielt werden. Eine gute Preisprognose kann so die Marge eines Industrieunternehmens um ein bis drei Prozentpunkte anheben. Bei einer typischen Umsatzrendite von fünf Prozent ist dies ein massiver Beitrag und kann eine Gewinnsteigerung von bis zu 50 Prozent und mehr bedeuten.
Für ein Unternehmen der kunststoffverarbeitenden Industrie haben wir ein solches System umgesetzt. Deren Rohstoff-Silos wurden nur zu 2/3 genutzt. Die Einkaufspreise für den Kunststoff wurden jährlich verhandelt und monatlich nach
dem ICIS-Index angepasst. Auf Basis der wöchentlichen Daten des ICIS-Instituts von 2003 bis 2010 und mit Informationen diverser Indizes von Prozessvorstufen der Kunststoffe ausgestattet, konnte ein Prognosemodell erstellt werden. Die tatsächlichen Preistreiber der Zukunft waren überraschend und fanden sich nicht im vermuteten Bereich. Die Prognosen wurden dazu genutzt, um die Silokapazitäten auszuschöpfen, wenn die Preise zu steigen drohten und auf ein Minimum zu reduzieren, wenn ein Preiseinbruch zu erwarten war.
Die folgende Grafik zeigt den Zusammenhang von Forecast und tatsächlich eintretender Veränderung in der Zeit nach der Erstellung des Prognosemodells von 2010 bis 2013. Im Ergebnis konnten die Einkaufskosten in diesem Zeitraum um drei Prozent gesenkt werden.
Angesichts der immensen Einsparungsmöglichkeiten ist es großen Unternehmen anzuraten, eine eigene proprietäre Prognoseabteilung zu betreiben. Denn nur der Informationsvorsprung zählt. Öffentliche Informationen von Branchendiensten sind so wertlos wie Börsenzeitschriften und die Telebörse auf NTV. Denn diese laufen dem Trend nur hinterher.
Rohstoffprognosesysteme können analog zu Börsenprognosesystemen gestaltet werden.
Die obige Abbildung stellt das Ergebnis eines Systems zur Aktienprognose dar, das ich in den 90er Jahren zusammen mit Harun Gebhardt entwickelt habe und das heute von ihm betrieben wird. Seit dem Launch 1999 generiert das System öffentlich und täglich nachprüfbar Trefferquoten von über sechzig Prozent. Die Grafik zeigt am Beispiel des NASDAQ, wie ein ungehebeltes Musterdepot sich gegenüber dem Index entwickelt hätte.
Mit Einsatz von Derivaten (speziell Optionsscheinen) kann diese Überrendite beliebig gehebelt werden. Der Hebel wirkt natürlich auch ins Negative, wenn die Prognosen „eine schlechte Strähne haben“. Daher setzt das vorhandene Spiel-Vermögen eine natürliche Grenze für sinnvolles Hebeln.
Noch ist die Plattform www.Profit-Station.com, auf der Sie Prognosen im Abo erwerben können, ein Geheimtipp. Solange dies so bleibt, werden die Prognosen so gut sein, wie sie heute sind. Geben Sie dieses Buch also nicht aus der Hand 🙂
Strategische Unternehmensführung
Bisher wurden Beispiele behandelt aus Marketing und Verkauf, dem Personal-Management oder dem Einkauf. Immer geht es dabei um Effektivität und Effizienz.
Wie sieht es aber mit der Unternehmensstrategie aus? Kann auch die gesamte Unternehmensstrategie mit Methoden optimiert werden, die in der Lage sind, komplexe Ursache-Wirkung-Zusammenhänge aufzudecken?
Strategische Ausrichtung auf Basis der PIMS-Datenbank
Genau dieser Frage ist in den 60er Jahren General Electric nachgegangen. Der Konzern hat sich gefragt, warum profitable Geschäftsbereiche erfolgreicher sind als andere. Dies mündete in ein an der Harvard University geführtes Forschungsprojekt und eine Datenbank, die als PIMS (Profit Impact of Market Strategy) in die Geschichte der Managementwissenschaften eingegangen ist. Der Umstand, dass die Datenbank seit einiger Zeit durch kommerzielle Beratungsunternehmen (seit 2004 das Malik Management Zentrum St. Gallen) betrieben wird, hat scheinbar dazu geführt, dass sich Wissenschaft und Praxis weniger mit PIMS beschäftigen und dass viele Nachwuchsmanager PIMS gar nicht mehr kennen.
Das PIMS-Projekt hatte schnell festgestellt, dass Zusammenhänge zwischen Eigenschaften und künftigem Erfolg nur zwischen vergleichbaren Objekten feststellbar sind. Vergleichbar sind sogenannte strategische Geschäftseinheiten (SGE), die sich insbesondere dadurch definieren, dass ein bestimmtes Set an Produkten (oder Dienstleistungen) einem bestimmten Set an Wettbewerbern gegenüber steht. Streng genommen besteht ein großes Unternehmen immer aus vielen SGE. Der Erfolg muss je SGE individuell gemanagt werden, da diverse Randbedingungen unterschiedlich sein können. Aus dieser Perspektive geht es hier um Strategien für Geschäftseinheiten und nicht um Strategien für ein Unternehmen. Das Unternehmen als Ganzes fungiert als eine Art Holding und kann durch das Setzten guter Rahmenbedingungen wie finanzielle Ressourcen, adäquate Managementsysteme dem Gelingen der SGE zuträglich sein. Darum soll es hier aber nicht gehen.
Die PIMS-Datenbank besteht nun aus dem Input von über 4.000 SGE aus vier Jahrzehnten und kommt in Summe auf eine Erfahrungsbasis von über 25.000 Geschäftsjahren. In einem Interviewprozess werden bis zu 70 verschiedene Variablen aufgenommen, die von Marktexperten und Controllern der jeweiligen SGE beantwortet werden können. Die Variablen werden dann beispielsweise im sogenannten „par profitability model“ zu folgenden 30 Variablen aggregiert. Die nachfolgende Abbildung zeigt diese Variablen.
Ziel des Modells ist es, zu prognostizieren, welches Return-On-Investment und welche Umsatzrendite ein Geschäft mit ähnlichen Eigenschaften typischerweise erwarten lässt. Dies stellt den Benchmark für die Optimierung interner Prozesse dar. Ich selbst habe bereits in PIMS-Projekten mitarbeiten dürfen. Hier kam es beispielsweise vor, dass wider Erwarten eine relativ geringe Umsatzrendite von fünf Prozent für das Business angemessen war, aber eine hohe Profitabilität (ROI) über die Supply-Chain-Effizienz erzielbar war. Daraufhin wurde der Pricing-Fokus im Unternehmen überdacht, der in der Vergangenheit zu Marktanteilsverlusten und anschließenden Preiskämpfen geführt hatte.

Ein weiterer Output des PIMS-Modells ist die Ermittlung von Erfolgstreibern. Man geht der Frage nach, an welchen Schrauben gedreht werden muss, um den ROI zu erhöhen. Die Antwort darauf liefern wieder multivariate Analysemethoden. Ein vereinfachtes Verfahren, das gute Ergebnisse liefern kann, ist die Look-Alike-Analyse. Findet man genügend SGE mit ähnlichem Profil in der Datenbank, kann man auswerten, wie diese sich in den darauffolgenden Jahren entwickelt hatten. An den erfolgreichen Look-Alikes kann man sich dann orientieren. Diese Analyse liefert jedoch nur unter zwei Bedingungen richtige Ergebnisse. Erstens sollten die SGE wirklich sehr ähnliche Eigenschaften haben. Hier kommt man selbst bei 4000 Unternehmen schnell an die Grenzen. Zum zweiten sollten zur Berechnung der Ähnlichkeit nur relevante Faktoren berücksichtigt werden. Ähnlichkeit auf Basis irrelevanter Faktoren ist willkürlich und wird den Beitrag der relevanten Faktoren überdecken und verzerren. Welche Faktoren relevant sind, sagen uns nur multivariate Analyseverfahren.
Manche Manager haben Vorbehalte gegenüber PIMS. Sie fragen sich, wie ein so quantitatives und statistisches Modell die Vielschichtigkeit der Realität abbilden kann. Kritisch sein ist immer sinnvoll – auch gegenüber PIMS. Sucht man jedoch nach alternativen Methoden, die anerkannten Kriterien über die Brauchbarkeit von Methoden standhalten, schaut man ins Leere. Alle Strategiemethoden, die an den Universitäten gelehrt werden (von 5-Forces über die Boston-Matrix bis hin zu Porters Normstrategien), sind im Prinzip mit Hilfe äußerst unsicheren Vorgehensweisen entstanden. Wir wissen einfach nicht, ob und wie viel daran wahr ist, weil sie so schwammig definiert sind, dass sie nicht widerlegbar sind – ähnlich einem Horoskop, das auch immer irgendwie stimmt.
Wenn etwas immer stimmt, ist es wertlos.[2] PIMS ist ein Ansatz der prinzipiell widerlegbar wäre und daraus folgend valide Hinweise gibt, in welche Richtung die Strategie einer Geschäftseinheit ausgerichtet werden sollte. Oben genannte Methoden sind eher mit Blindflug vergleichbar. Wenn bei einem langen, vergnüglichen Flug durch den Nebel plötzlich aus dem Nebel ein Felsen sichtbar wird, ist es in der Regel zu spät, das Steuer herumzureißen. Der Kapitän verweist vor dem Aufprall auf seine erfolgreiche Strategie. Nach dem Aufprall wird er externe Faktoren verantwortlich machen (insofern er überlebt) – vermutlich haben geotektonische Aktivitäten plötzlich Felsen wachsen lassen. Es kommt allein darauf an, Methoden zu verwenden, die uns vorhersehen lassen worauf wir hinzusteuern. Das ist das Einzige was zählt. Es kommt nicht darauf an, wie plausibel eine Theorie klingt. Plausible Theorien müssen einfach sein. Im Gegenzug wissen wir jedoch, dass wir für komplexe Systeme komplexe Methoden brauchen, um diese zu managen. Daher scheint mir Vorsicht vor einfachen Theorien und Managementmoden mehr als angebracht.
Ist die strategische Ausrichtung des Business geklärt, muss in Targeting und Segmentierung geschaut werden, welche Zielkunden die eigenen Stärken wirklich wertschätzen werden. Für jedes Zielsegment sollte man sich in bestimmten Bereichen fokussieren. Fokussierung ist die bei weitem effizienteste Methode, um besser zu werden. Warum? Weil mit wenigen, wichtigen Stellhebeln meist der Großteil der erreichbaren Effekte erzielt werden kann. Um die Fokussierung von Aktivitäten, inklusive der Kommunikation mit Kunden, geht es beim Thema Positionierung.
Fallbeispiel: Positionierung eines Finanzdienstleisters
Ein Anbieter von Dachfonds für institutionelle Anleger stand nach einem Merger vor der Aufgabe, sich neu auszurichten und zu positionieren. Die ersten Entwürfe einer Positionierung waren für das Management unbefriedigend. Am liebsten wollte sich das Führungsteam auf allen Punkten positionieren, von denen es glaubte, dass diese den Kunden wichtig sind. Darüber hinaus offenbarte eine Inhouse-Befragung, dass die internen Experten doch eine eher heterogene Meinung über die zentralen Erfolgsfaktoren am Markt hatten.
Wir strukturierten die Suche gemäß der Logik, dass eine Positionierung auf Merkmalen sinnvoll ist, in denen man einen Wettbewerbsvorteil besitzt oder besitzen wird und die zugleich dem Kunden sehr wichtig sind. Daher musste die relative Kundensicht im Wettbewerbsvergleich aufgenommen werden und zugleich die wahre Bedeutung der Merkmale ermittelt werden. Eine umfangreiche Liste an potenziell wichtigen Positionierungsmerkmalen war schnell durch interne Workshops erarbeitet. Die Kundenbeurteilung aller relevanten Anbieter in den Merkmalen wurde durch eine Marktforschung aufgenommen.
Die Kür lag jedoch in der Analyse dieser Daten. Dabei kam wiederum eine spezielle multivariate Analysemethode zum Einsatz. Diese Methode analysierte, welchen Einfluss die Beurteilung verschiedener Merkmale relativ zum besten Wettbewerber auf die Anbieterpräferenz und Kaufentscheidung hat. Die hier wichtigsten Merkmale sind potenzielle Positionierungsfaktoren. Folgende Abbildung zeigt die sogenannte Wettbewerbsvorteilsmatrix, in der die Wichtigkeit auf der Y-Achse mit der relativen Performance im Vergleich zum besten Wettbewerber je Merkmal auf der X-Achse kontrastiert wird.
Es ist ersichtlich, dass ein Wettbewerbsvorsprung im Bereich Reporting-Qualität besteht, die auch zu den TOP-4-Merkmalen gehört. Im Ergebnis wurde eine Positionierung erarbeitet, die sich auf hohe Due-Diligence- und Reporting-Qualität bezog. Weiterhin wurden Verbesserungsprojekte zur Optimierung der Wahrnehmung der Expertise und des Kundenbeziehungsmanagements angestoßen.
Mit Hilfe des multivariaten Modells konnte überdies simuliert werden, welcher Mehrumsatz bei Erfolg zu erwarten war. Die Analyse ermittelte ein Modell dafür, wie Kunden sich entscheiden. In diesem Fall waren sagenhafte 26 Prozent Umsatzsteigerung durch drei Verbesserungsprojekte zu erwarten.
Fallbeispiel: Positionierung einer Kosmetikmarke
Das junge Tochterunternehmen eines führenden Kosmetikkonzerns hatte in den letzten Jahren durch hervorragende Produkteigenschaften ein starkes Wachstum erfahren. Die hoch innovativen Produkte sind nur in Apotheken, bei Dermatologen und in Schönheitskliniken erhältlich. Die aktuelle Positionierung war durch Verpackungsdesign und Marketingmaterialien implizit sehr wissenschaftlich. Jedoch herrschte aufgrund der vielfach vorhandenen Produktvorteile Verwirrung und Uneinigkeit über die richtigen Positionierungsdimensionen.
Wir führten eine Zielgruppenbefragung in Kosmetikapotheken durch, profilierten diverse Wettbewerbsmarken im Hinblick auf 40 mögliche Erfolgsfaktoren und nahmen die Markenpräferenz auf. Wie im vorherigen Beispiel wurde anhand einer speziellen multivariate Analysemethode untersucht, wie sich die Wahrnehmungsdifferenz bei den potenziellen Erfolgsfaktoren auf die Markenpräferenz auswirkt. In der nächsten Abbildung ist das Ergebnis sichtbar. Im Kern empfahlen wir dem Unternehmen:
- Positionieren Sie die Marke durch Fokus auf besonders wirksame Inhaltsstoffe.
- Begründen Sie die Bedeutung der Inhaltsstoffe mit den besonderen Effekten der Produktleistung.
- Achten Sie bei diesen Aspekten darauf, nicht lediglich die absolute, sondern vielmehr die relative Leistung zum Wettbewerb zu erläutern, um so die Einzigartigkeit herauszustellen.
Beide Positionierungsbeispiele haben eines gemeinsam. Sie beziehen sich auf eine eher homogene und sehr spezialisierte Zielgruppe, sodass keine besondere Segmen-tierungsanalyse notwendig erschien.
Unterscheiden sich Zielkunden jedoch grundsätzlich in dem, was sie an Angeboten wertschätzen, ist es sinnvoll, zuvor eine Segmentierung zu erarbeiten. Wie findet man nun diese Segmente? Schlägt man das Lehrbuch auf, findet man eine verwirrende Vielfalt. Häufig in der B2C-Praxis ist beispielsweise eine Segmentierung nach Lebensstilen, Werteclustern oder Einstellungsgruppen. Bekannt sind hier beispielsweise die Sinus-Wertecluster. Diese sind seit Jahrzehnten sehr beliebt, weil sie so schön anschaulich sind. Die Segmentierung ist simpel: Man greift sich passende Gruppen aus diesen Konzepten, argumentiert ein wenig, warum es sinnvoll ist, diese anders zu bedienen, und schon ist die Sache rund. Tatsächlich ist dies jedoch haltloses Storytelling – Management aufs Geratewohl. Warum? Weil die Segmente nicht mit der Maßgabe gebildet wurden, in Wirkbeziehung zum Erfolg zu stehen. In einer Welt in der der Erfolg viele Väter hat, muss man zwangsläufig quantitativ vorgehen, auch wenn man die Nachteile der quantitativen Analyse nicht mag.
In einer guten Segmentierung sind Kunden einander ähnlich, wenn sie im gleichen Segment sind, und sehr unähnlich, wenn sie in unterschiedlichen Segmenten sind. Viel wichtiger für wirksame Segmentierung sind jedoch die Kriterien, mit denen man die Ähnlichkeit ermittelt. Ähnlichkeit aufgrund von beliebigen Kriterien ist unwirksam. Sie ist nur effektiv, wenn die Segmentmitglieder sich in dem ähneln, wie sie ihre Kaufentscheidung treffen – also was ihnen besonders wichtig bei der
Wahlentscheidung ist. Wie findet man also heraus, was dem Zielkunden wichtig ist? Man beobachtet, was er von bestimmten Leistungsbündeln hält. Das funktioniert wieder entweder mit Experimenten (wie Conjoint Measurement oder Produkttestexperimenten) oder unter Anwendung der multivariaten Ursachen-analyse von Beobachtungs- bzw. Befragungsdaten, die in Marktforschungsstudien erhoben werden können.
So kann man etwa den Zielkunden fragen, wie er die fünf wichtigsten Produkte auf dem Markt entlang der zehn wichtigsten Entscheidungskriterien bewertet. Zugleich fragt man ihn vorab, welche der Produkte er bevorzugt oder gar, für welche er sich schon einmal entschieden hat. Jetzt schlägt die Stunde der Ursachenanalyse, denn wenn zehn Entscheidungsmerkmale zeitgleich Einfluss auf die Produktwahl haben, benötigen wir Methoden, die die Effekte der einzelnen Ursachen separieren können. Das geht nur mit multivariaten Analyseverfahren, die uns sagen, welche Veränderung der Ursachen im Durchschnitt welche Wirkung auslöst. Für Targeting und Segmentierung brauchen wir aber keine Durchschnittsangaben. Wir möchten wissen, welche Kundengruppen sich in den Anforderungen in welcher Weise unterscheiden. Lassen Sie mich die Vorgehensweise an einem praktischen Fall erläutern.
Fallbeispiel: Segmentierung bei einem Industriegüterhersteller
Ein internationaler Hersteller von Industrieverpackungen hatte vor einigen Jahren eine Kundensegmentierung eingeführt. Ein Berater hatte vorgeschlagen, die Kunden in die Preiskäufer, die Service Seeker, die TCO-Käufer und die Qualitätsorientierten zu unterteilen. Leider stellte sich die Segmentierung als nicht zu Ende gedacht heraus. Zum einen klappt es kaum, Kunden richtig zu kategorisieren. Eine Checkliste von 20 Kriterien über Produkt und Servicefeatures, die der Kunde heute bezieht, stellte sich als wenig valide heraus. War ein Kunde einmal kategorisiert, gab es keinen genau definierten Prozess, wie die Kunden unterschiedlich behandelt werden sollten.
Daher war das Unternehmen auf der Suche nach einer neuen wirksamen und umsetzbaren Segmentierung. Dazu wurde eine Kundenbefragung durchgeführt, in der wir mit speziellen multivariaten Analysemethoden vier zentrale Treiber für die Kundenbindung identifizierten: Preis (Competitive prices), Informelle Meetings (Meetings extension), Bestellprozesse (Order processing) und Grad der Unternehmensverzahnung (Inhouse integration).
Mit der verwendeten Analysemethode war es möglich, die Wichtigkeit der Treiber für jeden Befragten separat anzugeben.[3] Dies ermöglichte uns, eine Clusteranalyse auf Basis der Treiberbedeutung durchzuführen. Damit können die Befragten gefunden werden, die sich einander ähneln, wobei der Gruppenmittelpunkt sich idealerweise stark von den anderen Gruppen unterscheidet. Im Ergebnis erhielten wir einige Segmente, die inhaltlich mit Begriffen wie Anspruchsvolle, Total Cost of Ownership, Altmodisch-Preisbewusste oder Operativ-Fokussierte beschrieben wurden. Das Problem bei solchen Analysen ist die Praktikabilität. Woher weiß ich, ob ein Kunde, der vor mir sitzt, ein Anspruchsvoller oder ein Operativ-Fokussierter ist? Ich müsste streng genommen wieder die gleiche Befragung beim Kundenbesuch durchführen. Weiterhin ist ein Clustering immer willkürlich, da es kein absolutes Kriterium dafür gibt, was ein Cluster ausmacht und wie viele Cluster in einem Datensatz vorliegen.
Daher haben wir die Befragten auf Basis von inhaltlichen Vorüberlegungen gruppiert. Dieses Vorgehen nennt man Apriori Segmentierung. Und hier wurden wir bei einer Gruppierungsvariante fündig. Die Segmente „Committed Customers“ und „A-Kunden“ unterschieden sich komplementär in dem, was diese wertschätzten. A-Kunden sind typische Kunden mit großer Nachfrage, die aus strategischen Gründen mit einer Mehr-Lieferanten-Strategie einkaufen. Diese Kunden haben zentrale Einkaufsabteilungen, in denen der Entscheider der Einkäufer ist. Diesem ist der Preis und eine gute Betreuung wichtig. Hingegen ist beides dem Committed Customer weniger wichtig. Ihm ist wichtig, dass die Zusammenarbeit auf operativer Ebene perfekt läuft und die Unternehmen operativ verzahnt sind, um Produktionsprobleme zeitnah zu lösen.
Es ist zwecklos, einem A-Kunden eine Innovation verkaufen zu wollen, da er immer einen Zweitlieferanten braucht. Hingegen ist es wenig profitabel, den Commited Customer mit Preiszugeständnissen zu ködern, während man sich sonst nicht besonders um ihn kümmert. Diese einfache, äußerst nützliche und inhaltlich sinnvolle Segmentierung war das Ergebnis einer komplexen Analysemethodik.
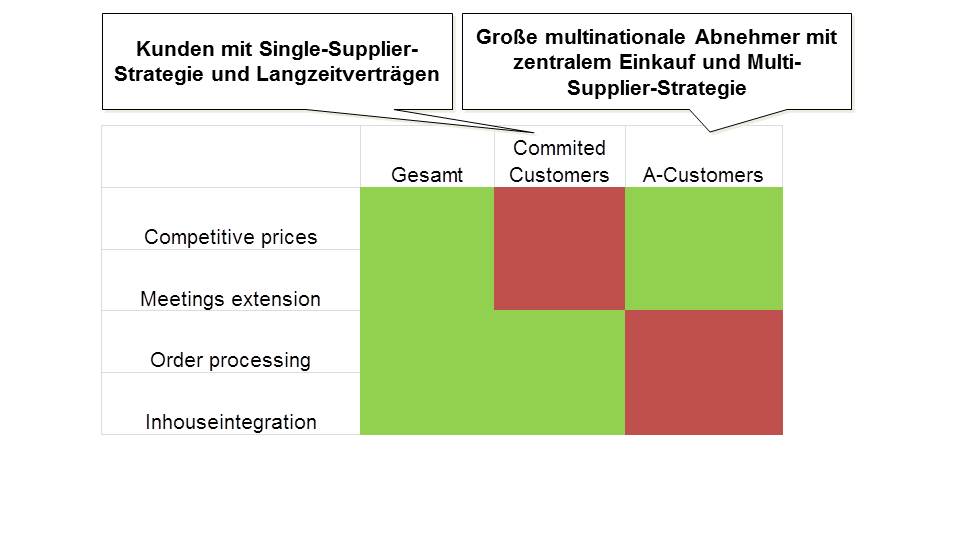
Natürlich könnte man fragen: Ist Segmentierung nicht ein reines Marketingthema? Die Ausrichtung der Segmentierung beginnt mit den Kunden, denn diese definieren immer den Unternehmenszweck – niemals die Shareholder, Mitarbeiter oder Lieferanten. Die Umsetzung geht durch das gesamte Unternehmen. Bei der Einführung einer Segmentierung sieht man sich Widerständen ausgesetzt. Der Bereichsleiter der Produktion fragt sich natürlich, warum er seine glatt laufenden Produktionsprozesse individualisieren und so Kapazitätsauslastung reduzieren soll. Der Vertriebsleiter fragt sich, warum er nicht weiterhin jeden Kunden individuell behandeln soll – ohne zu merken, dass er in Wirklichkeit jeden Kunden gleich behandelt, jedem Kunden das Gleiche erzählt und jedem das Gleiche anbietet. Der Einkauf fragt sich, warum er unterschiedliche Materialqualitäten beschaffen und so Einkaufsmacht verlieren soll. Ohne zu sehr ins Thema Segmentierung einzutauchen, soll dies nur illustrieren, dass Kundenindividualisierung Kosten verursacht. Zum einen tatsächliche Kosten und zum zweiten organisatorische Kosten. Individualisierung ist nun mal teurer als Schema F. Das hat schon Henry Ford gewusst, der mit dem Satz „Sie können ihr Auto in jeder Farbe haben, solange es schwarz ist“, eine komplette Industrie erst ermöglicht hat. Daher ist es ökonomisch sinnvoll, ein Optimum zu finden. Das Optimum ist eine angemessene Segmentierung in wenige differenzierte Leistungsbündel, die auf sehr unterschiedliche Kundengruppen zugeschnitten sind. Und das ist in der Tat ein Thema der Unternehmensstrategie.
Anwendungsbereiche zusammengefasst
Lassen Sie uns zusammenfassen, in welchen Bereichen multivariate Ursachenanalysen sinnvoll eingesetzt werden sollten.
Jedes Unternehmen verkauft Produkte und/oder Dienstleistungen an Kunden (Verkauf). Um diese Leistung erbringen zu können, bezieht es Güter und/oder Dienstleistungen von Lieferanten (Einkauf) und wandelt diese in einem wie auch immer gearteten Prozess in ein verkaufbares Ergebnis um (Produktion). Darüber hinaus wird implizit oder explizit eine Strategie erstellt und verfolgt. Die Mitarbeiter (und damit die Organisation) werden durch die Führungskräfte gemanagt. Weiterhin können diverse administrative Funktionen wie IT oder Finanzen dazukommen, wenn diese Funktionen nicht von Dienstleistern zugekauft werden.
Das skizzierte vereinfachte Schema habe ich unten dargestellt. Rot sind solche Bereiche gefärbt, die in besonderer Weise soziale Systeme managen müssen. Ihre Aufgabe ist daher besonders komplex, da Zielgrößen viele Ursachen haben. Aus diesem Grund ist die Anwendung multivariater Methoden in diesen Bereich besonders nützlich.
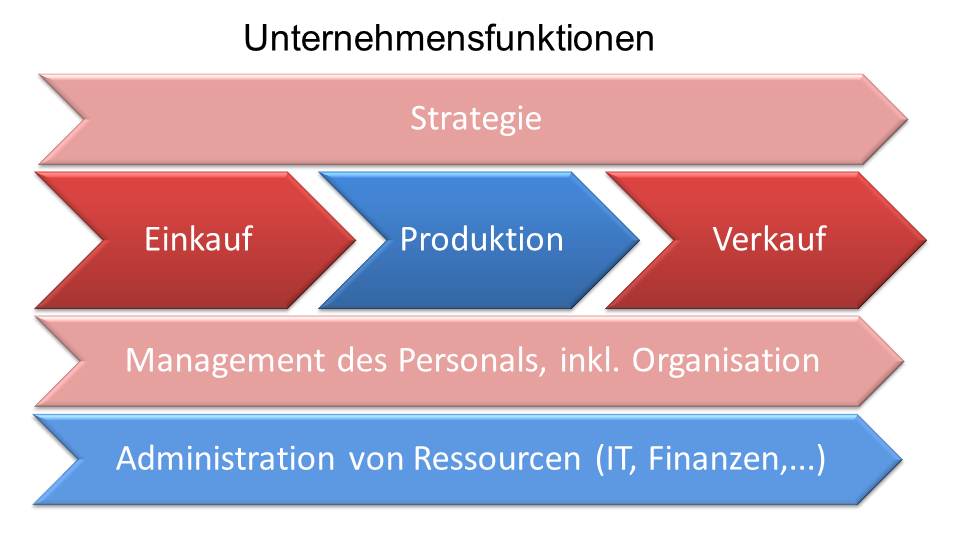
Wir haben gesehen, wie die Strategie durch Segmentierungs- und Positionierungs-analysen optimal ausgerichtet und mit Hilfe der PIMS-Datenbank optimiert werden kann. Weiterhin wurde intensiv am Bereich Verkauf gezeigt, in welchen Bereichen das Vorgehen effektiver und effizienter gestaltet werden kann. Analog finden sich ähnliche Anwendungsfelder im Bereich Einkauf und Management des Personals.
So wurde deutlich, wie nützlich multivariate Analysemethoden sein können. Doch wie setzen wir diese Erkenntnis um? Kaufen wir einfach eine Analysesoftware und legen los? Das folgende Kapitel demonstriert, worauf bei Auswahl einer geeigneten Analysemethode geachtet werden sollte. Denn wie überall steckt der Teufel im Detail.
[1]Mehr zur „Ich“-Illusion finden Sie in Susan Blackmore inspirierendem Buch „Meme Machine“
[2]Karl Popper 1926
[3]Das verwendete Feature ist als Hierachical Bayes Methode bekannt
KAPITEL 5
Was macht einen guten digitalen Spürhund aus: Die Wahl der richtigen Methode
Was müssen die Methoden können, die uns beim Aufbau von Wissen unter Rückgriff auf Daten helfen sollen? Um gute Methoden auswählen zu können, muss man zunächst verstehen, welche Anforderungen die Praxis an diese Methoden stellt.
Das klingt trivial. Jedoch scheinen dies die meisten Methodenexperten heute zu übersehen. Warum? Weil die Anforderungen der Praxis im Grunde nur die Praxis kennt. Wissenschaftler haben einen anderen Fokus und haben daher oft wenig mit den Anforderungen der Praxis zu tun. Wirtschaftswissenschaftler suchen nach allgemeinen Theorien, die bei der Führung aller Unternehmen helfen – ein hehres, aber vermutlich zu hohes Ziel, wie viele meinen. Statistiker suchen nach Methoden, die bestimmte statistische Eigenschaften verbessern. Nur: Welche Eigenschaften sind die für die Praxis wichtigen? Unternehmensberater suchen Lösungen, die dem Kunden einleuchten und sich verkaufen. Keiner, außer die Unternehmen selbst, hat ein ureigenes Interesse, die Anforderungen der Praxis aufzudecken und ihnen gerecht zu werden.
Die erste Anforderung an nützliche Methoden der Ursachenanalyse haben wir bereits kennengelernt. Diese Methoden müssen viele Treibervariablen gleichzeitig im Verbund analysieren können. Dies tun sogenannte multivariate Methoden. Genügt das schon? Was sollte eine brauchbare Methode außerdem noch können?
Wie Kolumbus sein: Entdecken können
In einem Projekt zur Erarbeitung einer Segmentierungsstrategie suchte ein Industrieunternehmen die wesentlichen Entscheidungsfaktoren seiner Kunden. Wir befragten gestandene Industrieexperten mit kumuliert hunderten Jahren Vertriebserfahrung. Die in der folgenden Grafik links grün unterlegten Faktoren waren die nach Expertenmeinung wichtigsten Kriterien, wobei die Faktoren im weißen Feld ebenfalls einen Einfluss hatten.
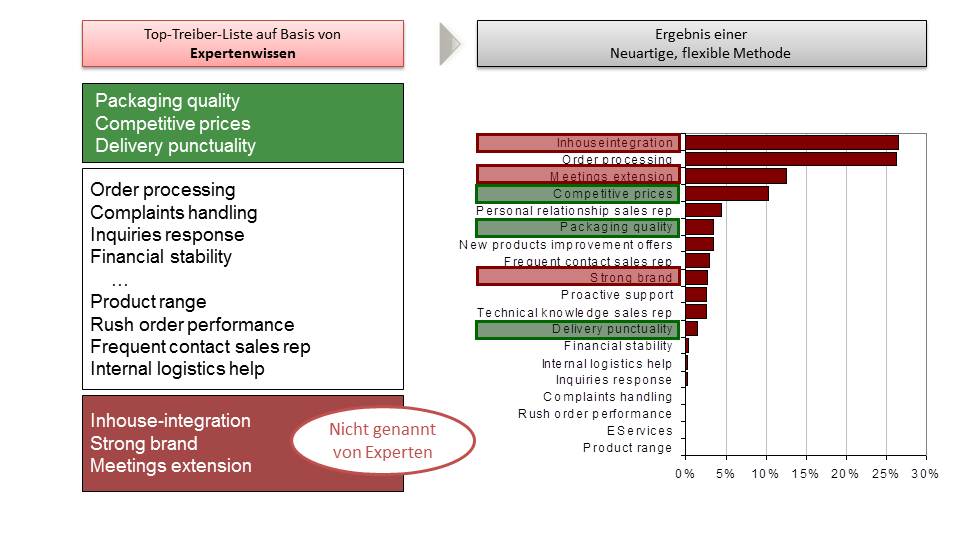
Die Kriterien im roten Feld fügten wir aufgrund theoretischer Überlegungen von Branchenoutsidern hinzu. Jetzt schauen Sie einmal, was unsere multivariate Ursachenanalyse im rechten Teil der Abbildung ergeben hat! Zwei der drei ungenannten Kriterien sind unter den Top 3. Nur eines der nach Expertenmeinung wichtigen Kriterien schafft es in die Top 5.
Expertenwissen oder andere „anerkannten“ Theorien sind weit schlechter als wir glauben wollen. Das ist ein großes Problem. Wäre es daher nicht enorm nützlich, Methoden zur Verfügung zu haben, die gänzlich neues Wissen aus Daten ableiten können?
Im genannten Beispiel wurden unbekannte Erfolgsfaktoren als zentral identifiziert. Das nenne ich Wissenszugewinn. Oder wie es ein Pionier der Kausalanalyse, Professor Bookstein, bei einer Konferenz 2009 in Peking zu mir gesagt hat: „Analysemethoden sind nur dann nützlich, wenn sie prinzipiell eines können: Dich so zu überraschen wie eine Harke Dir zwischen die Augen knallt, wenn Du aus Versehen auf die Zacken trittst.“
Okay, das ergibt Sinn. Aber können das nicht alle multivariaten Methoden? Leider nein. Tatsächlich haben noch immer bestätigende Methoden die Überhand in Wissenschaft und Praxis. Dazu ein Beispiel.
Der bereits erwähnte deutsche Mobilfunk-Dienstleister wollte herausfinden, worauf man beim Launch eines neuen Mobile-Wallet-Service (eine virtuelle Brieftasche für Smartphones) zu achten habe. Die Studie wurde im Rahmen einer MBA-Theses wissenschaftlich, also sehr sorgsam und mit modernsten Methoden begleitet. Gearbeitet wurde mit einer herkömmlichen Analysesoftware, die auch ein Ergebnis auswarf. In einem solchen Fall werden die Resultate dann als richtig angesehen, wenn alle Annahmen korrekt sind. Alle Pfade und Nichtpfade, die linearen Veränderungen, die Verteilung der Daten und vieles mehr müssen passen, damit die Analyseergebnisse stimmen. Man nennt diese Methoden konfirmatorisch, da sie einen Anfangshypothese annehmen oder ablehnen und ein paar Pfadstärkeparameter ausspucken – mehr nicht. Sie setzen also eine Tatsache voraus und messen nur noch, zu wie viel Prozent diese zutrifft oder nicht.
Die Ergebnisse sind in der folgenden Abbildung links zu sehen.
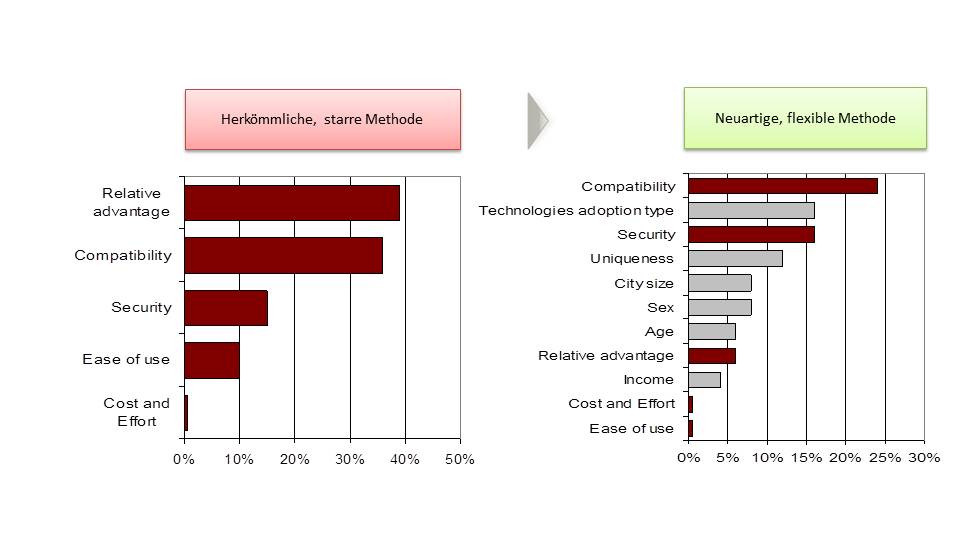
„Relative Advantage“ ist das wichtigste Kriterium. Daraus folgerte man, dass der Produktnutzen hervorgehoben werden musste. Rechts hingegen sehen Sie die Ergebnisse der anderen Analysemethode, die der clevere MBA-Absolvent hinzugezogen hatte. Mit dieser ist es möglich, auch andere Ursachen mit einzubeziehen, die aus Sicht des gesunden Menschenverstands ebenfalls Einfluss haben können. Die herkömmliche Methode kann diese Größen aus zwei Gründen nicht aufnehmen: Zum einen sind einige nicht metrisch verteilt und verstoßen damit gegen die Modellannahmen (so wie das Geschlecht, das binär verteilt ist). Zum anderen dürfen nur vorher bestätigte Zusammenhänge aufgenommen werden – jedoch keine vagen Vermutungen.
Das Resultat sind sehr verschiedene Ergebnisse. Die alternative Methode zeigt, dass andere Größen (wie der Technologietypus des Zielkunden oder die wahrgenommene Einzigartigkeit des Angebots) nachweislich und hochsignifikant ebenfalls einen Einfluss haben. Interessanterweise stellte sich heraus, dass Uniqueness die Einschätzung von „Relative Advantage“ maßgeblich beeinflusst. Zielkunden, die das Produkt einzigartig finden, attestieren meistens auch einen gewissen Produktvorteil – nicht aber umgekehrt. Das steht natürlich auch im Einklang mit den neuen Erkenntnissen der Neuroforschung.
Wichtiger aber ist eine komplett andere Empfehlung, die man ableiten konnte. Nicht eine rationale Kommunikation aller Vorteile steht im Zentrum, sondern die Vermittlung der Einzigartigkeit. Deshalb wurde eine eher emotionale Kampagne empfohlen.
Wir brauchen demnach Methoden, die uns helfen, Wissen und Erkenntnisse zu entdecken. Wir benötigen Vorgehensweisen, die uns helfen, zu lernen. Wir sind auch deswegen so sehr darauf angewiesen, weil wir chronisch dazu neigen, unser Expertenwissen zu überschätzen.
Ich habe mich selbst lange Zeit dabei beobachtet, wie sich meine Meinung bei Experteninterviews über den zu findenden Zusammenhang entwickelt hat. Und ich musste immer wieder feststellen, dass ich mir nach drei oder vier Interviews ziemlich sicher war, wo der Hase langläuft. Experten konnten mir danach erzählen, was sie wollten, ich neigte dazu, weniger hinzuhören und Fragen zu stellen, die meine Meinung bestätigten. Hat man sich einmal eine Meinung gebildet, steht die fest. Meist ein Leben lang. Fragt man Statistiker, wie valide eine Stichprobe von drei oder vier ist, erntet man nur mildes Lächeln.
Noch immer haben gerade im Bereich des Marketings und der Marktforschung konfirmatorische Analysen die Oberhand. Wozu mache ich denn eine Analyse in der Praxis? Doch nicht um eine Hypothese zu bestätigen. Allein das rechtfertigt oft nicht den Aufwand. Zudem fehlt einfach die Gewissheit für das Aufstellen eines Hypothesenmodells. Nein, es geht in der Praxis grundsätzlich darum, neues Wissen zu erlangen, um daraus wirklich etwas zu lernen.
Wo kommt das Wissen her, mit dem die konfirmatorischen Modelle gebildet werden? Welche wissenschaftliche Methode ist die Quelle dieser Hypothesen? Streng genommen müssten das immer Experimente sein. Diese sind es aber im seltensten Fall. Fast immer lügen sich die Anwender herkömmlicher Methoden bei der Einschätzung der Validität ihrer Annahmen selbst in die Tasche. Das ist ein offenes Geheimnis. Das werden Ihnen selbst Befürworter des konfirmatorischen Ansatzes bestätigen.
Glücklicherweise ist es durchaus möglich, aus Erfahrungswerten zu lernen. Das wusste schon Immanuel Kant, der es auf den Punkt brachte: „Die Erfahrung ist die einzige Quelle der Erkenntnis.“ Später hat Professor Granger ein neues Verständnis darüber formuliert, ab wann man aus Erfahrungsdaten Kausalität ableiten kann. Dafür hat er vor ein paar Jahren auch den Nobelpreis erhalten. Seine Theorie steht in genauem Widerspruch zu dem in den Wirtschaftswissenschaften verbreiteten Konfirmationsglauben. Eine Größe A ist immer dann Ursache der Größe B, wenn alle möglichen Ursachen bekannt und quantifiziert vorliegen und A unter allen am besten geeignet ist, einen Teil einer zeitlich nachgelagerten Änderung von B zu erklären.
Der Nachweis der zeitlichen Nachgelagertheit ist in vielen Fällen praktisch nicht möglich. Bislang musste man sich hier damit aushelfen, die Kausalrichtung durch Vorwissen festlegen zu müssen. Doch auch in diesem Feld gibt es neue wissenschaftliche Erkenntnisse. Man kann heute anhand von Querschnittsdaten feststellen, in welche Richtung die Kausalität verläuft. Die Bedeutung ist immens. Denn in vielen Fällen ist dies dem Experten schlichtweg nicht bekannt. Führt die Servicezufriedenheit zu mehr Kundenbindung oder führt eine höhere Kundenbindung zu einer besseren Einschätzung der Servicezufriedenheit? Die Beantwortung solcher Fragen legt fest, welchen Einfluss welche Erfolgstreiber besitzen.
Vorsicht vor Expertenwissen. Vorsicht vor „wissenschaftlich fundierten“ Modellen. Und Vorsicht vor den herkömmlichen, starren Analysemethoden. In der Praxis nützliche Methoden müssen in der Lage sein, NEUE Erkenntnisse zu erzeugen. Nützliche Methoden sind entdeckende Methoden.
Welche multivariaten Methoden arbeiten entdeckend? Die im Einsatz befindlichen herkömmlichen Methoden[1] sind es in jedem Fall nicht. Entdeckende Methoden[2] sind erst in den letzten Jahrzehnten entwickelt worden. Um sich für eine davon zu entscheiden, müssen wir jedoch auf weitere Anforderungen eingehen.
Erkennen, was da ist: Komplexität entdecken können
Eine weitere Annahme, die herkömmliche Methoden voraussetzen, ist die Linearität der Zusammenhänge. Linear ist ein „je mehr, desto besser“-Zusammenhang. In einem solchen Zusammenhang bewirkt eine zusätzliche Steigerung der Ursache immer die gleiche Erhöhung des Effekts.
Schauen wir uns einfach einmal zwei Beispiele an. Ein Beispiel haben wir schon gesehen. An dieser Stelle wird es noch einmal interessant.
Für ein Pharmaunternehmen haben wir die Verkaufsförderungsmaßnahmen zu einem bestimmten Produkt analysiert und festgestellt, dass die Ausgabe kostenloser Proben durch den Außendienst zunächst einen positiven Effekt auf den Abverkauf hat. Ab einer bestimmten Menge jedoch wirkt diese Freigiebigkeit verkaufshemmend. Vermutlich geben die Ärzte schließlich so viele Proben aus, dass die Patienten weniger oder keine Medikamente mehr selbst kaufen müssen. Simpel und logisch. Die Realität ist voller Nichtlinearitäten. Mehr ist eben nicht immer besser.
Ein anderes Beispiel: Regelmäßig führe ich Analysen von Befragungen zur Kundenzufriedenheit durch. Unter anderem wird der Einfluss der Kundenzufriedenheit auf das übergeordnete Ziel der Kundenbindung untersucht. Herkömmlichen Methoden weisen hier einen klaren Zusammenhang nach: je höher die Zufriedenheit, desto enger die Bindung. Bei vielen Unternehmen jedoch kann ich feststellen, dass die Wirkung der Kundenzufriedenheit in Wirklichkeit abflacht. Die nächste Abbildung zeigt das:
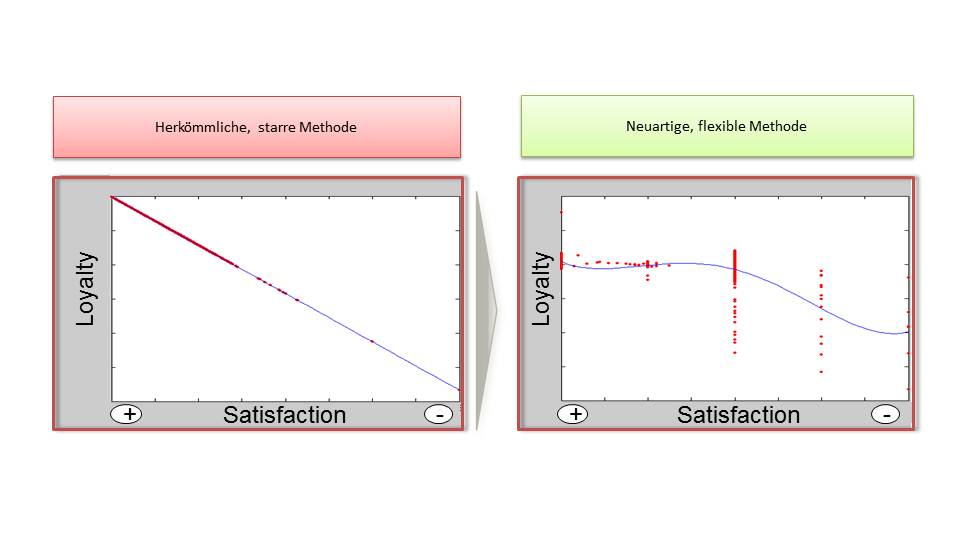
Sobald die Zufriedenheit unter den mittleren Status sinkt (das entspricht dem Skalenpunkt „weder noch“), so sinkt die Kundenbindung drastisch. Zufriedenheit ist daher kein wesentlicher Faktor, der Kunden bindet, während Unzufriedenheit tatsächlich Wechselabsichten auslöst. Zufriedenheit ist offensichtlich nur eine Art Grundbedingung dafür, dass ein Kunde die Geschäftsbeziehung aufrechterhält.
Ist das logisch? Scheinbar gibt es noch andere Gründe, um sich an das Unternehmen gebunden zu fühlen. Für manche Unternehmen etwa entscheiden sich die Kunden deshalb, weil deren Produkte und Services einfach die einzigen oder besten für ihre Zwecke sind. Solche Kunden äußern bei Befragungen häufig: „Das Produkt ist nicht perfekt, aber es ist das Beste am Markt.“
Woher allerdings wissen wir, dass die herkömmlichen Methoden falsch liegen? Die Antwort ist einfach: Man prüft, wie gut ein Modell in der Lage ist, Daten, die das Modell nicht kennt, zu prognostizieren. Wenn diese prognostische Validität höher ist, ist das ein starkes Zeichen dafür, dass das Modell in höherem Maße der Realität entspricht.
Weiterhin muss der identifizierte Zusammenhang plausibel sein (Face Validity). Drittens sollte das Modell vollständig sein. Da in meinem Modellen methodisch weitaus mehr Treibervariablen berücksichtigt werden, sind meine Modelle meist deutlich vollständiger als herkömmliche.
Unsere Welt ist inhärent nichtlinear – all das kann man im Detail beim Pionier der systemischen Forschung Frederik Vester nachlesen. Wenn Ihr Unternehmen mehr Kapital hat, kann es dann mehr damit erreichen? Die Antwort lautet: ja natürlich. Jedoch ist höchstwahrscheinlich der erste Euro der effektivste. Natürlich hat das kluge Argument Recht, dass es Mindestkapitalbedarfe gibt, weil es keine Maschine für einen Euro gibt. Aber auch das ist ein Beispiel für Nichtlinearität. In diesem Fall ist der erste Euro nichts wert, weil man einen viel höheren Betrag für eine erste Maschine ausgeben muss. Es gibt Tausende von Beispielen. Statistiken zeigen, dass die Wertschöpfung von Mitarbeitern sinkt, je mehr im Unternehmen arbeiten. Klar. Der erste Mitarbeiter ist am wertvollsten, da ohne ihn gar nichts läuft. Der Grenznutzen sinkt natürlich.
Die Wirklichkeit ist voller nichtlinearer Zusammenhänge. Mehr ist nicht immer besser. Es hat eine große Auswirkung auf meine Entscheidung, wenn ich weiß, was der tatsächliche Effekt einer zusätzlichen Änderung Ursache ist.
Aber es geht noch komplizierter. Eine weitere Annahme herkömmlicher Methoden ist, dass die Ursachen unabhängig voneinander wirken. In der folgenden Metapher, die in der nächsten Abbildung dargestellt ist, geht es um Jim, den Tomatenbauer. Jim will die Erfolgsfaktoren des Wachstums seiner Tomatenpflanzen herausfinden, um höhere Erträge zu erzielen. Er identifiziert zwei Erfolgstreiber: Sonne und Wasser.
Um Wasserkosten zu sparen, lässt er Wasser weg und verdoppelt die Lichtmenge. Das Ergebnis ist fatal. Dann probiert er das Gegenteil – wenig Sonne, viel Wasser. Hier ertrinken die Pflanzen und verfaulen. Anschließend probiert er viel Sonne und viel Wasser. Auch das endet im Desaster. Nach jahrelangem Feintuning hat er genügend Erfahrungswerte: Man braucht beides, Wasser und Sonne, um eine Pflanze gut wachsen zu lassen. Zudem darf beides nicht überhand nehmen.
Beide Erfolgsfaktoren bedingen sich gegenseitig. Sie sind nicht unabhängig, da ein Faktor das Fehlen des anderen nicht kompensieren kann.

Ein amüsantes Comic-Video dazu finden Sie in meinem Youtube-Channel:
http://www.youtube.com/user/DrFrankBuckler mit dem Titel „Find Success Levers with NEUSREL“
Im Rahmen einer Geschmacksprobe habe ich den Einfluss verschiedener Geschmackskomponenten von Biermixgetränken auf auf die Präferenz untersucht. In der herkömmlichen Vorstellung summieren sich die verschiedenen Eigenschaften eines Getränks auf zu einem Gesamtwert, der widerspiegelt, wie stark ein Mensch ein Getränk mag.
In meiner Analyse jedoch stellte sich eine sehr starke Interaktion der Komponenten „Full taste“ und „Metallic taste“ heraus. Ein Getränk wird nur dann bevorzugt, wenn es einen vollen Geschmack UND gleichzeitig keinen metallischen Geschmack hat. Beides muss gegeben sein. Ein Abwägen findet nicht statt.
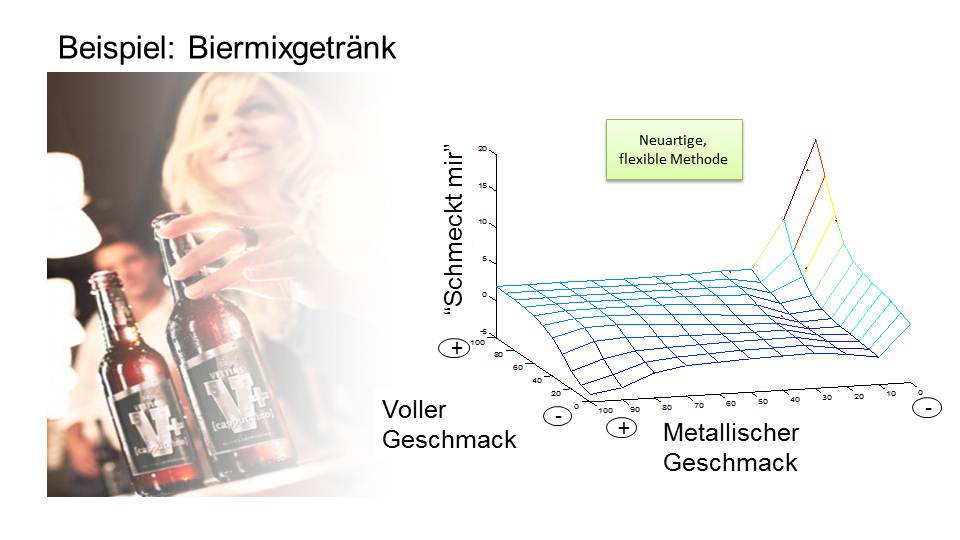
Das Gegenteil von Unabhängigkeit sind Interaktionen. Diese sind Moderations-effekte, also Wechselwirkungen, zwischen Ursachen. Die Tomaten-Metapher zeigt sehr gut, was eine Interaktion ist. Existieren solche Interaktionen auch in Unternehmen? Wir können sicher sein und beweisen: Es gibt eine riesige Menge.
In einem weiteren Beispiel geht es um eine Studie einer Einzelhandelskette, die herausfinden wollte, wie die Kundenbeziehung verbessert werden kann, weil diese als starker Gewinntreiber identifiziert wurde. Herkömmliche Methoden legen nahe, dass sogenannte Tangible Rewards (Rabatte, Give-Aways, Beigaben, etc.) und die Qualität der zwischenmenschlichen Kommunikation wichtige Treiber sind. Im Sinne der Linearität, die ein „je mehr, je besser“ behauptet, würde man jetzt in die Verbesserung beider Komponenten investieren.
Mit einer geeigneten Methode habe ich eine hochinteressante Interaktion identifizieren können. Beide Treiber haben einen nachweisbaren Effekt, wenn – und nur wenn – der andere Treiber gering ausgeprägt ist. Beide Treiber wirken komplementär. Wenn die zwischenmenschliche Kommunikation perfekt ist, haben all die kleinen Geschenke und Zuwendungen keinerlei Effekt und bedeuten eine Geldverschwendung.
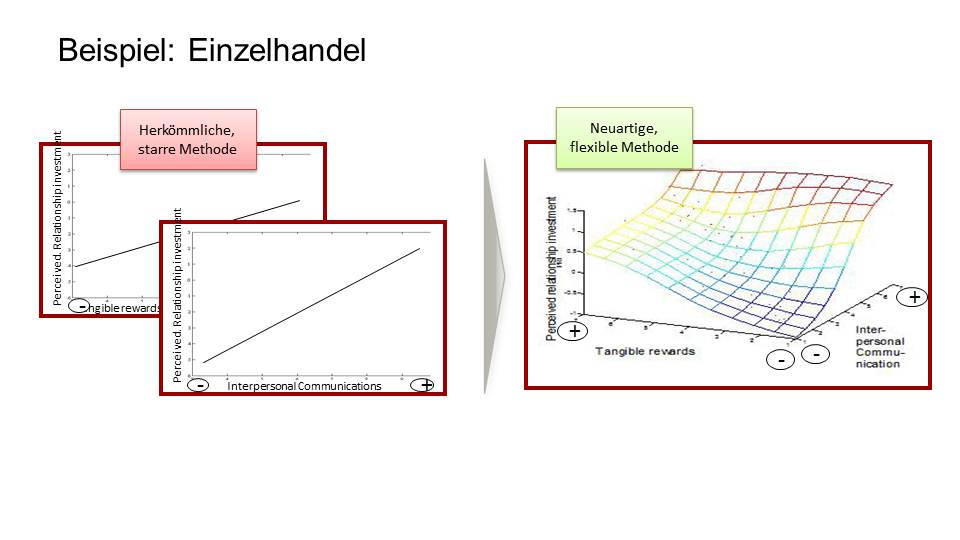
Wenn wir bei Kunden, die wir regelmäßig mit Zugaben verwöhnen, die zwischenmenschliche Kommunikation perfektionieren, erreichen wir nur geringe Zusatzeffekte. Entweder das Eine ODER das Andere. Intrinsische und extrinsische Kaufmotivation der Kunden scheinen sich zu behindern und nicht zu addieren. Die resultierende Empfehlung an das Unternehmen durch eine geeignete Methode ist wieder grundlegend anders als die von herkömmlichen Methoden. Entscheiden Sie sich für einen der beiden Treiber – je nach Kosten-Nutzen-Verhältnis.
Die Wirklichkeit ist voller Interaktionen. Manche Erfolgstreiber bedingen sich. Andere hemmen sich. Daher müssen nützliche Methoden der Interaktivität von Ursachen Rechnung tragen.
Zu guter Letzt gibt es noch eine dritte, etwas verdeckte Eigenschaft von Analysemethoden, die heute kaum in der Praxis zur Sprache kommt. Es geht um indirekte Effekte. Das folgende Fallbeispiel macht es deutlich.
Ein multinationales Unternehmen wollte verstehen, was über alle europäischen Märkte hinweg die Hebel zur Steigerung des Marktanteils sind. Dazu wurden alle Ländergesellschaften sowie alle Wettbewerber anhand kritischer Faktoren beschrieben: die Werbeausgaben, der Loyalitätsindex, der relative Preis, das Preisimage u.v.m. Diese Daten wurden über die vergangenen fünf Jahre gesammelt, sodass ca. 150 Fallwerte vorlagen. Um anhand dessen die Änderung des Marktanteils zu erklären, wendet man typischerweise eine wie auch immer geartete multivariate Regressionsanalyse an.
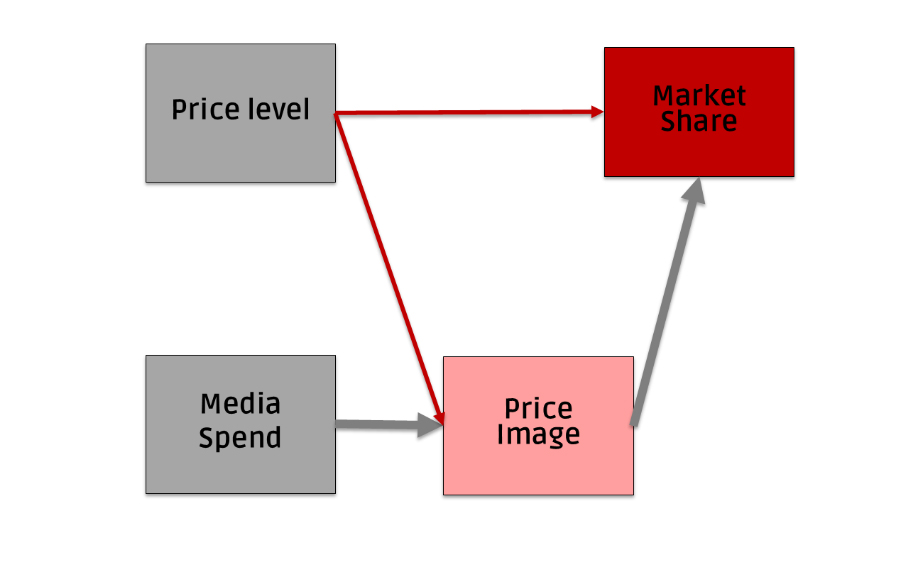
Was meiner Beobachtung nach selbst den meisten „Analyseexperten“ in Marktforschungsagenturen bislang nicht aufgefallen ist, ist die Tatsache, dass solche Methoden nur die direkten Effekte der Treiber auf die Zielgröße messen. In unserem Beispiel finden solche Methoden fälschlicherweise heraus, dass Preis und Preisimage allein die Haupttreiber sind. Mediaausgaben hingegen haben keinen (direkten) Effekt. Wer nicht verstanden hat, dass klassische Methoden nur direkte Effekte ausspucken, wird empfehlen, die Mediaspendings einzustellen. Doch das ist großer Nonsens und kann sehr teuer werden.
Mediaspendings sind zentral für das Adustieren eines positiven Preisimages in diesem Markt. Der totale Effekt von Mediaausgaben ist in Wirklichkeit groß. Der analytische Ansatz, der indirekte Effekte einbezieht, ist die Pfadanalyse. In ihr berücksichtigt man ganz einfach alle Effekte aller Variablen untereinander und zählt am Ende die Totaleffekte zusammen.
Ohne Berücksichtigung indirekter Effekte ist keine sinnvolle Aussage über die Relevanz von Erfolgshebeln möglich. Daher müssen nützliche Methoden pfadanalystische Ansätze beinhalten.
Wir benötigen also Methoden, die nichtlineare und interaktive Zusammenhänge entdecken können und die dies im gesamten Kausalnetzwerk tun. Dabei liegt eine deutliche Betonung auch auf dem Faktor des Entdeckens. Rein theoretisch könnten man Nichtlinearitäten auch konfirmatorisch modellieren. Das nützt jedoch nichts, wenn man im Vorfeld nicht weiß, welche Form die Nichtlinearität hat. Bei Interaktionen ist die Situation noch erheblich undurchsichtiger, weil man bei vielen Treibern niemals wissen kann, wer mit welchem interagiert. Die Vielfalt der Möglichkeiten wird schnell exponentiell komplex. Konfirmatorische Modelle setzen ja immer schon eine halbwegs plausible Annahme voraus, die zu prüfen ist. Bei vielen Treibern ist eine solche Annahme vollkommen unmöglich.
Welche multivariaten Methoden können nichtlineare und interaktive Zusammenhänge entdecken und visualisieren? Neue entdeckende Methoden des Fachgebiets Maschinelles Lernen können mehr oder weniger gut nichtlineare und moderierende Zusammenhänge modellieren – jedoch nicht visualisieren. Sie leiden unter dem Black-Box-Syndrom. Der mehrdimensionale Gesamtzusammenhang ist in seiner mathematischen Form nicht verständlich. Dafür muss eine geeignete Nachanalysemethode gefunden werden. Am Ende des Kapitels nehmen wir eine solche Methode in unseren ganzheitlich leistungsfähigen Methodenverbund mit auf.
Mit dem auskommen, was man hat: Mit kleinen Stichproben umgehen können
Die dritte zentrale Anforderung an nützliche Methoden ist von anderer Natur. Hier geht es nicht darum, was die Methode alles herausfinden können muss. Es geht darum, zu beachten, was eine valide Erkenntnis beschränkt. Die wichtigste und praktisch bedeutsamste Einschränkung ist die Anzahl der Erfahrungswerte – also die Stichprobengröße.
Theoretisch kann man alles aus Daten lernen, insofern alle wichtigen Größen quantifiziert bekannt sind und unendlich viele Erfahrungswerte vorliegen. Leider ist diese Voraussetzung nie gegeben, da mit der Datenbeschaffung Kosten verbunden sind. Irgendwo existiert immer der Punkt, an dem die Datenerhebung mehr Geld verschlingt, als sie Nutzen erwirtschaftet. Zudem sind manche Erfahrungswerte ganz einfach zu selten, um auf eine riesige Anzahl zu kommen. Aufgrund dieser Tatschen ist es eine zentrale Anforderung an eine Methode, besonders effizient mit den Daten, und das auch bei begrenzten Stichproben, umzugehen. Es ist wichtig, das Maximale aus wenigen Daten herauszuholen. Welche Methoden leisten das?
Die Wahl zwischen Scylla und Charybdis: Abwägen zwischen Modellkomplexität und Modellanpassung der Daten
Waren Sie damals auch so ein Schüler, der den Stoff immer nur auswendig lernte aber die Bedeutung nicht zuordnen konnte? Sicher nicht, aber sie kennen mindestens einen Mitschüler, der so tickte. Unsere Ursachenanalyse soll auch lernen. Anhand von wenigen Datensätzen, die die Erfahrungswerte für diese Analyse darstellen, soll Wissen abgeleitet werden, dass auch für künftige Erfahrungswerte richtig ist. Nun gibt es auch in der Datenanalyse den Effekt des blinden Auswendiglernens, der schnell eintritt, wenn man „zu gut im Merken von Fakten“ ist (Modellkomplexität). Folgendes Beispiel veranschaulicht das:
Wenn Sie die Laufroute ihres davongelaufenen Hundes ermitteln wollen, dann folgen Sie seinen Pfotenabdrücken. Dies sind Ihre Daten. Wenn Sie Pfotenabdrücke sehen können, dann haben Sie viele Daten und haben kein Problem. Sind diese, etwa auf Straßenashpalt, nicht sichtbar, sehen sie vielleicht lediglich, dass ihr Hund hier und da sein Geschäft gemacht hat. Stellen Sie sich nun vor, sie wollen die Laufroute ihres Hundes durchs Dorf nachvollziehen. Sie finden eine Reihe Hundehaufen. Mit einer kilometerlangen Leine können Sie nun die Hinterlassenschaften nach Belieben verbinden. Im Grunde gibt es jedoch viele Varianten diese zu verbinden. Zuerst zum Dorfplatz und dann zur Marienstraße oder umgekehrt? Wo liegt dabei das Problem? Die Leine ist für die geringe Anzahl Haufen zu flexibel. Eine gerade Latte hingegen wäre zu starr, da Ihr Hund sicher mal nach links abgebogen ist, um zu schauen, ob beim Marktplatz vielleicht eine Scheibe Wurst abzustauben ist. Gute Methoden verwenden eine Leine, die immer starrer wird, je weniger Messpunkte sie haben.
In der Datenanalyse kommt noch ein weiteres Problem dazu. In unserem Beispiel wissen wir, dass die Hundehaufen nur auf dem zweidimensionalen Suchraum der Erdoberfläche zu finden sind. In der Datenanalyse bei Managementproblemen wissen wir im Vorhinein nicht, wo die Erde ist. Wir haben noch eine Reihe weiterer Koordinaten für jeden Haufen. Und je mehr Koordinaten wir haben, desto beliebiger können wir die Leine durchlegen. Darum muss der Mechanismus, der die Leine starrer macht, insbesondere danach trachten, mit wenigen Koordinaten auszukommen. So können diese Verfahren „die Erde“ finden und „Luftschlösser“ platzen lassen.
Das Rad nicht neu erfinden: Vorwissen einbringen
Vorwissen kann in vielen Bereichen eingebracht werden, ist aber auch gefährlich, wenn es in falsche Hände gelangt. Wenn wir wissen, dass nur ein oder zwei Faktoren wirklich relevant sind, müssen wir die anderen zehn oder zwanzig Faktoren nicht berücksichtigen. Auch damit wird das Modell erheblich bessere Ergebnisse liefern. Ist die Annahme jedoch falsch, können schwerwiegende Fehlerkenntnisse die Folge sein, wie wir oben am Beispiel der Scheinkorrelationen gesehen haben.
Eine weitere Methode, Vorwissen zu verwenden, ist die Gewichtung von Fällen. Wenn uns bekannt ist, dass 52 Prozent der Bevölkerung Männer sind, aber die Stichprobe nur 26 Prozent enthält, so müssen wir die Männer entsprechend übergewichten, damit die Ergebnisse auf die Realität anwendbar sind. Das sind nur einige von vielen Ebenen, in denen Vorwissen verwendet werden kann.
Mit der Anwendung herkömmlicher multivariater Methoden machen Sie automatisch viele Annahmen und bringen so unbewusst Vorwissen ein. Insbesondere nehmen Sie an, dass die Zusammenhänge linear und die Treiber voneinander unabhängig sind – um nur die wichtigsten Punkte zu nennen. Diese herkömmlichen Methoden liefern hervorragende Ergebnisse, wenn die postulierten Annahmen richtig sind. Wie ich oben dargestellt habe, ist dies leider nur selten gegeben.
Wenn also mit richtigem Vorwissen die Schätzung verbessert werden kann, so wird eine kleinere Stichprobe an Erfahrungswerten ausreichen, um zur gleichen Güte zu kommen. Je weniger Vorwissen vorhanden ist, desto mehr Erfahrungsdaten müssen sie erheben. Daher ist das Einbringen von Vorwissen nicht gut und nicht schlecht. Man muss sorgsam abwägen, wie viel man davon verwendet und vor allem sicher sein, dass das Vorwissen kein Irrtum ist.
Der Apfel fällt nicht weit vom Stamm: Hierarchical Bayes
Vorwissen kann auch aus anderen Datensätzen gezogen werden. Im Hierarchical-Bayes-Ansatz beeinflusst man die Analyse eines Datensatzes mit den Ergebnissen der Analyse eines anderen Datensatzes. Nehmen wir ein Beispiel: Studien von Banken zur Kundenzufriedenheit sollen meist die Kundenzufriedenheit und individuelle Treiber dieser Zufriedenheit für jede Filiale einzeln ausweisen. Wenn in 100 Filialen je 100 Kunden befragt werden, benötigt man 10.000 einzelne Erhebungen. Das kostet eine Stange Geld. Hinzu kommt, dass sich mit 100 Erfahrungswerten je Filiale nur sehr einfache Ursache-Wirkungs-Modelle aufsetzen lassen.
Wenn wir aber davon ausgehen, dass das, was einen Kunden in Filiale 1 zufrieden macht, grundsätzlich das Gleiche sein müsste, das den Kunden in Filiale 2 beglückt, dann könnte man Informationen von Filiale 2 borgen. So werden die Ergebnisse des Ursache-Wirkungs-Modells mit nur 100 befragten Kunden erheblich stabiler.
Den Wald trotz Bäumen sehen: Latente Variablen
Kundenzufriedenheit ist eine sogenannte „reflexive latente Variable“. Man kann sie nicht beobachten. Daher stellt man Indikatorfragen wie etwa: „Wie zufrieden sind Sie mit X?“ Da jeder Indikator nur bedingt misst, was Kundenzufriedenheit ausmacht, kann man noch andere Indikatorfragen stellen wie: „Wie bewerten Sie den Anbieter insgesamt?“ Ein reflexives Konstrukt findet eine Art gewichtetes Mittel aus den Indikatorvariablen. Der Vorteil ist, dass das Konstrukt besser misst, was es soll – in dem Fall die Kundenzufriedenheit. Wenn ein Konstrukt dies besser tut als ein einzelner Indikator, dann erreicht man mit einer kleineren Stichprobe die gleiche Güte wie mit einer größeren Stichprobe und nur einem Indikator.
Eine formative latente Variable ist der Versuch, Detailfragen zu einem größeren Ganzen zu komprimieren und damit die Anzahl der Variablen zu reduzieren. Zum Beispiel sind die Anzahl der konsumierten Einheiten von Bier, Wein oder Schnaps drei kausale Indikatoren für Trunkenheit. In einem formativen Konstrukt fasst man alle drei zur Vereinfachung des Modells zum Konstrukt „Trunkenheit“ zusammen.
Theoretisch benötigt ein Modell mit steigender Variablenanzahl exponentiell mehr Fälle (zum Glück ist es in der Praxis nicht ganz so dramatisch). In jedem Fall steigt jedoch der Stichprobenbedarf stärker als die Anzahl der Variablen. Mit zwei Ursachen-Variablen brauchen Sie mindestens 10-20 Fälle für sehr grundlegende Erkenntnisse. Bei 20 Ursachen-Variablen (also zehn Mal so viel) kommen Sie mit 100 Fällen kaum noch hin. Ich werde oft gefragt: „Wie viele Fälle brauchen wir denn?“ Diese Frage ist nicht einfach zu beantworten. Man kann gut eine Untergrenze angeben. Eine vernünftige Obergrenze gibt es jedoch nicht, da diese von der Komplexität des wahren Zusammenhangs abhängt. Ein linearer Zusammenhang braucht sehr viel weniger Daten als einer, in dem jede Variable mit jeder interagiert. Daher begrenzt man mit der Wahl der Stichprobengröße auch automatisch die Komplexität der möglichen Ergebnisse.
Im Chor klingt vieles besser: Der Multi-Target-Regression Trick
Wussten Sie, dass viele schlechte Sänger im Chor gut klingen? Mittelmäßige Sänger singen Songs mehrmals ein und legen die Tonspur einfach übereinander. Genauso einen Trick gibt es in der Ursachenanalyse auch. Benötigt werden verschiedene Zielgrößen, die durch ähnliche Treibergrößen beeinflusst werden. Wenn Sie also den Umsatz als Zielgröße haben, können Sie die Umsätze in Teilgebieten, Produktgruppen oder ähnliches heranziehen. Durch Vervielfältigung der Zielgrößen kommen Sie nun mit einem Bruchteil der Daten aus. So sind Ursache-Wirkungsmodelle möglich mit mehr Treibervariablen als Datensätze.
Methodisch gehen wir so vor: Die Multi-Target-Regression fasst in einem Zwischenschritt die Daten zu wenigen Komponenten zusammen, die quasi die gemeinsame Information der Zielvariablen reflektieren. Methodisch bewanderte Leser mögen einwenden, dass es sich hier lediglich um eine simple Faktoranalyse handelt. Nein, es ist genau das Gegenteil. Die Komponenten werde nicht mit der Maßgabe gebildet, die Treibervariablen gut zu komprimieren. Die einzige Maßgabe ist die Erklärungsgüte der Zielvariablen.
Ich habe die Methode an einer Befragung der Kunden der Success Drivers GmbH angewendet. Wir bekamen 22 Antworten. Geringe Fallzahlen sind ein typisches Problem im B2B-Geschäft. Aufgrund der Multitarget-Regression konnte ich 24 Treibervariablen verarbeiten.
Die Methode der Wahl muss effizient mit einer begrenzten Stichprobengröße umgehen können. Dazu sollte diese die Modellkomplexität mit der Anpassung an Daten abwägen, sie sollte ermöglichen, auf allen Ebenen Vorwissen einzubringen, Hierarchical Bayes umgesetzt haben, das Bilden von latenten Variablen unterstützen und eine Universelle Multi-Target-Regression anbieten.
Zusammengefasst sollten für das Management nützliche multivariate Ursachenanalyse folgende Anforderungen erfüllen. Sie sollten:
- Entdeckend vorgehen können
- Komplexität entdecken können
- mit kleinen Stichproben effizient umgehen können
Leider gab es bis dato keine Methode, die alle diese Kriterien erfüllt. Warum das bisher so war? Die Antwort: Die Lösung liegt nicht auf der Hand. Eine genauere Antwort ergibt sich aus den folgenden vier Fakten:
Erstens ist der mathematische Ansatz der heutigen herkömmlichen Methoden (Strukturgleichungsmodelle und andere) nur für bestätigende und nicht für die entdeckende Forschung geeignet. Eine Fortentwicklung auf Basis des gleichen Ansatzes ist schwer denkbar.
Weiterhin verfolgt die Mehrheit der Wissenschaftler, die sich mit Strukturgleichungsmodellen beschäftigen, einen bestätigenden (konfirmatorischen) Forschungsansatz. Sie erkennen eine Methode nicht an, die aus Datensätzen strukturelle Erkenntnisse gewinnt. Aus diesem Grund haben sich bislang auch nur wenige auf die Suche nach einer neuen Methodik gemacht.
Neue multivariate Methoden wie künstliche neuronale Netze sind erst in den letzten Jahren entwickelt worden. Künstliche neuronale Netze waren bislang für die Ursachenanalyse nicht geeignet, da diese am sogenannten Black-Box-Problem leiden: Sie liefern zwar eine höhere Erklärungskraft, machen jedoch nicht verständlich, wie sie zu diesem Ergebnis gekommen sind.
In den letzten fünfzehn Jahren ist es mir allerdings gelungen, eine Methode zu entwickeln und intensiv anzuwenden, die als erste den drei beschriebenen Bedingungen gerecht zu werden vermag. Ich habe die Methode Universal Structure Modeling und die Software dazu NEUSREL genannt.
Universal Structure Modeling und die Software NEUSREL
Ich hatte mich gerade im Wirtschaftsingenieurwesen für Elektrotechnik an der TU-Berlin eingeschrieben und der tägliche Gang durch die Mensa führte im Herbst 1993 am Raum des studentischen Börsenvereins vorbei. Dieser war eher eine Art riesiger Glaskasten und eine lokale Bank hatte einen Rechner mit Chartsoftware und Reuters-Terminal gesponsert. So konnten alle Interessierten am großen Monitor schnell mal die Kurse checken. Eines Mittags ließ ich von einem Vereinsmitglied dessen Handelssystem erklären. Er drehte an vielen Parametern und zeigte mir, dass man mit der richtigen Einstellung ordentlich Geld verdienen kann. Meine Gier war geweckt.
In der Folge trat ich dem Verein bei und stellte nach ersten Versuchen, ein eigenes Handelssystem zu erstellen, schnell fest, dass in der grundlegenden Heran-gehensweise, willkürliche Handelsalgorithmen an die Vergangenheit anzupassen, etwas faul war. Zeitgleich las ich etwas über künstliche neuronale Netze, die zu dieser Zeit aufgrund der Erfindung des Multi Layer Perceptrons 1986 einen Boom erlebten. Ihnen eilte der Ruf voraus, lernen zu können. Genau das brauchte man doch auch an der Börse: eine Art Superhirn, das die Unmengen an Börseninformationen zielgerichtet verarbeiten kann. Glücklicherweise traf ich im Börsenverein einen Gleichgesinnten, der auch von neuronalen Netzen begeistert war. Gemeinsam mit ihm frischte ich meine Programmierkenntnisse wieder auf, die ich in der Jugend ausreichend aufgebaut hatte.
Wir trafen uns regelmäßig, um zu forschen und ein eigenes Prognosemodell zu entwickeln, das alles bislang Dagewesene schlägt. Eine übermütige Idee für einen Zweitsemester. Aber uns war es egal. Es machte immensen Spaß. Und in der Tat kam in den ersten Jahren nicht viel an Zählbarem heraus, außer dass wir in hunderten durchforschten Nächten wirklich sehr viel über Methoden für das Lernen aus Daten lernten. 1999 launchten wir dann eine Prognoseplattform, die unsere Prognosen veröffentlichte und später verkaufte – mit nachgewiesenen hohen Trefferquoten seit Anbeginn.
Parallel nutzte ich die implementierten Algorithmen für künstliche neuronale Netze, um im Fach Personal in meiner Studienarbeit nachzuweisen, dass mit derartigen Methoden die Valenz-Instrumentalitäts-Erwartungs-Theorie überprüft werden kann. In der VIE-Theorie geht es um die Motivation von Mitarbeitern je nach deren aktuellem Umfeld und ihren Erwartungen.
Später, in meiner Diplomarbeit, verwendete ich diese Methoden, um im Produktions-prozess von Fiberoptik-Bauteilen schon nach einem, statt nach erst zwölf Messvorgängen festzustellen, ob ein Bauteil defekt ist. Damit konnte die Produktionskapazität bei Siemens deutlich gesteigert werden, da diese Messstationen der Flaschenhals der Produktion waren.
Ich saß in dieser Zeit in vielen Vorlesungen und dachte mir: „Das geht doch mit neuronalen Netzen viel besser.“ Es fing bei volkswirtschaftlichen Prognosen an, ging über Verfahren der Personalselektion, vorbei an Rohstoffpreisprognosen und Direktmarkting-Optimierungen bis hin zu Ursache-Wirkungs-Modellen in der Marketingforschung, die intensiv in der Vorlesung von Professor Volker Trommsdorff besprochen wurden. Durch ihn wurde die Idee für NEUSREL vorbereitet. „Warum sehe ich als kleiner Student so viele Möglichkeiten und die großen Professoren und die Profis in den Konzernen machen weiter mit ihren nachweisbar gefährlichen Methoden?“, fragte ich mich. Dass die reale Welt nicht immer nach neuen, besseren Dingen schreit, lernte ich erst später.
Die Idee zu NEUSREL schließlich habe ich Professor Klaus-Peter Wiedmann, meinem Doktorvater, zu verdanken. Bei der Suche nach einem Dissertationsthema kritzelte er in seiner unvergleichlichen Art wilde Ursache-Wirkungs-Beziehungen auf einen unser vielen Schmierzettel. Er meinte: „Neuronale Netze sind doch vernetzt – solche Ursachen-Netzwerke müsste man mit denen doch modellieren können!“ Ich wusste zwar, dass das nicht so geht, aber ich nahm die Frage als Herausforderung mit nach Hause. Der Grundstein zur Lösung war gelegt.
Warum ging es nicht? Künstliche neuronale Netze[3] (zumindest die gerichteten) werden heute lediglich als universelle, multivariate Regressionsverfahren verstanden. Sie ermitteln eine mathematische Formel (die aus den Neuronen besteht), welche aus den Inputvariablen bestmöglich die Werte der Outputvariable schätzt. Das einzige, für die Betriebswirtschaft gravierende, Problem neuronaler Netze war das sogenannte Black-Box-Problem. Die mathematische Formel war zu komplex, um sie verstehen zu können. Ein Kausalmodell, das perfekt prognostiziert, bei dem jedoch keiner sagen kann, welche Variable auf welche wie wirkt, ist in vielen Fällen einfach unbrauchbar. Daran musste ich arbeiten.
Das Ergebnis der weiteren zweijährigen Forschung war NEUSREL. Das Prinzip der Analysemethode ist in der folgenden Abbildung dargestellt. Grundsätzlich gibt es in NEUSREL drei Analysestufen.
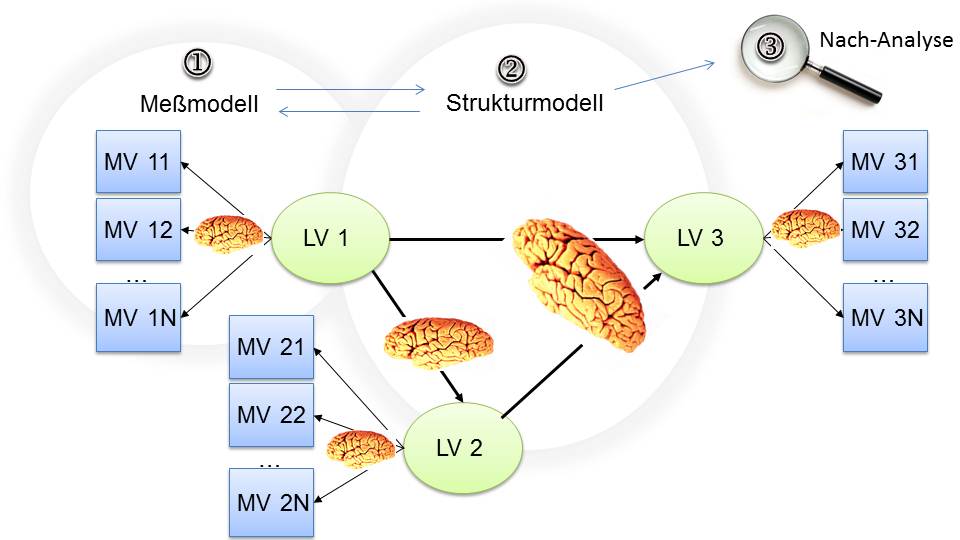
In Stufe 1 (das Messmodell) werden die reflexiven oder formativen latenten Variablen berechnet. Dabei werden sogenannte manifeste Variablen (MV), also die Werte, die im Datensatz vorhanden sind, zu einer latenten Variable (LV) verdichtet. Gibt es nur eine MV, so ist diese gleichzeitig die LV. Methodisch finden hier unter anderen Hauptkomponentenanalyseverfahren (HKA) Anwendung – wahlweise auch nichtlineare HKA, die durch neuronale Netze realisiert werden.
In Stufe 2 (das Strukturmodell) werden nun die Ursache-Wirkungs-Beziehungen modelliert. Für jede beeinflusste LV wird ein separates neuronales Netz angelernt. Diese neuronalen Netze produzieren wiederum eigene Schätzwerte für die LV, womit dann wieder das Messmodell optimiert werden kann. Iterativ werden Stufe 1 und Stufe 2 mehrfach wiederholt, wobei in der Wiederholung für Stufe 1 andere Methoden angewendet werden.[4]
In Stufe 3 findet die Nachanalyse statt. Denn das neuronale Modell ist Formel-Kauderwelsch. Dies muss erst in verständliche Informationshappen übersetzt werden. So wird etwa mit dem von Plate (1998) geliehenen Algorithmus, der unabhängige Einflüsse einer Variable auf eine andere separiert und graphisch dargestellt. Das Gleiche passiert mit dem Einfluss von zwei interagierenden Variablen auf eine beeinflusste Variable durch Erzeugen einer dreidimensionalen Landschaft.
Darüber hinaus wird eine Vielzahl von Kennzahlen berechnet, die genau die Eigenschaften der Zusammenhänge beschreiben. Wahlweise wird der Causal Direction Discovery-Algorithmus[5] in dieser Phase eingesetzt. Er stellt fest, ob bidirektional spezifizierte Pfade in Wahrheit eine ganz bestimmte Kausalrichtung aufweisen.
Lassen Sie uns prüfen, ob NEUSREL die oben aufgestellten Anforderungen erfüllt:
Zunächst: Ist NEUSREL eine multivariate Methode? Ja, künstliche neuronale Netze (KNN) sind multivariate Analysemethoden.
Betrachten wir nun die Anforderungen an ein wirkungsvolles Modell, die wir im Vorfeld beschrieben haben:
- Entdeckend vorgehen können: Ja, das Markenzeichen von KNN ist es, prinzipiell jeden möglichen Zusammenhang modellieren zu können, ohne seine Eigenschaften vorher zu kennen. Zusätzlich überprüft der Causal Direction Discovery-Algorithmus die Kausalrichtung.
- Komplexität entdecken können:
- Nichtlinearitäten:
Ja, das impliziert Punkt 1 bereits. Und hier liegt der große Unterschied zu manchen herkömmlichen Methoden, die ebenfalls Nichtlinearitäten modellieren. Bei KNN-Modellen muss man nicht vorher wissen, wo welche Art der Nichtlinearität vorliegt. Die spezielle Nachanalyse von NEUSREL ermöglicht das Auflösen der Black-Box neuronaler Netze. - Interaktionen:
Ja, und hier trifft wieder das Gleiche zu wie bei a. - Indirekte Effekte:
Ja, NEUSREL modelliert alle Pfade im Pfadmodell und berechnet nachträglich automatisch die totalen Effekte eines Treibers auf die Zielvariablen. - Mit kleinen Stichproben effizient umgehen können
- Modellkomplexität mit der Anpassung an Daten abwägen:
Ja, NEUSREL wendet eine Implementierung der Bayes’schen Statistik auf neuronale Netze, die durch MacKay entwickelt wurde, an. Meine Tests zeigen hervorragende Ergebnisse auch im Vergleich zu anderen neuen Methoden wie Support Vektor Machines und Gaussche Prozesse. - Möglichkeit auf allen Ebenen Vorwissen einzubringen:
Ja, NEUSREL ermöglicht Fallgewichtungen. Es ermöglicht Pfade a priori auszuschließen oder diese unter- oder überzugewichten. Zusammenhänge können darauf beschränkt werden, nur positiv zu sein (Constraints). Messmodell und Strukturmodell können auf Linearität begrenzt werden. Die Stichprobe kann so umgewichtet werden, dass eine Quasi-Gleichverteilung entsteht. Dem Lernverfahren kann auferlegt werden, Modelle mit besonders wenigen Freiheitsgraden zu bilden. - Hierarchical Bayes umgesetzt haben:
Ja, diese Methode ist in der Nachanalyse integriert. - Bilden von latenten Variablen unterstützen:
Ja, dies sind die Messmodelle. - Universelle Multi-Target-Regression:
Ja, mit NEUSREL möglich.
- Modellkomplexität mit der Anpassung an Daten abwägen:
In diesem Kapitel ging es um Ursachen-Mining für Manager. Ich habe Anforderungen hergeleitet, die an Methoden zu stellen sind, wenn man nützliche Ergebnisse für die Praxis produzieren möchte. Ich habe dargelegt, dass mit dem Universal Structure Modeling Ansatz und der NEUSREL Software erstmals eine Methode verfügbar ist, die den Anforderungen gerecht wird. Methodische Details können Sie in der Zusatzliteratur[6] vertiefen.
Mögliche Grenzen
Alles hat Grenzen. Die eierlegende Wollmilchsau gibt es nicht. Oft setzen wir uns aber auch mentale Grenzen selbst, die unter Umständen in dem Ausmaß nicht existieren, wie wir sie befürchten. Daher lassen Sie uns typische berechtigte Fragen näher betrachten.
Kann ich der vorgestellten Analysemethode wirklich vertrauen?
Die vorgestellte Methode zur Ursachenanalyse ist Hightech und hochkomplex. Dem Manager kann nicht zugemutet werden, im Detail zu verstehen, wie und warum die Methode wirklich funktioniert. Doch soll ein Manager Methoden anwenden lassen, die er nicht versteht? Soll er strategische Entscheidungen mit immensen Konsequenzen in Millionenhöhe durch Ergebnisse aus ihm unbekannten und unverständlichen Methoden begründen?
Um darauf eine ausgewogene Antwort zu finden, sollten wir uns als erstes die Alternativen des Managers bewusst machen. Das Anwenden verständlicher Methoden ist der Status-Quo – verständlich sind deskriptive Analysen. Ich habe hoffentlich deutlich zeigen können, dass die heutigen Entscheidungen auf Basis dieser Analysen zu regelmäßigen Fehlentscheidungen führen. Was können wir also verlieren? Schlechter können Entscheidungen durch innovative Methoden nicht werden – nur anders!
Als zweites schauen wir einmal, wie wir mit anderen komplexen Systemen umgehen, die wir nicht verstehen. Versteht ein Manager, wie sein PC funktioniert? Versteht der Manager einer Fluggesellschaft, warum genau ein Flugzeug in der Luft bleibt? Versteht ein Manager der Pharmaindustrie wirklich die bio-genetischen Forschungsprojekte und die Wirkung der daraus resultierenden Medikamente? Vertrauen in komplexe Systeme entsteht entweder durch wiederkehrend gute Erfahrungen oder durch Vertrauen in Experten, denen man aufgrund anderer Indizien und Erfahrungen vertraut.
Die vorgestellte Methode kann auf einen großen Fundus erfolgreicher Anwendungsprojekte zurückgreifen. Sie wurde zudem im wissenschaftlich führenden, referierten Journal veröffentlicht und von hochgradigen Experten geprüft. Vorsichtige Unternehmen starten erst einmal mit Pilotprojekten, um selbst Erfahrungen zu sammeln und Zug um Zug in die Anwendung einzusteigen.
Zu viele mögliche Erfolgsursachen
Manche Problemstellungen scheinen sehr komplex zu sein. Was beeinflusst beispielsweise den Erfolg einer Werbekampagne eines Automobilherstellers? Es fängt schon bei der richtigen Wahl der Kundensegmente und der Markenpositionierung darin an. Weiter geht es mit der Verteilung des Werbebudgets. Dann geht es in die Intramediaplanung. Hier gibt es Dutzende von Fernsehsendern und Zeitschriften, die zeitlich verschieden gesteuert und abgestimmt werden können. Dann kommt es darauf an, wie die Werbemittel (beispielsweise die TV-Spots) gemacht sind. Ist der kreative Ansatz wirkungsvoll? Wenn all das gut gemacht ist, dann … ja dann wird immer noch kein Auto gekauft. Zuerst muss das Ganze im Vertriebskanal richtig umgesetzt werden und es müssen sogenannte Touchpoints zum Kunden aufgebaut werden. Leicht zu sehen: Allein in diesem Beispiel gibt es vermutlich Hunderte oder gar Tausende von möglichen Hebeln, bis es zum erfolgreichen Absatz von PKW kommt. Das ist in dieser Form bei endlichen Datensätzen eventuell eine unlösbare Aufgabe.
Wäre es nicht ungemein nützlich, wenn wir die Aufgabenstellung so strukturieren, dass die Anzahl der Erfolgsursachen handhabbar wird? Und genau das muss das Ziel sein. Getreu dem lateinischen Motto „Teile und herrsche“, ist es eine erprobte Methode der Komplexitätsreduktion, ein Problem in Teilprobleme zu zerlegen und jedes nacheinander sequentiell zu lösen. So kann man im Beispiel zuerst die Kundensegmentierung und Brandpositionierung definieren, die ihrerseits dann den inhaltlichen Rahmen für den Kreativansatz vorgeben. Dieser ist grundsätzlich unabhängig von der Budgetverteilung auf Mediengattungen. Werbeformate wie Plakate oder TV-Spots können isoliert getestet und optimiert werden. Die Intramediaplanung ist wiederum ein nachgelagertes Problem. Auch die Themen Vertrieb, Vertriebsunterstützung etc. sind weitere separierbare Optimierungsfelder. Jedes dieser Teilbereiche hat handhabbar viele mögliche Erfolgsfaktoren.
Sicher, im Einzelfall können es zu viele Erfolgsfaktoren werden. Bevor wir aber nicht die diversen Regeln der Kunst[7] angewendet haben, sollten wir nicht voreilig urteilen.
Zu große Wirkzeit
Die Zeit zwischen dem Umsetzen einer ursächlichen Maßnahme und dem Auftreten der Folgen nenne ich Wirkzeit. Wirkzeiten können im Management sehr lang sein – insbesondere wenn es um strategische Prozesse geht. Dann nämlich durchlaufen die Wirkprozesse viele Teilprozesse, die in der Summe lange dauern. Wenn wir das Automobilbeispiel aufgreifen, kann man ebenfalls große Wirkzeiten feststellen. Eine Imagekampagne wirkt über die Zeit sukzessive positiv auf das Markenimage. Doch werden dann gleich mehr Autos verkauft? Nein, denn so trivial es klingt: Zuerst muss ein Kunde ein neues Auto benötigen.
Kunden kaufen aber nur im Schnitt alle 6 Jahre ein Auto. Damit baut sich beim einzelnen Kunden eine Marke im Schnitt über 3 Jahre auf, bis diese Einfluss auf den Kaufakt haben kann. Hat man Wirkzeiten über mehrere Jahre, wird es sehr schwer, die Wirkung der Maßnahmen empirisch nachzuweisen. Denn man muss erst mehrere Jahre warten bis die ersten Erfahrungen eintrudeln. Und weiterhin muss man weitere Jahre warten, um genügend Erfahrungswerte zu sammeln. Ist man dann bereit zur Auswertung, haben sich ggf. bereits alle Rahmenbedingungen geändert, unter denen die Ableitungen anwendbar sind.
Aus diesem Grund muss es in vielen Fällen das Ziel sein, die Aufgabenstellung so zu strukturieren, dass sich die Wirkzeit der Erfolgsursachen verringert. Im Beispiel oben handhaben wir dies, indem wir Zwischen-Erfolgsgrößen definieren und messen. Die ersten Ziele von Werbung sind Bekanntheit, Sympathie und Markenimage und nicht Abverkauf. Dann analysieren wir in einem separaten Modell, wie diese und andere Zwischengrößen das Endziel des Abverkaufs beeinflussen.
Erst wenn man genau analysiert und versteht, WARUM die Wirkzeit so lang ist, wie sie ist, kann man den Wirkprozess zerlegen und verkürzen. Gelingt dies nicht, stößt man an Grenzen der Wissensgewinnung.
Hoher Aufwand der Datensammlung
Daten sammeln ist immer mit Aufwand verbunden. Insbesondere wenn der Nutzen noch unklar ist, wird die Budgetbegründung schwierig. Aufgrund von sprungfixen Kosten kann der Datengewinnungsaufwand insbesondere für kleinere Unternehmen prohibitiv teuer werden. In großen Unternehmen ist nach meiner Beobachtung der Aufwand der Datensammlung für wichtige Forschungsfelder fast immer lohnend und kosteneffizient. Was können Sie tun, um die Kosten so gering zu halten, dass sich der Aufwand lohnt? Hier einige Ansätze:
Datensammlung als Nebenprodukt eines Selbstmanagement- oder Controlling-Prozesses: Wenn Sie beispielsweise die Wirkung Ihrer Vertriebsunterstützungsaktivitäten analysieren möchten, müssen Sie tracken, wie viel Besuche Ihre Vetriebsmannschaft macht, wie viele Produktproben, Flyer oder Einladungen zum Abendessen diese verteilen. Das kann aufwändig sein. Strukturieren Sie diese Datenerhebung nicht als administrativen Prozess, sondern als Selbstmanagementprozess. Wenn ein Vertriebler eine Excelliste führt, um nicht zu vergessen, diese oder jene Produktprobe mitzunehmen oder diesen oder jenen Besuch durchzuführen, so ist zeitgleich die Aktion automatisch festgehalten und kann später analysiert werden. Viele Daten werden zu Controlling-Zwecken doppelt und dreifach erfasst. Schauen Sie genau hin und nutzen Sie stattdessen die administrative Arbeit doppelt und dreifach und nicht umgekehrt.
Anschluss an Benchmark-Monitoren: Wenn Sie eine Marktforschung machen wollen, fragen Sie sich, ob Ihre Mitbewerber oder andere Unternehmen der gleichen Branche diese nicht auch gebrauchen könnten. Dann ist es wahrscheinlich, dass Sie sich in einer gemeinsamen Studie zusammenschließen können. So können Sie sich die Kosten teilen. Dies ist bereits in vielen Bereichen üblich. Wichtig: Die besonders intelligente Analyse mit den richtigen, oben beschriebenen Methoden können Sie sich für sich selbst vorbehalten.
Monetarisierung des zu erwartenden Nutzens der Erkenntnisse: Machen Sie sich klar, was Sie durch besseres Wissen gewinnen. Stellen Sie sich vor, sie könnten von den 50 Prozent verschwendetem Werbebudget nur ein Zehntel retten. Bei einem Budget von 10 Mio. Euro pro Jahr ergibt das immerhin 500.000 Euro Einsparung pro Jahr. Behalten Sie das Budget gleich, haben Sie mehr Effekte. Bei einem Verhältnis von einem Werbeeuro zu fünf Euro Mehrgewinn-Effekt, erzielen Sie bei konstantem Budget 2,5 Mio. Euro Mehrgewinn in jedem Jahr. Dafür lohnt es sich schon, Daten zu sammeln und auszuwerten.
Analyseaufwand und -kosten
Nach einem Vortrag fragte mich kürzlich ein Zuhörer: „Muss ich jetzt ein paar Mathematiker einstellen?“ Hier spricht die Befürchtung vieler Manager, dass neue Kompetenzen neue Leute erfordern, was logischerweise zusätzliche Overhead-Kosten erzeugt. Ziel muss es aber sein, ohne zusätzliche Gemeinkosten und ohne die Bildung eines neuen Silos wie etwa einer Analyseabteilung auszukommen.
Und in der Tat ist dies weder nötig noch üblich. Gerade in der Anfangszeit ist in jedem Fall Outsourcing an Experten zu empfehlen. So wie es für unzählige andere Spezialthemen auch bereits heute schon umgesetzt wird. Werbeagenturen, Mediaplanungsagenturen, SAP-Berater Personalrecruiter, Rechts- und Steuerberater sind die verbreitetsten Beispiele, die fast jedes Unternehmen nutzt. Warum also keine Agentur für Ursachenanalysen?
Bleibt noch die Angst vor zu hohen Analysekosten. Der ganze Aufwand muss sich schließlich lohnen. Auch diese Befürchtung löst sich schnell auf. Denn die Analysekosten sind oft geringer als die Datensammlungskosten selbst. Zudem gibt Ihnen das Outsourcing an Experten die Möglichkeit, sich vorab im Projektangebot sowohl Kosten als auch den zu erwartenden Nutzen deutlich vorrechnen zu lassen. Erst dann müssen Sie entscheiden.
Kommunizieren an Dritte
Zentrale Bedeutung in großen Unternehmen besitzt das Kommunizieren von Ergeb-nissen an diverse interne Interessengruppen. So muss die Marktforschungsabteilung die Ergebnisse von Studie und Analyse so aufbereiten, dass die entsprechende Abteilung die richtigen Schlüsse ziehen kann. Diese Abteilung kann das Marketing sein – es kann aber auch die Technik sein, die gewisse Leistungs- und Produkt-eigenschaften daraufhin verändern muss. Je komplexer die Analyseergebnisse sind, desto schwieriger sind diese zu kommunizieren. Darin steckt eine wichtige Herausforderung. Hier könnte auch eine wichtige Ursache dafür begründet liegen, warum noch heute fast ausschließlich mit deskriptiven Analysen gearbeitet wird.
Ziel muss es jedoch sein, brauchbare Analysemethoden anzuwenden, um eben auch richtige Entscheidungen treffen zu können. Die Darstellung und Kommunikation muss angepasst und die Ergebnisse müssen adressatenbezogen vereinfacht werden. In wichtigen Fällen arbeite ich mit erfahrenen Wahrnehmungspsychologen zusammen, die helfen, die Erkenntnisse auf des Pudels Kern hin zu abstrahieren und noch verständlicher darzustellen.
Fragen Sie sich bei der Darstellung, welche Detailinformation entscheidungsrelevant ist? Alles Irrelevante kann weggelassen werden. Fachabteilungen müssen auch nicht zwingend die Methode verstehen – ebenso wie Manager die Methode nicht verstehen müssen. Das Verstehen kann man Akteuren überlassen, denen man vertraut. Denn am Ende zählen nur brauchbare und erfolgreiche Ergebnisse.
Ein Beispiel aus dem Mobilfunk: Hier haben wir diverse Tiefenanalysen regelmäßiger Befragungen zur Kundenloyalität durchgeführt. Als Ergebnis wurde genau eine Powerpoint-Ergebnisfolie je Fachbereich erstellt. Dies war unter anderem durch eine neu eingeführte Kennzahl, den ASE (Average Simulated Effect), möglich. Aufgrund von Nichtlinearitäten und Interaktionen ist es in komplexen Modellen nicht so einfach, die Bedeutung eines Treibers anzugeben, denn die Bedeutung hängt davon ab, wie der Treiber heute ausgeprägt ist. Der ASE wird durch eine einfache Simulation berechnet und beantwortet die wichtigste Frage eines Managers: „Wie steigert sich die Kundenbindung, wenn jeder der Befragten einen bestimmten Treiber etwas besser einschätzen würde?“ Die Kennzahl vereinfacht ein komplexes Modell auf die Beantwortung dieser entscheidungsrelevanten Frage. Einstein hätte es so formuliert: „Man sollte alles so einfach wie möglich machen. Aber nicht einfacher!“
An der Umsetzung scheitert es meistens
Wenn Sie die richtigen Erfolgstreiber identifiziert haben, heißt das leider noch nicht zwingend, dass die Organisation die richtigen Maßnahmen ableitet und dann auch umsetzt. Wenn Sie feststellen, dass ein besserer Service der zentrale Hebel ist, gibt es tausend Wege, dies zu interpretieren und umzusetzen.
Studien zeigen, dass 70 Prozent aller Unternehmensinitiativen scheitern. Warum? Was Sie benötigen, damit die ganze Mannschaft Aktionspläne gut und schnell umsetzt, ist echtes Commitment. Dieses entsteht aber weder durch Präsentation der von den Beratern erstellten Konzepte noch durch „gnädiges Befragen“ der Mitarbeiter nach deren Meinung, die dann doch nur halbherzig einfließt. Auch große Abteilungstreffen oder Strategietagungen tragen nicht entscheidend zum Commitment bei. Denn hier kommen nur wenige zu Wort – meistens der Chef.
Echtes Commitment kann nur entstehen, wenn die wichtigen Mitarbeiter wirklich in die Erarbeitung der Aktionspläne eingebunden sind. Doch das ist leicht dahingesagt, denn das Einverständnis eines jeden erhalten Sie nur dann, wenn es der Gruppe gelingt, einen Konsens zu finden. Das jedoch bedarf eines hohen Aufwandes für den gegenseitigen Austausch. In typischen Meetings bräuchten Sie Monate. Das Tagesgeschäft käme zum Erliegen.
Zum Glück gibt es auch hierfür eine Lösung. Steffort Beer konnte in seinen Arbeiten Anfang der 90er Jahre nachweisen, wie man den Kommunikationsaufwand für die Konsensbildung einer Gruppe zeitlich minimiert. Folgt man diesem mathematischen System, so können etwa 15 Kernpersonen innerhalb von zwei Tagen und 40 Personen innerhalb von dreieinhalb Tagen einen Konsens finden. Besonders effektiv daran ist, dass der Konsens in konkreten Aktionsplänen bis aufs „Wer, was, bis wann“ heruntergebrochen ist. Die Success Drivers GmbH hat vor einigen Jahren einen konkreten Prozess auf der Basis von Beers Theorie in die Praxis umgesetzt. Wir nennen den Prozess MOVE und erzielen regelmäßig überragende Ergebnisse damit. Weil MOVE lediglich einen Prozess darstellt, entsteht die Lösung vollkommen selbstorganisierend. Ein strenges Set an Regeln führt nicht nur zu höchster Effektivität, sondern wird von allen Teilnehmern als befreiend empfunden. Auf natürliche Weise werden „Vielredner“ und „Abschweifer“ eingefangen und auf den Pfad der Lösungsfindung zurückgeführt.
Ein Prozess wie MOVE (www.move-system.de) ist die ideale Ergänzung für die Umsetzung konkreter Analyseergebnisse.
[1]Dies sind u. a. ökonometrische Modelle, es sind nicht die herkömmliche Regressionsanalyse, Logistische Regression, Logit-Analyse, herkömmliche Strukturgleichungsmodelle (LSIREL, AMOS, PLS, EQS, Mplus, etc.) oder Varianzanalysen
[2]Dies sind u. a. sogenannte nicht- und semiparametrische Methoden, wie K-Nächste Nachbarn, Entscheidungsbäume, Künstliche Neuronale Netze (genauer Multi-Layer Perceptron) oder Support-Vektor-Maschinen, um die wichtigsten zu nennen.
[3]Mehr zu neuronalen Netzen finden Sie u. a. in meiner Dissertation „NEUSREL“ (Buckler, 2001)
[4]Die Methode ist detaillierter im MJRM Artikel dargestellt (Buckler/Hennig-Thurau 2008)
[5]Ein Whitepaper zum Causal Direction Discovery-Algorithmus kann beim Autor angefordert werden.
- Buckler, F. (2001): NEUSREL: Neuer Kausalanalyseansatz auf Basis Neuronaler Netze als Instrument der Marketingforschung, Göttingen.
- Buckler, F./Hennig-Thurau, T. (2008): Identifying Hidden Structures in Marketing’s Structural Models Through Universal Structure Modeling: An Explorative Neural Network Complement to LISREL and PLS, in: Marketing Journal of Research and Management, Vol. 2
- Buckler, F. (2011): New NEUSREL feature Causal Direction Discovery, Whitepaper
[7]Auch können Variablen ggf. durch formative Konstrukte zu latenten Variablen verdichtet werden.
KAPITEL 6
Umsetzen: Die Befreiung aus der Kennzahlen-Illusion
Wir haben Alltagsmythen kennengelernt und gesehen, dass die vermeintlich einfachsten Weisheiten oft falsche Mythen sind. Wir haben gesehen, dass die Ursache dahinter die Art und Weise unseres Lernens ist. Auf die meisten Dinge wirken mehrere Ursachen gleichzeitig. Man muss immer alle Ursachen gleichzeitig betrachten, um wirklich lernen zu können, welche Ursache welchen Einfluss hat. Entweder wir führen kontrollierte Experimente durch oder wir wenden gleich multivariate Ursachenanalysen an, die aus Datensätzen die gesuchten Erkenntnisse gewinnen können. Wir haben gesehen, wie diese Methoden in vielen Bereichen des Managements großen Nutzen stiften können. Darüber hinaus habe ich Ihnen die neue Methode NEUSREL vorgestellt, die bestens geeignet ist, die hohen Anforderungen der Praxis zu erfüllen.
Was nun? Kann ich daraus noch mehr lernen? Was nehme ich ganz konkret mit für die Umsetzung?
Aus der Sicht eines Angestellten
Als Angestellter sehe ich die Dinge etwas anders. Stark vereinfacht ist mein Bestreben, mein Einkommen zu maximieren und Status zu gewinnen, sprich: Karriere zu machen. Das kann ich, wenn ich Erfolge vorweisen kann. Daraus ergeben sich eine gute Reputation und Beförderungen.
Doch sind Erfolge nicht die kausalen Folgen der Handlungen des Mitarbeiters? Wie kann ich Erfolge als solche identifizieren? Genau: In den meisten Fällen geht es nicht, denn es laufen zu viele Maßnahmen und damit mögliche Ursachen parallel. Niemand wird meine Erfolge wirklich erkennen können.
Drei Jahre, nachdem ich eine neue Position übernahm, hatte sich der Gewinn unseres Vertriebsgebiets vervierfacht. Dumm, wie ich manchmal bin, gab ich meine Vermutung preis, dass ein Großteil auf externe Marktentwicklungen zurückzuführen ist. Ein politisch geschickter Angestellter beherrscht die Kunst des „Storytelling im Nachhinein“. Erfolge führt der Storyteller öffentlich auf gleichzeitige oder vorlaufende eigene Maßnahmen zurück. Dazu muss er immer und fortlaufend öffentlich Aktionen initiieren, um später im Glücksfall die Zuordnung machen zu können. Dabei kommt es nicht darauf an, dass in den Aktionen tatsächlich etwas umgesetzt wird. Die Kunst besteht darin, sich im Vorhinein immer alle Türen offen zu halten. Zusätzlich wird er Risiken stets öffentlich dokumentieren, auf die er sich im Fall eines Misserfolgs beziehen kann. „Ich hab immer gesagt, dass dies schwierig wird.“ Idealerweise nennt er dabei externe Faktoren, die dazwischen kommen können. „Wir werden unseren Gewinn durch Preissteigerungen verdreifachen. Es besteht jedoch das Risiko dass der Wettbewerber querschießt.“
Weiterhin hat es karrieretechnisch Sinn, in einen Job einzusteigen und die ersten positiven Ergebnisse angemessen zu feiern und gleichzeitig als Sprungbrett für einen internen oder externen Wechsel zu verwenden. Bewerbungsverfahren sind oberflächlich und kleine Lügen bzw. Übertreibungen fallen zu 99 Prozent nicht auf. Da ist es schlau, sich aus dem Staub zu machen, bevor die Hütte zusammenfällt. Schauen Sie sich einmal die typische Verweilzeit eines Jungmanagers in einem Konzern an. Das sind zwei bis maximal vier Jahre. Erfahrene Manager werden mir beipflichten. Es dauert mindestens ein bis zwei Jahre, um sich in eine neue Stelle einzufinden, aber dann drei bis fünf Jahre, bis gute Maßnahmen wirklich greifen und Wirkung zeigen. Schlaue Karrieristen nutzen die Blindheit des Arbeitgebers und bewerben sich nach oben weiter.
Sie finden das unmoralisch? Ich auch. Doch ich glaube, sehr viele handeln genau auf diese Weise. Eben das ist aber Folge, wenn die Führung nicht angemessen die Multikausalität berücksichtigt – wenn es keine Sensibilität dafür gibt, dass der Erfolg viele Väter hat.
Aus der Sicht eines Unternehmers
In großen Konzernen und vielen anderen Unternehmen gibt es keine Unternehmer mehr. Es gibt nur noch Angestellte. Diese sind entweder Idealisten, dann haben die
Eigentümer Glück, oder Karrieristen, dann treibt das Schiff des Unternehmens mehr oder weniger führerlos. Zumindest ist der Kapitän nur daran interessiert, seine eigene Haut zu retten. In börsennotierten Unternehmen ist das ein Riesenproblem. Da die Folgen von Maßnahmen mit bloßem Auge von außen nicht beurteilt werden können, stehen dem Scharlatan Tür und Tor offen. Wenn nicht von außen kontrolliert werden kann, ob Maßnahmen gut sind, dann kommt es eben nicht mehr darauf an, gute Entscheidungen zu treffen. Es kommt darauf an, a) schlechte Ergebnisse argumentativ vorzubereiten und abzusichern und b) auftretende Erfolge „richtig“ zu attribuieren und c) Misserfolge extern zu begründen.
Wenn die Angestellten also fehlgesteuert werden, wenn die Ursache-Wirkungs-Beziehungen nicht transparent sind, dann muss Transparenz her. Als Unternehmer sind Sie gut beraten, herauszufinden und zu überwachen, wo die zentralen Erfolgshebel in den Einzelbereichen liegen und ob die Manager diese auch aktiv managen.
Weiterhin ist es schlau, das Gehör zu schulen und Begründungsversuche kritisch zu hinterfragen. Wir Menschen haben immer eine Begründung parat. Wenn nicht, erfinden wir eine. Wissen Sie, warum Kriminalität in Stadtteilen mit hohem Migrantenanteil meist höher ist? Sehen sie? Sie haben sofort eine Antwort parat oder? Es ist ein Automatismus, der sich im Gehirn abspielt. Das hat auch seinen Sinn. Nur wird uns oft nicht klar, auf wie wackeligen Beinen unsere Hypothesen stehen. Denn die Kriminalitätsrate kann auch durch den bei Migranten höheren Jugendanteil kommen oder daher, dass Migranten oft aus bildungsärmeren Milieus stammen? Ich weiß es nicht – es ist nur ein anschauliches Beispiel, wie wir permanent Hypothesen generieren und leider auch intuitiv ganz fest an deren Richtigkeit glauben.
Was wir brauchen, ist eine Unternehmenskultur, die es zulässt, auch einmal keine fertige Meinung zu haben. Dazu trägt eine Weltsicht bei, die verstanden hat, dass die Dinge viele Ursachen haben und diese sich nicht durch ad hoc Hypothesen erschließen. Diese Weltsicht entwickelt sich nur schrittweise durch zielgerichtete Bildung, die der Unternehmensführer steuern kann.
Bildung: Jeder sollte dieses Buch lesen
In irgendeiner Form ist es wichtig zu kommunizieren, in welcher Weise man in Zukunft managen will. Dies gelingt umso besser, je mehr die Mitarbeiter das Konzept und das Warum verstanden haben. In jedem Fall sollte ein Diskurs mit den zentralen Führungskräften, denen diese intellektuelle Leistung zugetraut werden kann, geführt werden.
Die Folge wird sofort sein, dass das Methodenverständnis im Unternehmen steigt. Dies sollte dann durch Aufbau von detailliertem Methoden-Know-how gebündelt an bestimmten Stellen ergänzt werden. Denn egal, ob man Analysen selbst anfertigt oder durch externe Experten durchführen lässt: Das Unternehmen sollte den methodischen Hintergrund gut verstehen können.
Kultur: Umgang mit Wissen und Nichtwissen lernen
Heute genießen Experten große Anerkennung bei uns. Eine lange Erfahrung gilt als hohes Gut. Vor dem Hintergrund der Multikausalität sollten wir unsere Einschätzung bei den Experten in den Bereichen Management, Marketing und Vertrieb und Einkauf relativieren. Das bezieht Branchenexperten mit ein. In der Realität erwirbt ein Branchenexperte sein Wissen in den ersten maximal fünf Jahren und predigt die Erkenntnisse den Rest seines Lebens. Auch das weiß ich aus eigener Erfahrung, denn mir ging es nicht anders. In jedem Fall lernt man immer weniger dazu. Eine spätere Änderung der Anschauung ist nahezu ausgeschlossen.
Haben Sie sich mal gefragt, warum viele der größten Unternehmen der Welt wie Microsoft, Google oder Facebook von zwanzigjährigen „Milchgesichtern“ gegründet wurden? Wenn Expertenwissen so wichtig ist, warum entwickeln die Experten wie die angesehenen Professoren in Harvard oder INSEAD oder ihre hochrangigen Schüler nicht neue revolutionäre Geschäftsmodelle? Weil vorhandenes Wissen oft falsch, rein beschreibend oder nicht widerlegbar (also inhaltsleer) ist – auch und gerade in den „Eliteschulen“, in denen fragwürdige Managementlehren wie der Shareholder-Value-Ansatz entwickelt und propagiert wurden. Reputation ist alles. Vieles hier ist nur Schall und Rauch.
Wenn nun klar ist, dass die Experten ihr Wissen meist „manuell“, ohne zusätzliche Methoden erworben haben, sollten Sie gegenüber Experten eine gesunde Skepsis entwickeln. Vielleicht haben die Experten ja zufällige Kovariationen der Vergangenheit fehlinterpretiert, die sich jetzt als Wissen im Kopf festgesetzt haben. Leider fliegt falsches Wissen keineswegs auf. Denn die Dinge haben ja viele Ursachen und so kann jeder seine eigene Interpretation der Fakten stricken, wenn die Wahrheit nicht transparent ist.
Natürlich ist der Umkehrschluss nicht erlaubt. Experten sind im Zweifel, die besten Quellen, die wir haben. Wenn Ihnen jedoch etwas an der Expertenmeinung unschlüssig vorkommt, sollten Sie vor dem Hintergrund der neuen Erkenntnisse den Experten herausfordern oder eine eigene Analyse angehen.
Bestehendes Management-, Markt-, Branchen-, Marketing- und Vertriebs-Know-how ist immer mit großer Vorsicht zu genießen. Sie wissen nie, wie es gewonnen wurde. Mit hoher Wahrscheinlichkeit kommen viele Weisheiten aus dem Land der Mythen. Als ich einen Job als Marketing-Manager aufnahm, stieß ich immer wieder auf diese Glaubenssätze. Kurze Auftragsdellen wurden grundsätzlich mit Saisoneffekten begründet. Ich konnte quantitativ nachweisen, dass es diese einfach nicht gibt und Schwankungen nur auf die Anzahl der Arbeitstage im Monat zurückzuführen waren. Ein anderer Glaubenssatz war es, dass alle Kunden nur auf den Preis schauen. Es stellte sich heraus, dass es diese Verallgemeinerung nicht gibt, sondern typische und natürliche Kundensegmente existieren.
Wichtiger als vermeintliches Wissen zu horten, ist es, eine Bestandsaufnahme darüber zu machen, was man NICHT weiß. Denn so wird deutlich, was vom Wissen noch übrig bleibt. Wenn ich weiß, welches Wissen fraglich ist, dann bin ich bei seiner Anwendung vorsichtiger. Und ich bin vorsichtiger, mögliche Erfolge diesen Maßnahmen zuzuschreiben. Eine Unternehmenskultur, die es zu sagen ermöglicht: „Ich weiß es nicht“, ist eine Kultur, die ein Bewusstsein darüber hat, was wir alles nicht wissen. Eine solche Unternehmenskultur produziert verantwortliche und ausgewogene Entscheidungen.
Eine Unternehmenskultur, die Nichtwissen toleriert und aushält, ist aus einem weiteren Grund notwendig. Vielleicht erinnern Sie sich noch an diese Matrix:
Sie zeigt den Blind-Spot der möglichen Erkenntnis. Hochkomplexe Systeme entziehen sich unserer Erkenntnis. Zumindest so lange, wie wir ihre Komplexität nicht (durch kreative Lösungen) sinnvoll verringern können. Das ist so wie mit den Wetterprognosen. Das globale Klima ist unendlich komplex. Jedoch ist es möglich, mit gutem Erfolg das morgige lokale Wetter vorherzusagen. Genauso gibt es Felder im Management, die bislang zu komplex sind, um empirisches Wissen ableiten zu können. Hier bleibt nur vorsichtiges Trial & Error.
In seinem Buch „Black Swan“ beschreibt Nassin Taleb sehr anschaulich, warum das aktive Management von Nichtwissen (des Blind-Spots) eine überlebenswichtige Rolle für Unternehmen spielt. Stellen Sie sich vor, Sie sind ein Truthahn und jeden Morgen gibt es Sonne satt und tolles Kraftfutter. Nach 1000 Tagen ihres Lebens gelten Sie als Experte und halten Vorlesungen vor den jüngeren Truthähnen und berichten von Ihrer Theorie der Unendlichkeit der Welt. Denn das entspricht Ihren Erfahrungen. Am nächsten Tag ist Thanksgiving …
Je seltener ein Ereignis in der Vergangenheit vorkam, desto gravierender sind mögliche Konsequenzen. Dieses Ereignis nennt Taleb „Black Swan“. Die Hälfte aller Veränderungen im Aktienindex Standard & Poor’s 500 der letzten 50 Jahre sind in sage und schreibe 10 Tagen passiert. Soziale Systeme sind quasi sich selbst organisierende Einheiten und es ist nachweislich ein Grundgesetz, dass sie sich auf diese Weise verhalten. Was hat das mit Nichtwissen zu tun? Die wichtigsten zukünftigen Ereignisse werden wir nicht vorhersehen können. Warum ist das so? Weil die Ereignisse deswegen so große Effekte entfalten, weil sie keiner vorhersieht und sich keiner darauf einstellen kann. Irgendwann erwischt uns das System auf dem falschen Fuß.
Gegen die negativen Black Swans sollten wir uns ausreichend schützen. Und das geht eben gerade nicht mit Risk Management Systemen, die versuchen, das Risiko aus empirischen Daten zu lesen. Wahres Risiko lässt sich eben gerade nicht aus der Empirie belegen. Man sollte einfach gewappnet sein. Expect the Unexpected. Ein Unternehmen, das mit geringer Eigenkapitalquote operiert, ist zwar sehr erfolgreich, aber bei einer Windböe schnell weg vom Fenster. Genauso wie es Porsche 2008 passiert ist.
Wer positive Black Swans erwischen will, muss spielen und wetten. Ein Investment in das junge Startup Google 1998 war genau eine solche Wette. Man konnte es vorher nicht wissen. Daher gilt, je mehr verschiedene Wetten man abschließt, desto besser. Lieber sollten die Geldbeträge klein sein. Auch gilt, dass je verrückter die Wette, desto größer ist der absolute Gewinn. Ganz einfach, weil andere ja auch wetten. Und auf verrückte Wetten wettet halt keiner, weil es unwahrscheinlich klingt. Daher sind diese Wetten, wie man im Börsenjargon sagt, unterbewertet.
Was hat das mit Management zu tun? Denken Sie mal an Produktinnovationen. In vielen Unternehmen werden verrückte Ideen abgewürgt. Hat es mal eine in den Startup-Status geschafft, so wird nach kurzer Zeit der Geldhahn zugedreht, wenn nicht in den Anfangsjahren die Gewinne sprudeln. „Ich habs ja schon immer gewusst“, heißt es dann von überall. Das Beispiel von Nespresso ist dabei sehr anschaulich. Über zehn Jahre fristete das Projekt Nespresso im Nestle-Konzern ein verlustbringendes Schattendasein. Wussten Sie das? Kaum ein anderes Unternehmen hätte das so lange geduldet. Jetzt im Nachhinein, wo das Konzept fliegt, ist Nespresso ein gern genanntes Beispiel für die Eröffnung neuer Geschäftsfelder. Schnell wird es als „Blue Ocean“-Idee ausgerufen. Nein, nicht das retrograde Rekonstruieren von Erfolgsformeln für Innovationsmanagement ist zielführend, sondern das gesteuerte Wetten auf ungewöhnliche Projekte. Da diese Projekte unterbewertet sind, ist im Gesamtergebnis das Investment sehr lohnenswert.
Führt man die Maßnahmen zum Überstehen von negativen Black Swans und zum Nutzen von positiven zusammen, kommt man zu einer Gesamtstrategie: Das Fundament der Unternehmenstätigkeit sollte grundsolide, sehr sicher und mit doppeltem Boden ausgestattet sein. Nur verfügbares Spielgeld wird dann möglichst breit gestreut in möglichst verrückte Projekte gesteckt, von denen eines Tages eines „explodieren“ und die Zukunft der Firma definieren wird. So wie der Stiefelfabrikant Nokia zum Handyhersteller und Bill Gates zum reichsten Mann der Welt wurde. Das ist gemanagter Zufall.
„Hase und Igel“ 2.0: Performance Management umgestalten
In der Geschichte vom Hasen und dem Igel gewinnt der Igel das Rennen mit einem Trick. Er nutzt die Tatsache, dass das Rennen nur durch eine Ergebnisgröße gesteuert wird: „Wer zuerst da ist, hat gewonnen.“
Die Zielgrößen im Management haben viele Ursachen. Und wie diese wirken, können wir durch KPIs, schicke Reportings oder elaborierte Excel-Listen nicht herausfinden. Doch wie findet Kontrolle und Performance Management heute statt? Man schaut sich einfach an, ob die KPIs im Soll liegen. Wenn nicht, wird beim Verantwortlichen nachgefragt in der Hoffnung, er kennt den Grund für die Abweichung. Aber woher soll er es denn wissen? Wenn die Dinge viele Ursachen haben und deren Wirkung eben nicht durch einfaches Beobachten erlebt werden kann, dann weiß er es im Zweifel auch nicht.
Wir merken davon nichts, weil die Verantwortlichen meist plausible Geschichten parat haben. Und sie lügen nicht wirklich, denn Sie glauben selbst daran, weil das
Bewusstsein für die Komplexität unserer Welt fehlt. Doch selbst, wenn eine Ahnung besteht: In den meisten Unternehmen fehlen die Methoden, dieser Komplexität erhellend zu Leibe zu rücken.
Es kommt allerdings noch schlimmer. Mitarbeiter und Manager werden nicht nur an den KPIs gemessen, sondern auch danach bezahlt. Bonussysteme orientieren sich meistens an Ergebniskennzahlen. Es soll belohnt werden, was geleistet wurde. Darunter versteht man, dass Erfolg belohnt werden soll.
Wenn aber die Kennzahl nur zum Teil vom Verantwortlichen beeinflusst werden kann und zudem dieser gar nicht präzise weiß, was die Haupterfolgstreiber sind, dann belohnt und bestraft man auf quasi zufälliger Basis. Eine Verstärkung von gutem und richtigem Verhalten kann so nicht funktionieren. Das Einzige, was man verstärkt, sind regelmäßige Maßnahmen zum Kennzahlen-Trimming. Der Igel fängt an zu tricksen. In schlechten Jahren werden Aufträge verschoben, damit es im nächsten Jahr Bonus regnet. Das Budget-Soll wird mit sagenumwobenen Storys niedrig gehalten. Manager kennen diese Dinge nur zu gut.
Wie geht es besser? Im Grunde darf man nicht den Output, also die Ergebnisse, kontrollieren, sondern den Input. Das Steuern des Inputs macht natürlich nur Sinn, wenn man die richtigen Erfolgsgrößen steuert. In einem Geschäft, in dem Face-Time beim Kunden zentral ist, sollten Sie diese auch messen und unter anderem Mindestgrößen definieren. In einem Geschäft, in dem die Fähigkeit zählt, gute Beziehungen zu Kunden aufzubauen, sollten Sie genau diese Fähigkeit messen und fördern sowie deren Anwendung kontrollieren.
Kontrolle ist hier immer im positiven Sinn gemeint und hat nichts mit einer Kultur des Misstrauens zu tun. Ein Unternehmen ohne Kontrolle funktioniert in den seltensten Fällen ausreichend gut. Kontrolle ist hier im Sinne von Coaching und „Hilfe, besser zu werden“ gemeint. Angemessene Kontrolle ist ein Beleg dafür, dass der Vorgesetzte sich für das interessiert, was der Angestellte tut. Es ist eine Art Anerkennung und Wertschätzung seiner Arbeit.
Ich war lange Zeit Befürworter der Output-Orientierung. Denn oft genug werden in
Unternehmen belanglose Inputfaktoren kontrolliert. Das offensichtlichste Beispiel sind die Arbeitsstunden. Für Fabrikarbeiter sind diese natürlich ein zentraler Erfolgsfaktor. Bei Managern und vielen Büroangestellten sagt die Arbeitszeit fast nichts über die Leistung aus. Daher schien es mir richtig, auf Ergebnisse zu schauen. Tatsächlich aber ist die Inputorientierung der bessere Weg. Nur muss man die richtigen Inputfaktoren managen. Diese findet man nur durch multivariate Ursachenanalyse-Methoden (insb. NEUSREL) und ggf. fundiert durch Experimente heraus.
Richtiges und gutes Performance Management bzw. Controlling setzt also an den zentralen Erfolgsfaktoren an. Wir brauchen keine Key Performance Indicators (KPIs), sondern Key Drivers Indicators (KDI). Dafür muss man im ersten Schritt erst einmal die wichtigsten Erfolgsfaktoren identifizieren.
Wenn Sie Ihr Performance Management und Controlling ernsthaft verbessern wollen, müssen Sie so viele Reports wie möglich eliminieren, die nur Erfolgsgrößen zeigen. Heutige Controlling-Reports gehen aber über das Sinnvolle weit hinaus und bohren alles und jeden bis auf die Schraube auf – in der Illusion man könnte daraus Ursachen ableiten. Diese Reports verschlingen nicht nur wertvolle Ressourcen, zunächst beim Erstellen und später beim studieren, sie führen eben auch dazu, dass der Leser Fehlschlüsse daraus zieht. Daher ist die Vermeidung solchen, „Informationsmülls“ wertstiftend für das Unternehmen.
Hennen statt Eier zählen: Ursachenbezogene Aggregation von Transaktionsdaten
Natürlich sollte man wissen, wie es um die Profitabilität bestellt ist oder wie es um die Liquidität steht. Gewisse Regelschleifen sind unumgänglich und sinnvoll. Aber auch und gerade die Retrospektive ist hochinteressant: Warum ist denn der Gewinn eingebrochen? Interessanterweise bieten die heutigen KPI-basierten Systeme keine sinnvolle Antwort darauf.
Controller und Finanzmenschen sind Meister im Aufbereiten von Daten. Leider sind es immer nur Zahlen über Fakten, ohne Information darüber, wie sie zustande kommen. Der typische Controller schwebt genauso in einer Kontroll-Illusion wie der typische Manager. Objekt der Analyse sind meist Kennzahlen, die man in Bilanzen findet. Umsatz, Rohertrag, Deckungsbeitrag, Gewinn, aber auch Stückzahlen, Umsatz pro Stück (Durchschnittspreise) ggf. je Produktgruppe, Materialkosten, Produktions-kosten, Transportkosten, Administrationskosten, etc. All diese Kennzahlen sind Aggregate einzelner Transaktionen. Sie summieren sowohl einzelne Verkäufe auf als auch die einzelnen Dinge, die man dafür anschaffen musste – vom Bleistift bis zum Lohnscheck. Ursachen sind immer nur Maßnahmen. Aggregation besteht immer aus Summen von Maßnahmen – also von Ursachen. Summiert man die falschen Transaktionen zusammen, kann man aus den Aggregaten nicht mehr erkennen, welche Maßnahme zum Ergebnis geführt hat.
Nehmen wir den absoluten Gewinn einer Geschäftseinheit. Können Sie an der Veränderung des Durchschnittspreises, des Durchschnittsrohertrags, der Durchschnittskosten oder der Abverkaufsmengen erkennen, warum der Gewinn gestiegen oder gefallen ist? Die Antwort ist in meisten Fällen: Nein! In jedem Fall geben die Zahlen keine korrekten Hinweise über Ursachen. Denn ein gestiegener Durchschnittspreis beispielsweise kann viele Gründe haben. Haben Kunden vermehrt teure Produkte gekauft? Ist ein Großkunde mit geringeren Preisen weggebrochen?
Wenn ich mit Controllern über diese Probleme rede, wird klar, dass den meisten das Problem bewusst ist. Doch die Lösung wird in einem lapidaren „da müssen wir das Business, also Marketing, Vertrieb oder Produktion fragen. Die kennen die Ursachen“ gesehen. Aus meiner Erfahrung kann ich jedoch sagen: In den meisten Fällen kennen diese die Ursachen auch nicht. Denn es sind zu viele Maßnahmen und Einflüsse, um sie einfach so im Blick zu haben. Nur, kaum jemandem ist dies bewusst, da man immer auf eine Frage eine scheinbar plausible Antwort erhält.
Ein gutes Reporting aggregiert die Transaktionsdaten so, dass die Kennzahlen in der Tendenz gute Hinweise über Ursachen geben. Diese Auswertungsmethode möchte ich im Folgenden mit CAT (Causation-lead Aggregation of Transaction data) bezeichnen. Ein solches Reporting kann für das produzierende Gewerbe zum Beispiel folgende Kennzahlen beinhalten:
- Neue Artikel: Gewinnzuwachs durch im Vergleich zum Vergleichszeitraum von Kunden neu bestellte Artikel
- Verlorene Artikel: Gewinnverlust durch im Vergleich zum Vergleichszeitraum von Kunden nicht mehr bestellte Artikel (lost specs)
- Höhere Preise: Gewinnzuwachs dadurch, dass im Vergleichszeitraum erneut bestellte Artikel zu einem höheren Preis verkauft wurden
- Niedrigere Preise: Gewinnverlust dadurch, dass im Vergleichszeitraum erneut bestellte Artikel zu einem niedrigeren Preis verkauft wurden
- Materialkosten: Gewinnänderung dadurch, dass im Vergleich zum Vergleichszeitraum die Rohmaterialien zu einem anderen Preis eingekauft wurden
- Absatz: Gewinnänderung dadurch, dass im Vergleich zum Vergleichszeitraum die gleichen Artikel in geänderten Mengen geordert wurden
- Produktmix: Gewinnänderung dadurch, dass im Vergleich zum Vergleichszeitraum mehr/weniger von margenstarken Artikeln geordert wurden
Sicher muss man dies auf die Eigenarten des Geschäfts anpassen. Das Prinzip bleibt das gleiche. Das Aufbauen von Kennzahlen nach Maßgabe möglicher Ursachen bzw. durchgeführter Maßnahmen. Ursachen für Gewinnänderung sind in diesem Fall: Neue Artikel oder Kunden, verlorene Artikel oder Kunden, Absatzänderung bei Bestandskunden, Einkaufskostenänderungen, Preisänderung und Produktmix-änderung. Wenn Lohnkosten, Fixkosten, bestimmte Preiskomponenten oder die Größe des Materiallagerbestandes in Ihrem Geschäft eine große Rolle spielen, ist es sinnvoll, dafür entsprechende Kennzahlen zu entwickeln.
Die meisten der oben skizzierten Kennzahlen können nun leider nicht mehr in einfachen Excel-Sheets ermittelt werden. Eine Software zur Verarbeitung der Transaktionsdaten wird dafür notwendig. Glücklicherweise gibt es dafür Dienstleister.
Weiterhin ist es notwendig, jede Kennzahl, die eine (deskriptive) Aggregation von Ursachen darstellt, durch Angabe bestimmter Einzelursachen zu ergänzen. Denn es kann sein, dass der Gewinneinbruch durch einen einzigen Artikel oder einen einzelnen Kunden verursacht wurde. Eine Kennzahl verallgemeinert jedoch immer. Wer offenen Auges durch die Unternehmensrealität geht, wird festgestellt haben, dass sich das Pareto-Prinzip als Grundmuster in allen selbstorganisierenden Systemen wiederfinden lässt. Albert-László Barabási beweist in seinen Büchern „Bursts“ und „Linked“ sehr anschaulich, warum das so ist. Das Pareto-Prinzip nennt man in der Managementsprache auch das „80-20-Prinzip“. Es besagt, dass 20 Prozent der Ursachen 80 Prozent der Effekte fabrizieren. Natürlich sind es niemals genau 20 oder 80. Aber es ist frappierend, wie wiederkehrend das Muster ist, wie wenige Kunden für den Hauptteil des Gewinns verantwortlich sind und wie der Hauptteil der Kosten durch wenige Artikel entsteht.
Weil das so ist, hat es sich bewährt, jede CAT-Kennzahl durch das Auflisten der Top 5 oder Top 10 Einzelposten zu ergänzen. Auch wenn sie durch die Kennzahl wissen, dass fasst der gesamte Gewinnverlust auf gesenkte Preise zurückzuführen ist, wird schnell die Frage gestellt werden: „Auf welche Kunden oder auf welche Produkte ist dies insbesondere zurückzuführen?“ Die Abbildung oben zeigt ein Beispiel dafür. Durch Anklicken des „Weniger Absatz“-Balkens werden die fünf Kunden aufgelistet, auf die der größte DB-Rückgang durch gesunkenen Absatz zurückzuführen ist. Man sieht sehr schnell, dass diese fünf bereits 50 Prozent der gesamten Zahl erklären.
Work-out für Ihr Unternehmen: Strategien und Prozesse optimieren
Der zentrale Schritt für ein wirkungsvolles Management ist es, die Key Drivers, die für den Erfolg verantwortlich sind, zu identifizieren. Dies sollte man auf der Unternehmensebene genauso durchführen wie beispielsweise auf der Ebene der operativen Vertriebssteuerung.
Im Kapitel „Anwendungsfelder“ haben wir hier viele Beispiele kennengelernt. In welchem Bereich in Ihrem Unternehmen am meisten Optimierungspotenzial liegt, wird vom Einzelfall abhängen. In jedem Fall sollten Sie folgende Maßnahmen prüfen:
- Prüfen Sie PIMS, um Ihr Geschäftsmodell und Ihre Ausrichtung zu evaluieren und, falls erforderlich, zu korrigieren.
- Identifizieren Sie kaufentscheidende Erfolgsfaktoren der Kunden, um daraufhin Ihre Positionierung am Markt auf den Prüfstand zu stellen.
- Diese Analyse sollten sie auch dazu nutzen, um nach Kundensegmenten zu suchen oder ihre derzeitigen Segmente zu hinterfragen. Unterscheiden sich Ihre Segmente in den zentralen Erfolgstreibern wirklich signifikant? Ist ihr Kundenmanagement darauf abgestimmt?
- Überprüfen Sie nicht nur die kaufentscheidenden, sondern auch die Faktoren für den Wiederkauf sowie die Faktoren, die zu einer höheren Zahlungsbereitschaft führen. Damit passen Sie Kunden- und Produktmanagement sowie die Preispolitik an.
- Analog zum Kunden können all diese Analysen auch bzgl. der Mitarbeiter und der Lieferanten durchgeführt werden. Denn Lieferanten- und Personalmärkte sind ebenfalls Märkte – nur dass die Güter, die Sie anbieten, andere sind.
Anders als in den meisten Büchern empfohlen, macht es keinen Sinn, alles, was Sie tun, zu ändern, und schon gar nicht auf einmal. Ganz einfach, weil es zu aufwändig ist. Sie wären Jahre mit sich selbst beschäftigt, anstatt sich um den Kunden zu kümmern. Auch hier ist es ratsam, nach dem Pareto-Prinzip nur an einigen zentralen Stellen zu beginnen.
Es gilt abzuwägen, welche Baustellen Sie als erstes eröffnen und welche lieber erstmal nicht. Das Ergebnis dieser Bewertung sollte wieder ein Konsens innerhalb der Kernmannschaft sein, und die Organisation sollte durch dieses Commitment überzeugt ans Werk gehen können. Auch hier bietet der MOVE-Prozess den idealen Rahmen, um als Organisation erfolgreich das Reich der Kennzahlen-Illusion zu verlassen.
Elevator Pitch
Management bedeutet, soziale Systeme zielführend zu steuern. Im Management von Unternehmen gilt es insbesondere, die Kunden, die Mitarbeiter und die Lieferanten zielgerichtet zu lenken. Diese Systeme sind deshalb komplex, weil sie über ungemein viele beeinflussende Faktoren verfügen, die das Auffinden von tatsächlichen Ursachen stark erschweren. Herkömmliche Analysemethoden sind nicht geeignet, derartige Systeme verstehen und effektiv steuern zu können, da sie geradezu chronisch Scheinerkenntnisse liefern. Wenn Zielgrößen von vielen Ursachen beeinflusst werden, kann man ausschließlich mit multivariaten Ursachenanalysen ermitteln, wie sich diese Zielgrößen wirklich ansteuern lassen. Nur diese ausgefeilten Methoden können Scheinerkenntnisse vermeiden.
An wirkungsvolle multivariate Ursachenanalysen sind drei Anforderungen zu stellen: Erstens sollten die Methoden entdeckend vorgehen können, da in der Praxis in aller Regel kein umfangreiches Vorwissen vorhanden ist. Zweitens sollten die Methoden Komplexität entdecken können, weil die Realität nichtlinear ist und Größen in ihrer Wirkung interagieren. Zudem sollte eine Ursachenanalyse immer die indirekten Pfade berücksichtigen, da andernfalls nicht der Gesamteffekt eines Treibers erfasst werden kann. Drittens sollte die Methoden mit kleinen Stichproben effizient umgehen können, denn in der Realität sind Stichproben fast immer zu klein.
NEUSREL ist der erste Methodenverbund, der all diesen Anforderungen wirklich gerecht wird, und ist deshalb die Methode der Wahl für nützliche Analyseergebnisse.
Für die Umsetzung der Analyseergebnisse benötigen Sie neben der Entwicklung konkreter Maßnahmen, ein starkes, auf Konsens beruhendes Commitment der umsetzenden Mitarbeiter. Einen praktikablen, weil effizienten Prozess dafür bietet nur das MOVE-System.
Zur Umsetzung gehört unter Umständen ebenso ein Umgestalten des Performance Managements und des Controllings. Steuern Sie nicht mehr mit KPIs (Key Performance Indicators) sondern mit KDIs (Key Driver Indicators). Die Kontrolle der Ist-Zahlen von Gewinn, Kosten oder Margen findet sinnvoller Weise mit der CAT-Methode (ursachenbasierte Aggregation von Transaktionsdaten) statt, da bestenfalls so abgeleitet werden kann, warum die ermittelten Zahlen so sind, wie sie sind.
In diesem Buch beschreibe ich keine noch nicht publizierten Erkenntnisse. Neu ist die Erkenntnis der bislang unerkannten Bedeutung, die adäquate Analysemethoden für erfolgreiches Management von Unternehmen besitzen.